Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cette recette montre comment utiliser SynapseML et Foundry Tools, sur Apache Spark, pour la détection d’anomalies multivariées. La détection d’anomalies multivariées implique la détection d’anomalies entre de nombreuses variables ou séries chronologiques, tout en tenant compte de toutes les corrélations et dépendances entre les différentes variables. Ce scénario utilise SynapseML et Foundry Tools pour entraîner un modèle pour la détection d’anomalies multivariées. Vous utilisez ensuite le modèle pour déduire des anomalies multivariées au sein d’un jeu de données qui contient des mesures synthétiques à partir de trois capteurs IoT.
Important
À compter du 20 septembre 2023, vous ne pouvez pas créer de ressources Détecteur d’anomalies. Le service Détecteur d’anomalies prend sa retraite le 1er octobre 2026.
Pour plus d’informations sur la Azure AI Anomaly Detector, consultez la ressource d’informations Anomaly Detector.
Prérequis
- Un abonnement Azure - Create one gratuitement
- Attachez votre cahier à une cabane au bord du lac. Sur le côté gauche, sélectionnez Ajouter pour ajouter une maison de lac existante ou créer une maison de lac.
Programme d’installation
À partir d’une ressource existante Anomaly Detector , vous pouvez explorer des façons de gérer les données de différents formulaires.
Créer une ressource Détecteur d’anomalies
Note
Depuis le 20 septembre 2023, vous ne pouvez pas créer de ressources Détecteur d’anomalies. Les étapes suivantes s’appliquent uniquement si vous disposez d’une ressource Détecteur d’anomalies existante. Pour une approche de détection d’anomalies multivariée qui ne nécessite pas le service Détecteur d’anomalies, consultez Détection d’anomalie multivariée avec forêt d’isolation.
- Dans le portail Azure, sélectionnez Create dans votre groupe de ressources, puis tapez Anomaly Detector. Sélectionnez la ressource Détecteur d'anomalies.
- Nommez la ressource et utilisez idéalement la même région que le reste de votre groupe de ressources. Utilisez les options par défaut pour le reste, puis sélectionnez Vérifier + Créer, puis Créer.
- Après avoir créé la ressource Détecteur d’anomalies, ouvrez-la et sélectionnez le
Keys and Endpointspanneau dans le volet de navigation gauche. Copiez la clé de la ressource Détecteur d'anomalies dans la variable d’environnementANOMALY_API_KEYou stockez-la dans la variableanomalyKey.
Créer une ressource de compte de stockage
Pour enregistrer des données intermédiaires, vous devez créer un compte Azure Blob Storage. Dans ce compte de stockage, créez un conteneur pour stocker les données intermédiaires. Notez le nom du conteneur et copiez la connection string dans ce conteneur. Vous en avez besoin pour remplir ultérieurement la containerName variable et la variable d’environnement BLOB_CONNECTION_STRING .
Entrer vos clés de service
Tout d’abord, configurez les variables d’environnement pour vos clés de service. La cellule suivante définit les variables d’environnement ANOMALY_API_KEY et BLOB_CONNECTION_STRING, en fonction des valeurs stockées dans Azure Key Vault. Si vous exécutez ce tutoriel dans votre propre environnement, veillez à définir ces variables d’environnement avant de continuer :
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Lisez les variables d’environnement ANOMALY_API_KEY et BLOB_CONNECTION_STRING, puis définissez les variables containerName et location.
# An Anomaly Detector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Connectez-vous au compte de stockage afin que le détecteur d’anomalies puisse enregistrer des résultats intermédiaires dans ce compte de stockage :
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Importez tous les modules nécessaires :
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.services import *
Lisez les exemples de données dans un DataFrame Spark :
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
Vous pouvez maintenant créer un estimator objet que vous utilisez pour entraîner votre modèle. Spécifiez les heures de début et de fin des données d’entraînement. Spécifiez également les colonnes d’entrée à utiliser et le nom de la colonne qui contient les horodatages. Enfin, spécifiez le nombre de points de données à utiliser dans la fenêtre glissante de détection d’anomalies et définissez le connection string sur le compte Azure Blob Storage :
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Ajuster le estimator aux données :
model = estimator.fit(df)
Une fois l’entraînement terminé, utilisez le modèle pour l’inférence. Le code de la cellule suivante spécifie les heures de début et de fin des données dans lesquelles vous souhaitez détecter les anomalies :
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
Dans la cellule précédente, .show(5) affiche les cinq premières lignes de trame de données. Les résultats sont tous null parce qu’ils atterrissent en dehors de la fenêtre d’inférence.
Pour afficher les résultats uniquement pour les données déduites, sélectionnez les colonnes nécessaires. Vous pouvez ensuite classer les lignes dans le dataframe par ordre croissant et filtrer le résultat pour afficher uniquement les lignes de la plage de fenêtres d’inférence. Ici, inferenceEndTime correspond à la dernière ligne du dataframe, afin de pouvoir l’ignorer.
Enfin, pour mieux tracer les résultats, convertissez le dataframe Spark en dataframe Pandas :
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
Mettez en forme la colonne contributors qui stocke le score de contribution de chaque capteur pour les anomalies détectées. La cellule suivante gère cela et fractionne le score de contribution de chaque capteur en sa propre colonne :
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Vous avez maintenant les scores de contribution des capteurs 1, 2 et 3 dans les series_0colonnes , series_1et series_2 respectivement.
Pour tracer les résultats, exécutez la cellule suivante. Le minSeverity paramètre spécifie la gravité minimale des anomalies à tracer :
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
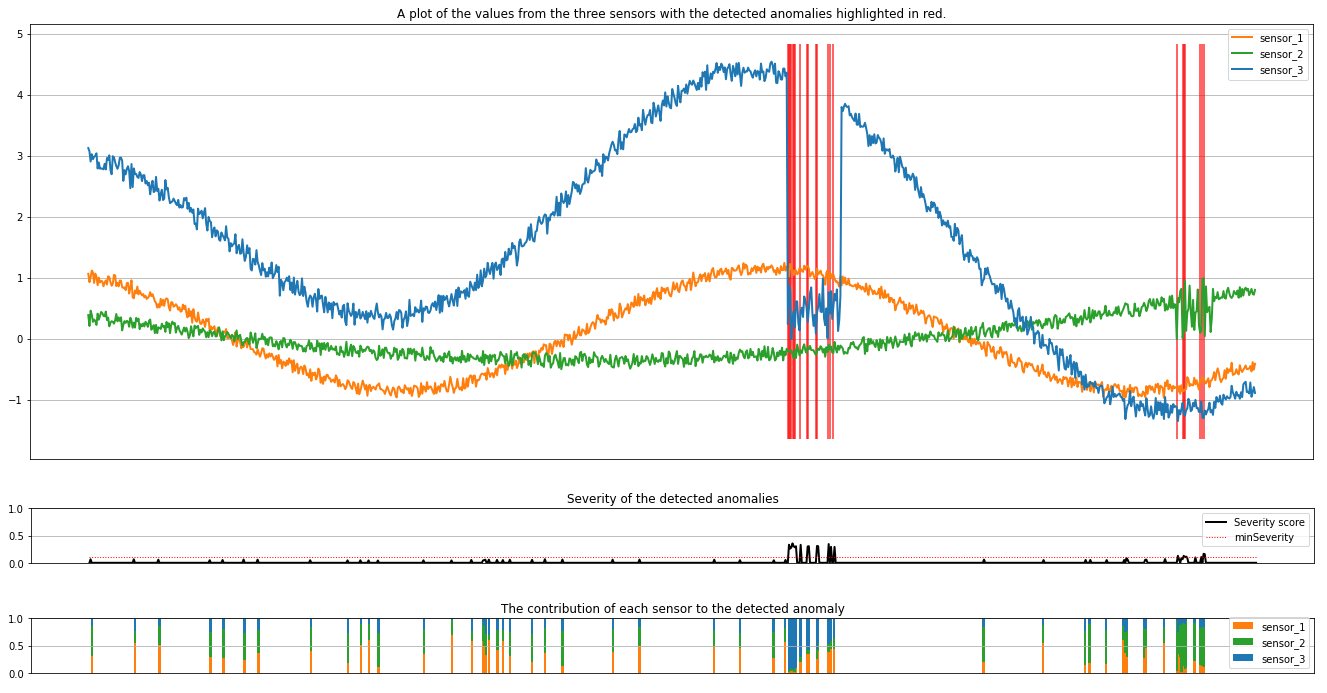
Les tracés affichent les données brutes des capteurs (à l’intérieur de la fenêtre d’inférence) en orange, vert et bleu. Les lignes verticales rouges de la première figure montrent les anomalies détectées dont la gravité est supérieure ou égale à minSeverity.
Le deuxième tracé montre le score de gravité de toutes les anomalies détectées, avec le seuil minSeverity indiqué sur la ligne rouge en pointillé.
Enfin, le dernier tracé montre la contribution des données de chaque capteur aux anomalies détectées. Il permet de diagnostiquer et de comprendre la cause la plus probable de chaque anomalie.
Contenu connexe
- Détection d'anomalies multivariées avec Isolation Forest – ne nécessite pas d'une ressource Azure AI Anomaly Detector.
- Comment utiliser LightGBM avec SynapseML
- Comment utiliser Foundry Tools avec SynapseML
- Comment utiliser SynapseML pour régler les hyperparamètres