Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Microsoft Fabric Data Warehouse est un entrepôt relationnel à l’échelle de l’entreprise sur une base de lac de données, avec une architecture future, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'entreposage de données, commencez par Fabric Data Warehouse. Les charges de travail de pool SQL existantes dédicées peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
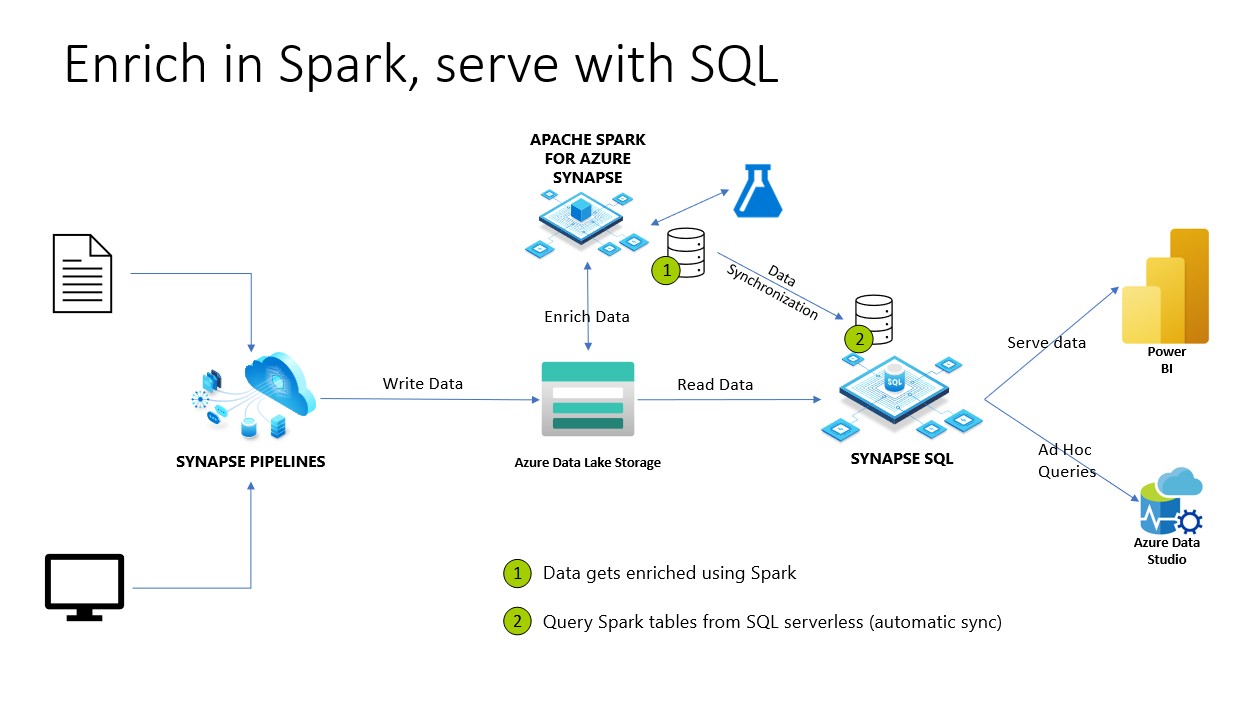
Dans Azure Synapse Analytics, Spark databases et tables sont partagés avec un pool SQL serverless. Les bases de données Lake, Parquet et les tables sauvegardées CSV créées avec Spark sont automatiquement disponibles dans le pool SQL serverless. Cette fonctionnalité permet d’utiliser un pool SQL serverless pour explorer et interroger les données préparées à l’aide de pools Spark. Dans le diagramme ci-dessous, vous pouvez voir une vue d’ensemble de l’architecture de haut niveau pour utiliser cette fonctionnalité. Tout d’abord, Azure Synapse Pipelines déplacent des données d’un stockage local (ou autre) vers Azure Data Lake Storage. Spark peut désormais enrichir les données et créer des bases de données et des tables qui sont synchronisées avec Synapse SQL serverless. Plus tard, l’utilisateur peut exécuter des requêtes ad hoc sur les données enrichies ou les servir à Power BI par exemple.
Accès administrateur complet(sysadmin)
Une fois ces bases de données et tables synchronisées de Spark vers un pool SQL serverless, ces tables externes dans le pool SQL serverless peuvent être utilisées pour accéder aux mêmes données. Toutefois, les objets du pool SQL sans serveur sont en lecture seule pour garantir la cohérence avec les objets des pools Spark. La limitation fait que seuls les utilisateurs possédant le rôle Administrateur Synapse SQL ou Administrateur Synapse peuvent accéder à ces objets dans un pool SQL serverless. Si un utilisateur non administrateur tente d’exécuter une requête sur la base de données/table synchronisée, il reçoit une erreur telle que :
External table '<table>' is not accessible because content of directory cannot be listed. malgré leur accès aux données sur le ou les comptes de stockage sous-jacents.
Étant donné que les bases de données synchronisées dans le pool SQL serverless sont en lecture seule, elles ne peuvent pas être modifiées. La création d’un utilisateur ou l’octroi d’autres autorisations échoue en cas de tentative. Pour lire les bases de données synchronisées, vous devez disposer d’autorisations au niveau du serveur privilégiées (comme sysadmin). Cette limitation est également présente sur les tables externes du pool SQL serverless lors de l’utilisation de tables Azure Synapse Link pour Dataverse et les tables de bases de données lake.
Accès non administrateur aux bases de données synchronisées
Un utilisateur qui a besoin de lire des données et de créer des rapports n’a généralement pas d’accès administrateur complet (sysadmin). Cet utilisateur est généralement analyste de données qui doit simplement lire et analyser des données à l’aide des tables existantes. Ils n’ont pas besoin de créer de nouveaux objets.
Un utilisateur disposant d’une autorisation minimale doit pouvoir :
- Se connecter à une base de données répliquée à partir de Spark
- Sélectionnez des données via des tables externes et accédez aux données ADLS sous-jacentes.
Après avoir exécuté le script de code ci-dessous, il permet aux utilisateurs non administrateurs de disposer d’autorisations au niveau du serveur pour se connecter à n’importe quelle base de données. Il permet également aux utilisateurs d’afficher les données de tous les objets au niveau du schéma, tels que les tables ou les vues. La sécurité de l’accès aux données peut être gérée sur la couche de stockage.
-- Creating Azure AD login (same can be achieved for Azure AD app)
CREATE LOGIN [login@contoso.com] FROM EXTERNAL PROVIDER;
go;
GRANT CONNECT ANY DATABASE to [login@contoso.com];
GRANT SELECT ALL USER SECURABLES to [login@contoso.com];
GO;
Note
Ces instructions doivent être exécutées sur la base de données master, car il s’agit de toutes les autorisations au niveau du serveur.
Après avoir créé une connexion et accordé des autorisations, les utilisateurs peuvent exécuter des requêtes sur les tables externes synchronisées. Cette atténuation s'applique également aux groupes de sécurité Microsoft Entra.
Vous pouvez gérer davantage de sécurité sur les objets via des schémas spécifiques et verrouiller l’accès à un schéma spécifique. La solution de contournement nécessite un DDL supplémentaire. Pour ce scénario, vous pouvez créer une base de données, des schémas et des vues serverless qui pointeront vers les données des tables Spark sur ADLS.
L’accès aux données du compte de stockage peut être géré via ACL ou des rôles standard Storage Blob Data Owner/Reader/Contributor pour les utilisateurs/groupes Microsoft Entra. Pour les entités de service (applications Microsoft Entra), veillez à utiliser la configuration ACL.
Note
- Si vous souhaitez interdire l’utilisation d’OPENROWSET sur les données, vous pouvez utiliser
DENY ADMINISTER BULK OPERATIONS to [login@contoso.com];Pour plus d’informations, consultez REFUSER les autorisations du serveur. - Si vous souhaitez interdire l’utilisation de schémas spécifiques, vous pouvez utiliser
DENY SELECT ON SCHEMA::[schema_name] TO [login@contoso.com];Pour plus d’informations, consultez REFUSER les autorisations de schéma.
Étapes suivantes
Pour plus d’informations, consultez Authentification SQL.