Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
APPLICABILE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Data Factory in Microsoft Fabric è la nuova generazione di Azure Data Factory, con un'architettura più semplice, un'intelligenza artificiale predefinita e nuove funzionalità. Se non si ha familiarità con l'integrazione dei dati, iniziare con Fabric Data Factory. I carichi di lavoro di Azure Data Factory esistenti possono eseguire l'aggiornamento a Fabric per accedere a nuove funzionalità tra data science, analisi in tempo reale e creazione di report.
Azure Data Lake Storage Gen2 è un set di funzionalità dedicate all'analisi dei Big Data, integrate in Azure Blob Storage. Consente di interagire con i dati approfittando dei paradigmi sia del file system che dell'archiviazione di oggetti.
Azure Data Factory (ADF) è un servizio di integrazione dati completamente gestito basato sul cloud. È possibile usare il servizio per popolare il lake con i dati provenienti da un set completo di archivi dati locali e basati sul cloud e risparmiare tempo durante la compilazione di soluzioni di analisi. Per un elenco dettagliato di connettori supportati, vedere la tabella degli archivi dati supportati.
Azure Data Factory offre una soluzione di spostamento dei dati gestita con scalabilità orizzontale. ADF, grazie all'architettura scale-out, può inserire i dati a una velocità effettiva elevata. Per informazioni, vedere Prestazioni dell'attività di copia.
Questo articolo illustra come usare lo strumento Copia dati di Data Factory per caricare i dati dal servizio Servizi Web Diamazon S3 in Azure Data Lake Storage Gen2. È possibile seguire una procedura simile a quella usata per copiare dati da altri tipi di archivi dati.
Suggerimento
Per copiare dati da Azure Data Lake Storage Gen1 a Gen2, vedere questa procedura dettagliata specifica.
Prerequisiti
- Abbonamento Azure: se non si ha un abbonamento Azure, creare un account gratuito prima di iniziare.
- Azure Storage account con Data Lake Storage Gen2 abilitato: se non si dispone di un account di archiviazione, creare un account.
- Account AWS con un bucket S3 contenente dati: questo articolo illustra come copiare i dati da Amazon S3. È possibile usare altri archivi dati seguendo una procedura simile.
Creare una fabbrica di dati
Se non è ancora stata creata la data factory, seguire i passaggi descritti in Quickstart: Creare una data factory usando il portale di Azure e Azure Data Factory Studio per crearne uno. Dopo averla creata, passare alla Data Factory nel portale di Azure.
pagina principale di Azure Data Factory, con il riquadro Apri Azure Data Factory Studio.
Selezionare Apri nel riquadro Aprire Azure Data Factory Studio per avviare l'applicazione Integrazione dati in una scheda separata.
Caricare i dati su Azure Data Lake Storage Gen2
Nella home page di Azure Data Factory selezionare il riquadro Ingest per avviare lo strumento Copia dati.
Nella pagina Proprietà scegliere Attività di copia predefinita in Tipo di attività e scegliere Esegui una volta ora in Frequenza attività o pianificazione attività, quindi selezionare Avanti.

Nella pagina Archivio dati di origine completare la procedura seguente:
Selezionare + Nuova connessione. Selezionare Amazon S3 dalla raccolta di connettori e selezionare Continua.

Nella pagina Nuova connessione (Amazon S3) seguire questa procedura:
- Specificare il valore ID della chiave di accesso.
- Specificare il valore Chiave di accesso segreta.
- Selezionare Test connessione per convalidare le impostazioni e quindi selezionare Crea.

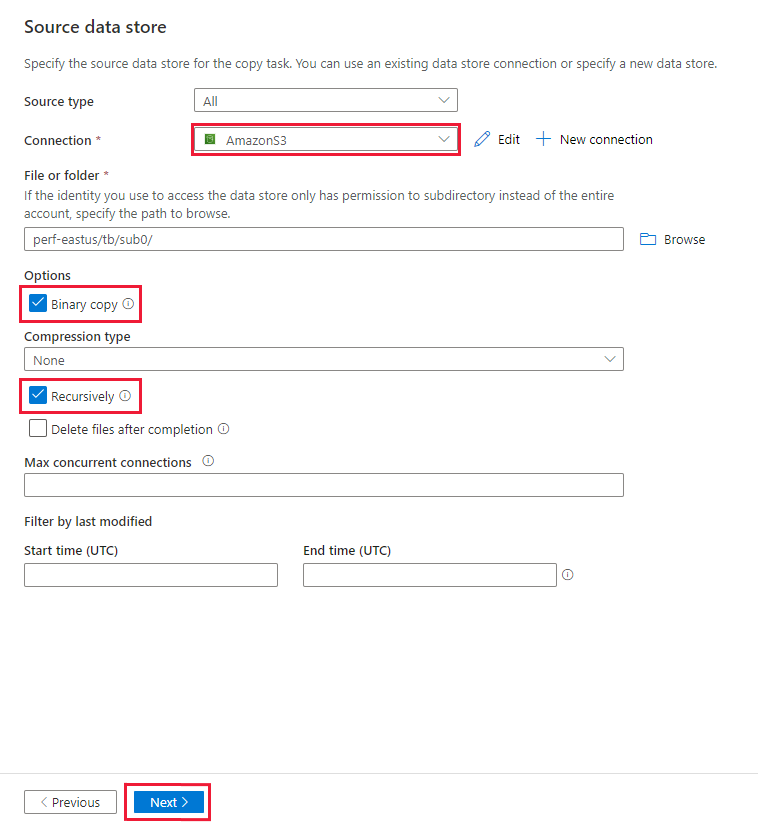
Nella pagina Archivio dati di origine verificare che la connessione Amazon S3 appena creata sia selezionata nel blocco Connessione.
Nella sezione File o cartella, navigare fino alla cartella e al file che desideri copiare. Selezionare la cartella o il file e quindi selezionare OK.
Specificare il comportamento di copia controllando le opzioni Copia ricorsiva eBinaria . Selezionare Avanti.
Nella pagina Archivio dati di destinazione completare la procedura seguente.
Selezionare + Nuova connessione e quindi selezionare Azure Data Lake Storage Gen2 e selezionare Continue.

Nella pagina Nuova connessione (Azure Data Lake Storage Gen2) selezionare l'account con supporto Data Lake Storage Gen2 dall'elenco a discesa "Nome account di archiviazione" e selezionare Crea per creare la connessione.

Nella pagina Archivio dati di destinazione selezionare la connessione appena creata nel blocco Connessione. Quindi, nel percorso della cartella immettere copyfroms3 come nome cartella di output e selezionare Avanti. Durante la copia, Azure Data Factory creerà il file system e le sottocartelle corrispondenti di ADLS Gen2, se non esiste.

Nella pagina Impostazioni specificare CopyFromAmazonS3ToADLS per il campo Nome attività e selezionare Avanti per usare le impostazioni predefinite.

Nella pagina Riepilogo esaminare le impostazioni e selezionare Avanti.

Nella pagina Distribuzione selezionare Monitoraggio per monitorare la pipeline (attività).
Al termine dell'esecuzione della pipeline, viene visualizzato un'esecuzione della pipeline attivata da un trigger manuale. È possibile usare i collegamenti nella colonna Nome pipeline per visualizzare i dettagli dell'attività ed eseguire di nuovo la pipeline.

Per visualizzare le esecuzioni di attività associate all'esecuzione della pipeline, selezionare il collegamento CopyFromAmazonS3ToADLS nella colonna Nome pipeline. Per informazioni dettagliate sull'operazione di copia, selezionare il collegamento Dettagli (icona a forma di occhiali) nella colonna Nome attività. È possibile monitorare i dettagli, ad esempio il volume di dati copiati dall'origine al sink, la velocità effettiva dei dati, i passaggi di esecuzione con la durata corrispondente e la configurazione usata.


Per aggiornare la visualizzazione, selezionare Aggiorna. Selezionare Tutte le esecuzioni della pipeline in alto per tornare alla vista "Esecuzioni della pipeline".
Verificare che i dati vengano copiati nell'account Data Lake Storage Gen2.
Contenuto correlato
- Panoramica dell'attività di copia
- connettore Azure Data Lake Storage Gen2