Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
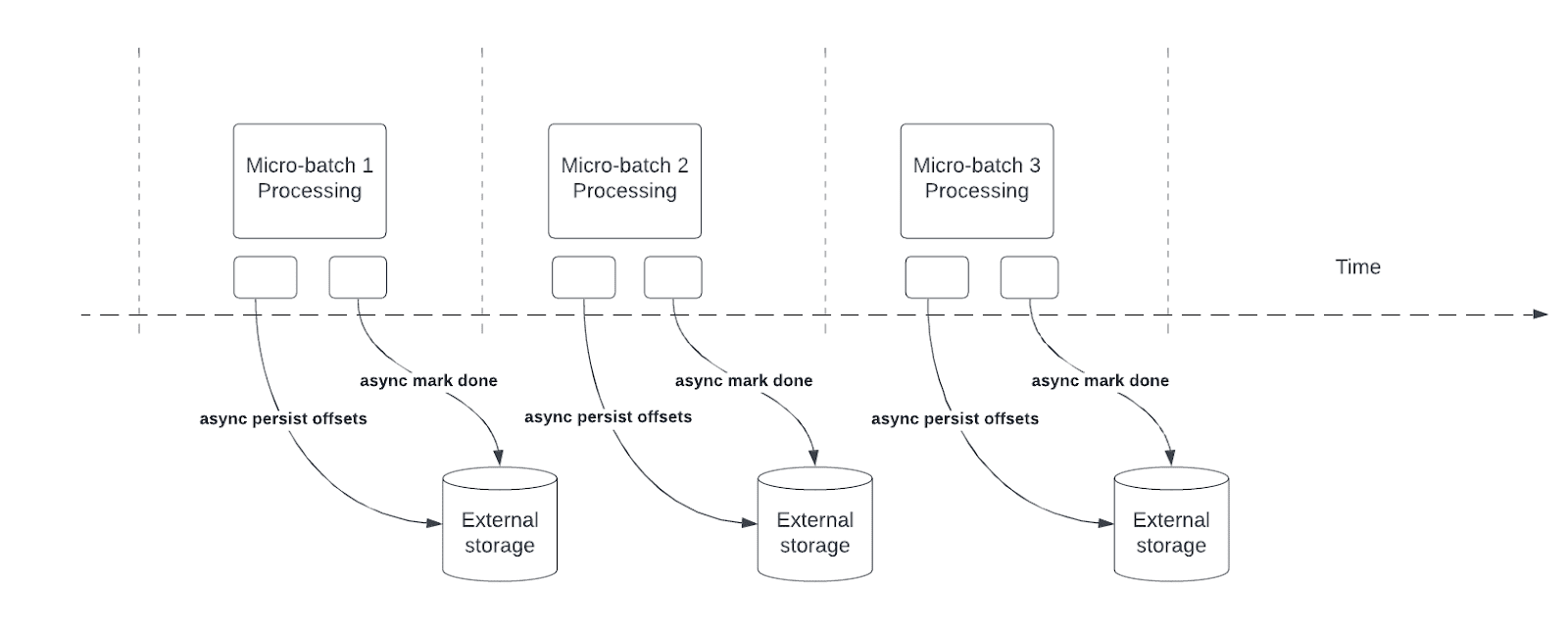
Le suivi de progression asynchrone réduit la latence des pipelines Structured Streaming en permettant aux requêtes de mettre à jour de manière asynchrone la progression du point de contrôle et de traiter les données dans chaque micro-lot.
Pendant le traitement des requêtes, Structured Streaming conserve et gère les décalages pour mesurer la progression des requêtes dans le offsetLog et le commitLog de chaque micro-lot. Sans suivi de progression asynchrone, les opérations de gestion des décalages affectent directement la latence de traitement, car le traitement des données ne peut pas continuer tant qu’ils ne sont pas terminés.
Note
Le suivi de progression asynchrone n’est pas compatible avec les déclencheurs Trigger.once ou Trigger.availableNow. Si cette option est activée, les requêtes Structured Streaming avec Trigger.once ou Trigger.availableNow échouent.
Options de configuration
| Choix | Par défaut | Descriptif |
|---|---|---|
asyncProgressTrackingEnabled |
false |
Indique s’il faut activer le suivi de progression asynchrone. |
asyncProgressTrackingCheckpointIntervalMs |
1000 |
Intervalle en millisecondes entre les écritures des offsets et les validations d'achèvement. |
Activer le suivi de progression asynchrone
Pour activer le suivi de progression asynchrone, définissez asyncProgressTrackingEnabled sur true:
Python
stream = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
)
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
)
Scala
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
Améliorer le débit grâce à la fréquence des points de contrôle
La fréquence de point de contrôle par défaut de 1000 millisecondes présente un débit correct pour la plupart des requêtes. Lorsque les opérations de gestion de décalage se produisent plus rapidement que le suivi de progression asynchrone peut les traiter, un backlog des opérations de gestion de décalage est généré. Pour empêcher le backlog de croître davantage, le suivi de progression asynchrone peut bloquer ou ralentir le traitement des données, ce qui peut éroder les avantages attendus de la latence.
Dans ce scénario, Databricks vous recommande d’augmenter l’intervalle de point de contrôle :
Python
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
)
Scala
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
Note
Le temps de récupération des défaillances augmente avec le temps d’intervalle de point de contrôle. En cas de défaillance, un pipeline doit retraiter l'intégralité des données depuis le point de contrôle réussi précédent. Avant d’apporter cette modification en production, envisagez le compromis entre une latence inférieure pendant le traitement régulier par rapport au temps de récupération en cas de défaillance.
Désactiver le suivi de progression asynchrone
Lorsque le suivi de progression asynchrone est activé, le flux ne garantit pas la progression des points de contrôle pour chaque lot. Vous devez vérifier la progression avant de pouvoir désactiver cette fonctionnalité.
Pour désactiver, procédez comme suit :
Traitez au moins deux micro-lots avec
asyncProgressTrackingEnableddéfini surtrueetasyncProgressTrackingCheckpointIntervalMsdéfini sur0:Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start()Arrêtez la requête :
Python
query.stop()Scala
query.stop()Désactivez le suivi de progression asynchrone et redémarrez la requête :
Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start()
Si vous désactivez le suivi de progression asynchrone sans suivre les étapes ci-dessus, vous pouvez rencontrer l’erreur suivante :
java.lang.IllegalStateException: batch x doesn't exist
Dans les journaux du pilote, l’erreur suivante peut s’afficher :
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
Limitations
- Pour les récepteurs Kafka, le suivi de progression asynchrone prend uniquement en charge les pipelines sans état.
- Le suivi de progression asynchrone ne garantit pas exactement un traitement de bout en bout, car les plages de décalage d’un lot peuvent changer en cas d’échec. Certains récepteurs, tels que Kafka, ne fournissent jamais de garanties exactement une fois.