Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Content Understanding consente di creare flussi di lavoro di classificazione personalizzati che classificano il contenuto e lo instradano all'analizzatore corretto. Con il routing, è possibile inviare più flussi di dati attraverso la stessa pipeline e assicurarsi che i dati vengano elaborati dall'analizzatore migliore per il relativo tipo.
Questa guida illustra due passaggi:
- Creare un classificatore di base che classifica i documenti in categorie personalizzate.
- Classificare e instradare con analizzatori personalizzati che combinano la classificazione con l'estrazione dei campi per ogni categoria.
Prerequisiti
Per iniziare, assicurarsi di disporre delle risorse e delle autorizzazioni seguenti:
- Sottoscrizione Azure. Se non si ha una sottoscrizione Azure, creare un account gratuito.
- Una risorsa Microsoft Foundry nel portale di Azure creata in un'area supportata.
- Questa risorsa è elencata in Foundry>Foundry nel portale.
- Configurare le distribuzioni predefinite del modello per la risorsa Content Understanding. Impostando le impostazioni predefinite, si crea una connessione ai modelli Microsoft Foundry usati per le richieste di Comprensione contenuto. Scegliere uno dei metodi seguenti:
Passare alla pagina delle impostazioni di Content Understanding.
Selezionare il pulsante + Aggiungi risorsa in alto a sinistra.
Selezionare la risorsa Foundry che si vuole usare e selezionare Avanti>Salva.
Assicurarsi che la casella di controllo Abilita distribuzione automatica per i modelli necessari se non è selezionata alcuna impostazione predefinita . Questa selezione garantisce che la risorsa sia completamente configurata con i modelli necessari
GPT-4.1,GPT-4.1-minietext-embedding-3-large. Diversi analizzatori predefiniti richiedono modelli diversi.
- cURL installato per l'ambiente di sviluppo (per la scheda API REST).
Passaggio 1: Creare un classificatore di base
Un classificatore di base classifica i documenti in categorie di contenuto personalizzate. Le categorie vengono definite con nomi e descrizioni e il servizio usa tali definizioni per classificare i file di input. Il enableSegment parametro controlla se il classificatore suddivide i file multidocumenti in segmenti o considera l'intero file come un singolo documento.
Accedere a Content Understanding Studio
Passare al portale di Content Understanding Studio e accedere con le credenziali. Se si ha familiarità con l'esperienza classica Azure Document Intelligence in Foundry Tools Studio, Content Understanding estende lo stesso contenuto e l'estrazione dei campi in tutte le modalità, ovvero documento, immagine, video e audio. Selezionare l'opzione per provare la nuova esperienza Di comprensione del contenuto per accedere alle funzionalità multimodo.
Creare un progetto di classificatore
Iniziare con un nuovo progetto: selezionare Crea progetto nella home page.
Selezionare il tipo di progetto: selezionare l'opzione in
Classify and route with custom categories.Caricare i dati: caricare una parte di dati di esempio per iniziare a classificare.
Creare regole di routing: nella scheda Regole di routing selezionare
Add category. Assegnare alla categoria un nome e una descrizione. Per un classificatore di base, è possibile ignorare l'assegnazione di un analizzatore specifico a ogni categoria.Testare il flusso di lavoro di classificazione: quando le regole di routing personalizzate sono pronte per il test, selezionare Esegui analisi per visualizzare l'output delle regole sui dati.
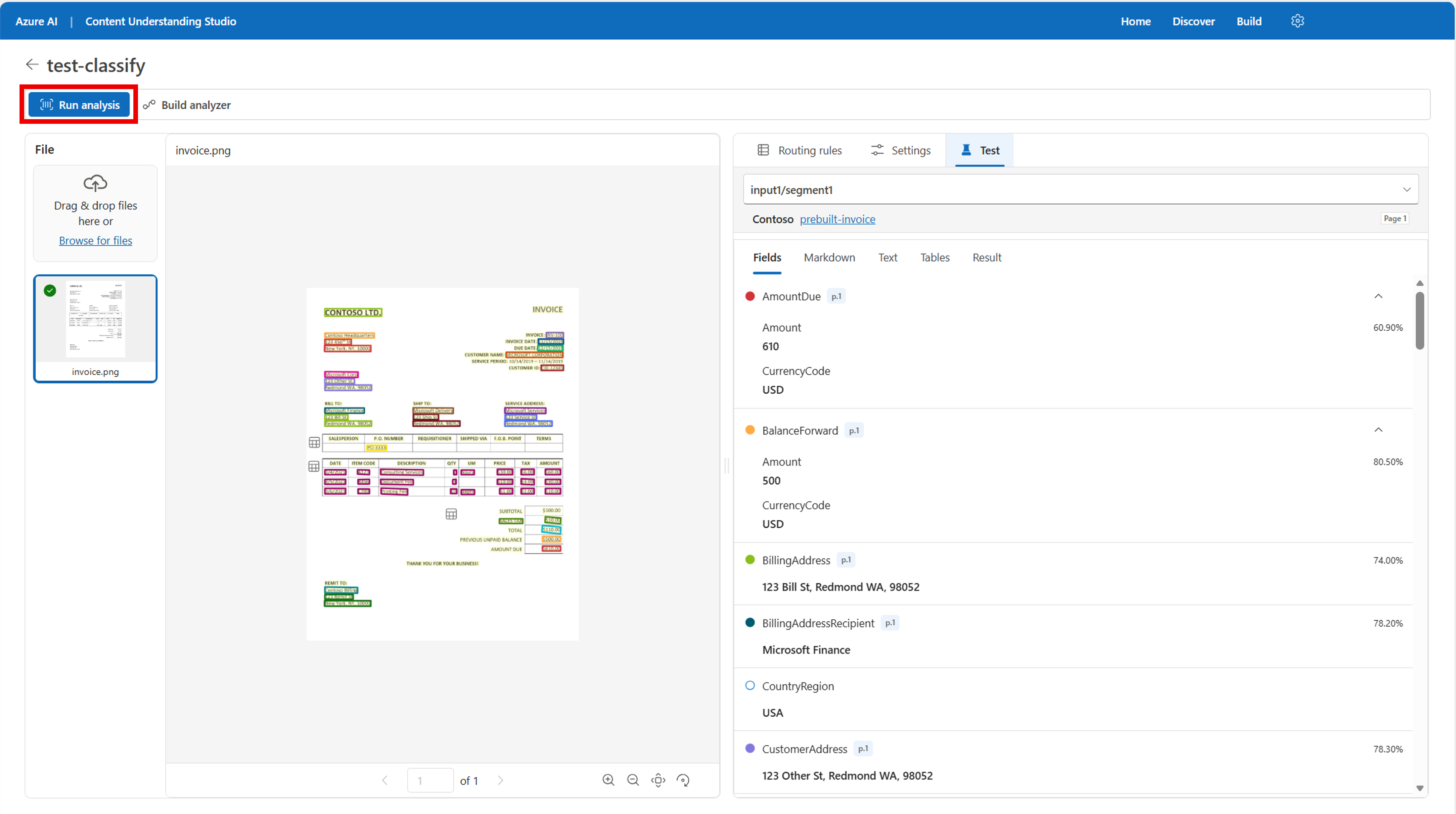
Compilare l'analizzatore di classificazione: quando si è soddisfatti dell'output, selezionare il pulsante Compila analizzatore nella parte superiore della pagina. Assegnare un nome all'analizzatore e selezionare Salva.

Passaggio 2: Classificare e instradare con analizzatori personalizzati
Per andare oltre la classificazione di base, è possibile instradare ogni categoria a un analizzatore specifico per l'estrazione dei campi. Questo approccio combina la classificazione con l'estrazione dei dati in una singola pipeline: il classificatore identifica il tipo di documento e quindi lo indirizza all'analizzatore corretto, che estrae i campi personalizzati per tale categoria.
Per indirizzare correttamente i dati, creare analizzatori personalizzati per ogni categoria. Per altre informazioni sulla creazione di analizzatori personalizzati, vedere Creare e migliorare l'analizzatore personalizzato in Content Understanding Studio.
Creare analizzatori personalizzati prima: creare analizzatori personalizzati per ogni tipo di documento che vuoi instradare. Ad esempio, creare un analizzatore personalizzato per le applicazioni di prestito con uno schema di estrazione dei campi specifico per quel tipo di documento.
Creare o aggiornare le regole di routing: nella scheda Regole di routing selezionare
Add category. Assegnare alla categoria un nome e una descrizione e selezionare un analizzatore per corrispondere a tale route. Lo strumento consente di visualizzare in anteprima lo schema per ogni analizzatore per assicurarsi di avere quello corretto.
Testare il flusso di lavoro di classificazione: selezionare Esegui analisi per visualizzare l'output delle regole sui dati. È possibile caricare dati di esempio aggiuntivi per i test per verificare le prestazioni con più regole diverse.
Compilare l'analizzatore di classificazione: quando si è soddisfatti dell'output, selezionare il pulsante Compila analizzatore nella parte superiore della pagina. Assegnare un nome all'analizzatore e selezionare Salva.
Usare l'analizzatore di classificazione: ora è disponibile un endpoint analizzatore che è possibile usare nella propria applicazione tramite l'API REST.

Suggerimento
Per un notebook Python end-to-end, vedere l'esempio di classificatore su GitHub.
Passaggi successivi
- Scopri di più sulle migliori pratiche per Azure Content Understanding in Foundry Tools.
- Seguire l'esercitazione per creare un analizzatore personalizzato usando le API REST.
- Esplorare i concetti del classificatore per scenari avanzati.