Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
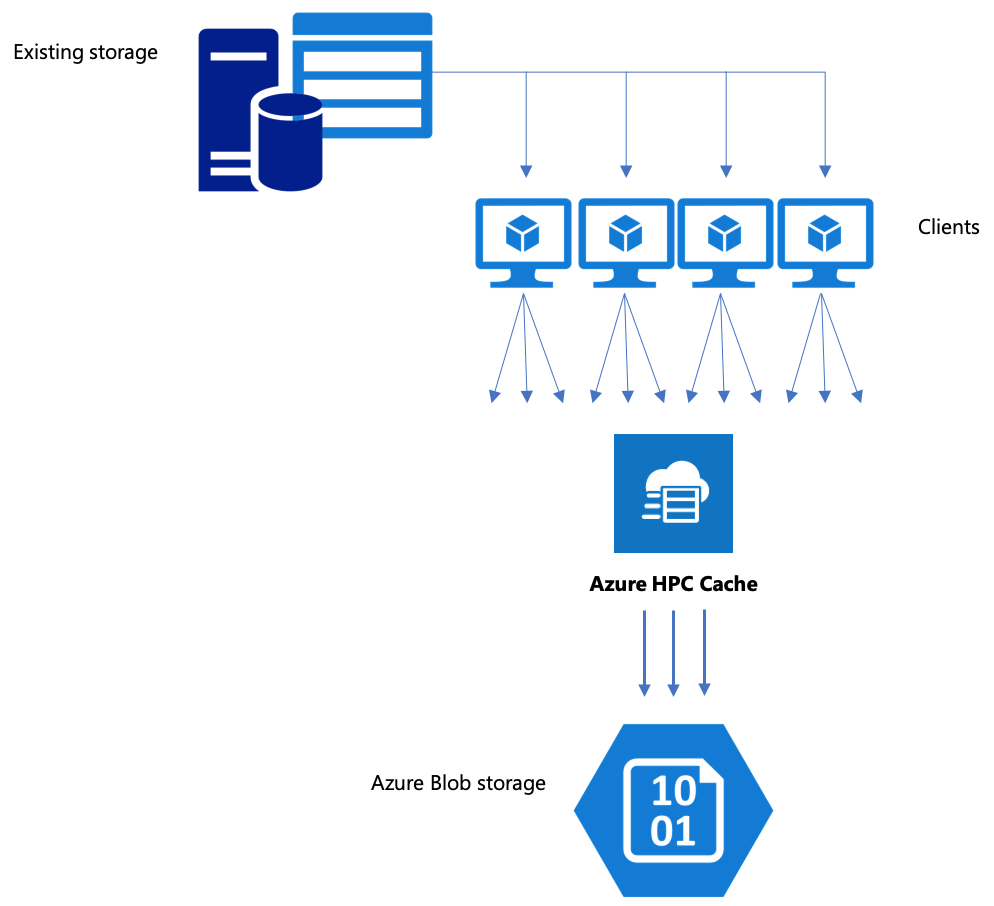
Si votre flux de travail inclut le déplacement de données vers le stockage Blob Azure, assurez-vous d’utiliser une stratégie efficace. Vous devez créer le cache, ajouter le conteneur d’objets blob en tant que cible de stockage, puis copier vos données à l’aide d’Azure HPC Cache.
Cet article explique les meilleures façons de déplacer des données vers le stockage d'objets blob pour utilisation avec Azure HPC Cache.
Tip
Cet article ne s’applique pas au stockage blob monté sur NFS (cibles de stockageADLS-NFS). Vous pouvez utiliser n’importe quelle méthode basée sur NFS pour remplir un conteneur d’objets blob ADLS-NFS avant ou après l’avoir ajouté au cache HPC. Pour en savoir plus , lisez les données de préchargement avec le protocole NFS .
Gardez ces faits à l’esprit :
Azure HPC Cache utilise un format de stockage spécialisé pour organiser les données dans le stockage d’objets blob. C’est pourquoi une cible de stockage d’objets blob doit être un nouveau conteneur vide ou un conteneur d’objets blob précédemment utilisé pour les données Azure HPC Cache.
La copie de données via Azure HPC Cache vers une cible de stockage back-end est plus efficace lorsque vous utilisez plusieurs clients et opérations parallèles. Une commande de copie simple d’un client déplace les données lentement.
Les stratégies décrites dans cet article fonctionnent pour remplir un conteneur d’objets blob vides ou pour ajouter des fichiers à une cible de stockage précédemment utilisée.
Copier des données via Azure HPC Cache
Azure HPC Cache est conçu pour servir plusieurs clients simultanément. Par conséquent, pour copier des données via le cache, vous devez utiliser des écritures parallèles à partir de plusieurs clients.
Les commandes cp et copy que vous utilisez généralement pour transférer des données d’un système de stockage vers un autre sont des processus à thread unique qui copient un seul fichier à la fois. Cela signifie que le serveur de fichiers n’ingère qu’un seul fichier à la fois, ce qui est un gaspillage des ressources du cache.
Cette section explique les stratégies de création d’un système de copie de fichiers multi-clientèle et multithreads pour déplacer des données vers le stockage Blob avec Azure HPC Cache. Il explique les concepts de transfert de fichiers et les points de décision qui peuvent être utilisés pour une copie efficace des données à l’aide de plusieurs clients et des commandes de copie simples.
Il explique également certains utilitaires qui peuvent vous aider. L’utilitaire msrsync peut être utilisé pour automatiser partiellement le processus de division d’un jeu de données en compartiments et à l’aide de commandes rsync. Le parallelcp script est un autre utilitaire qui lit le répertoire source et émet automatiquement des commandes de copie.
Planification stratégique
Lors de la création d’une stratégie pour copier des données en parallèle, vous devez comprendre les compromis en taille de fichier, en nombre de fichiers et en profondeur de répertoire.
- Lorsque les fichiers sont petits, la métrique d’intérêt est des fichiers par seconde.
- Lorsque les fichiers sont volumineux (10MiBi ou supérieur), la métrique d’intérêt est d’octets par seconde.
Chaque processus de copie a un débit et un taux de transfert de fichiers, qui peut être mesuré en minutant la longueur de la commande de copie et en factorisant la taille et le nombre de fichiers. Expliquer comment mesurer les taux est en dehors de l’étendue de ce document, mais il est impératif de comprendre si vous traiterez de petits fichiers ou volumineux.
Les stratégies d’ingestion de données parallèles avec Azure HPC Cache sont les suivantes :
Copie manuelle : vous pouvez créer manuellement une copie multithread sur un client en exécutant plusieurs commandes de copie en arrière-plan sur des ensembles prédéfinis de fichiers ou de chemins d’accès. Lisez ingestion de données Azure HPC Cache - méthode de copie manuelle pour obtenir plus d’informations.
La copie partiellement automatisée avec
msrsync-msrsyncest un utilitaire wrapper qui exécute plusieurs processus parallèlesrsync. Pour plus d’informations, lisez l’ingestion des données Azure HPC Cache - méthode msrsync.Copie par script avec
parallelcp- Découvrez comment créer et exécuter un script de copie parallèle dans l’ingestion de données Azure HPC Cache - méthode de script de copie parallèle.
Étapes suivantes
Après avoir configuré votre stockage, découvrez comment les clients peuvent monter le cache.