Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les tests de charge recherchent les requêtes maximales par seconde (QPS) que votre agent Databricks Apps peut supporter avant de dégrader les performances. Cette page vous montre comment effectuer les opérations suivantes :
- Déployez une version fictive de votre agent pour isoler le débit de l’infrastructure de la latence LLM.
- Exécutez un test de charge de rampe à saturation avec Locust.
- Analysez les résultats avec un tableau de bord interactif.
Vous pouvez suivre le parcours assisté par l’IA à l’aide d’une compétence Claude Code ou configurer manuellement chaque étape.
Exigences
- Un espace de travail Azure Databricks avec Databricks Apps activé.
- Une application d’agent déployée (ou prête à être déployée) sur Databricks Apps à l’aide du Kit de développement logiciel (SDK) Des agents OpenAI, de LangGraph ou d’une infrastructure personnalisée. Consultez Créer un agent IA et le déployer sur Databricks Apps.
- L’interface CLI Databricks installée et authentifiée. Consultez Installer ou mettre à jour l’interface CLI Databricks.
- Python 3.10+ avec
uvgestionnaire de package. - (Pour le chemin d’accès assisté par l’IA) Claude Code installé.
- (Pour les tests de charge supérieurs à ~1 heure) Un principal de service avec des informations d’identification OAuth M2M (
client_idetclient_secret). Consultez Autoriser l'accès principal de service pour Azure Databricks avec OAuth.- Pour les tests de charge courts (moins d’environ 1 heure), vos informations d’identification
databricks auth loginOAuth existantes (U2M) fonctionnent correctement. Pour les tests plus longs, utilisez M2M OAuth avec un principal de service : les jetons U2M expirent pendant de longues exécutions et provoquent des échecs de test intermédiaires. La création d’un principal de service nécessite l’accès administrateur de l’espace de travail.
- Pour les tests de charge courts (moins d’environ 1 heure), vos informations d’identification
Configuration assistée par l’IA (recommandé)
Si vous utilisez Claude Code, la /load-testing compétence automatise le flux de travail. Il lit le code de votre agent, génère une simulation, crée des scripts de test de charge et vous guide tout au long du déploiement.
Conseil / Astuce
Dites à Claude Code de le faire pour vous :
Clone https://github.com/databricks/app-templates and run the /load-testing skill against the {your-template} template.
Ou suivez les étapes ci-dessous.
Étape 1 : Cloner un modèle d’agent
La /load-testing compétence est incluse dans le référentiel databricks/app-templates , à la fois comme compétence de niveau agent-load-testing supérieur et présynchronisée dans chaque modèle d’agent individuel. Si vous avez déjà un projet de app-templates, vous possédez déjà la compétence.
Clonez le dépôt et accédez au répertoire du modèle de l’agent pour effectuer le test de charge que vous souhaitez réaliser.
git clone https://github.com/databricks/app-templates.git
cd app-templates/{your-template}
Étape 2 : Exécuter la compétence de test de charge
Dans Claude Code, exécutez :
/load-testing
La compétence vous guide de manière interactive dans les étapes suivantes. Vous pouvez ignorer la simulation pour tester votre agent réel ou ignorer le déploiement si vos applications sont déjà en cours d’exécution.
- Collecte des paramètres : vous demande l’état de votre déploiement, les tailles de calcul, les configurations de travail et les informations d’identification OAuth.
- Création de scripts de test de charge : génère
locustfile.py,run_load_test.pyetdashboard_template.pyadaptés à votre projet. - La simulation de votre LLM : crée un client fictif spécifique à votre SDK (OpenAI Agents SDK, LangGraph, ou personnalisé) qui substitue les appels LLM réels par des délais de streaming configurables.
- Déploiement d’applications de test : vous guide tout au long du déploiement de plusieurs configurations d’application avec différentes tailles de calcul et nombres de workers.
- Exécution de tests : exécute les tests de charge avec l’authentification OAuth M2M et le ramp-to-saturation.
- Génération de résultats : produit un tableau de bord HTML interactif avec des métriques de QPS, de latence et d’échec.
Configuration manuelle
Suivez ces étapes pour configurer et exécuter des tests de charge sans assistance de l’IA.
Étape 1 : Simuler les appels LLM de votre agent (facultatif)
Ignorez cette étape si vous souhaitez obtenir des résultats de bout en bout qui incluent une latence LLM réelle. Pour mesurer le débit de l’infrastructure Databricks Apps en isolation, fictivez le LLM afin que sa latence par requête (généralement 1 à 30 secondes) ne devienne pas le goulot d’étranglement.
Une simulation retourne des réponses pré-enregistrées avec un délai de diffusion en continu configurable, tout en maintenant le pipeline de requête/réponse complet (streaming SSE, distribution d’outils, exécuteur du SDK) et en remplaçant uniquement le LLM. Cela met en évidence le nombre maximal de QPS que la plateforme Databricks Apps peut fournir et évite les coûts de jetons d’API Foundation Model pendant les tests de charge.
Le minutage fictif est contrôlé par deux variables d’environnement :
| Variable | Par défaut | Description |
|---|---|---|
MOCK_CHUNK_DELAY_MS |
10 |
Retard en millisecondes entre les blocs de texte diffusés en continu |
MOCK_CHUNK_COUNT |
80 |
Nombre de blocs de texte par réponse |
Avec les valeurs par défaut, chaque réponse fictive prend environ 800 ms (10 ms x 80 blocs), beaucoup plus rapide qu’une réponse LLM réelle (3 à 15 secondes). Les numéros de débit reflètent ensuite la plateforme, et non le modèle.
Créez un client fictif qui remplace le client LLM réel. Le reste de votre code d’agent reste inchangé et l’approche dépend de votre KIT SDK. Pour OpenAI, consultez l’implémentationmock_openai_client.py de référence dans databricks/app-templates. Le même modèle s’adapte à d’autres kits SDK.
Kit de développement logiciel (SDK) Des agents OpenAI
Créer agent_server/mock_openai_client.py : classe MockAsyncOpenAI qui implémente chat.completions.create() avec la diffusion en continu. Il retourne instantanément des blocs d’appel d’outil (simulant le LLM qui décide d’appeler un outil) et des blocs de réponse texte avec un délai configurable à partir des variables d’environnement MOCK_CHUNK_DELAY_MS et MOCK_CHUNK_COUNT.
Échangez-le dans votre agent :
from agent_server.mock_openai_client import MockAsyncOpenAI
from agents import set_default_openai_client, set_default_openai_api
set_default_openai_client(MockAsyncOpenAI())
set_default_openai_api("chat_completions")
Le reste du code de votre agent (gestionnaires, outils, logique de diffusion en continu) reste inchangé.
LangGraph
Remplacez le ChatDatabricks modèle par une simulation qui retourne des objets prédéfinis AIMessage :
# Before:
# model = ChatDatabricks(endpoint="databricks-claude-sonnet-4")
# After:
from agent_server.mock_llm import MockChatModel
model = MockChatModel()
La simulation doit renvoyer AIMessage des objets avec des appels d'outils lors de la première invocation et du contenu textuel lors des invocations suivantes, avec des délais de diffusion continue configurables.
Agents personnalisés
Encapsulez les appels d’API externes que votre agent effectue (LLM, recherche vectorielle, API d’outil) avec des implémentations fictives qui retournent des formes de réponses réalistes avec des retards configurables.
Étape 2 : Configurer des scripts de test de charge
Créez un load-test-scripts/ répertoire dans votre projet. L’infrastructure de test de charge se compose de trois scripts qui sont indépendants de l’infrastructure et qui fonctionnent avec n’importe quel agent Databricks Apps.
<project-root>/
agent_server/ # Your existing agent code
load-test-scripts/ # Load testing scripts (create this)
run_load_test.py # CLI orchestrator
locustfile.py # Locust test with SSE streaming + TTFT tracking
dashboard_template.py # Interactive HTML dashboard generator
load-test-runs/ # Results (auto-created per run)
<run-name>/
dashboard.html # Interactive dashboard
test_config.json # Test parameters for reproducibility
<label>/ # Per-config Locust CSV output
L’infrastructure inclut les fichiers suivants :
-
locustfile.py: Un test de charge Locust qui envoiePOST /invocationsrequêtes avecstream: true, analyse les flux SSE, suit le temps jusqu'au premier jeton (TTFT) en tant que métrique personnalisée, utilise l'échange de jetons OAuth M2M avec actualisation automatique, et implémente unStepRampShapequi fait évoluer le nombre d'utilisateurs destep_sizeàmax_users, en maintenant chaque niveau pendantstep_durationsecondes. -
run_load_test.py: orchestrateur CLI qui teste séquentiellement chaque URL d’application avec des métriques isolées par configuration. Il gère l’actualisation des jetons OAuth, exécute un contrôle d’intégrité et un préchauffement avant chaque test, puis enregistre les résultats dansload-test-runs/<run-name>/<label>/. -
dashboard_template.py: génère un tableau de bord HTML autonome à l’aide de Chart.js avec des cartes KPI, des graphiques à barres (QPS, latence, TTFT par configuration), des graphiques en courbes de progression de rampe QPS et une table de résultats complète. Peut être exécuté autonome :uv run dashboard_template.py ../load-test-runs/<run-name>/.
Installer des dépendances
Les scripts de test de charge utilisent leur propre pyproject.toml à l'intérieur de load-test-scripts/ pour éviter de polluer les dépendances de production de votre agent. Créez load-test-scripts/pyproject.toml :
[project]
name = "load-test-scripts"
version = "0.1.0"
requires-python = ">=3.10"
dependencies = [
"locust>=2.32,<2.40",
"urllib3<2.3",
"requests",
]
Note
Épingler locust à <2.40. Les versions plus récentes (>=2.43) ont un problème connu RecursionError qui interrompt les tests de charge longs.
Installez à partir du load-test-scripts/ répertoire :
cd load-test-scripts/
uv sync
Étape 3 : Déployer des applications de test avec différentes configurations
Déployez plusieurs applications Databricks avec différentes tailles de calcul et nombres de workers pour trouver la configuration optimale de votre charge de travail.
Matrice de test recommandée
Les configurations ci-dessous se concentrent sur le point optimal déterminé à partir des tests précédents. Si vous souhaitez une couverture plus large, ajoutez une configuration de part et d’autre (par exemple, medium-w1 ou large-w12), mais les six ci-dessous sont généralement suffisantes.
| Taille de la capacité de calcul | Collaborateurs | Nom de l’application suggérée |
|---|---|---|
| Moyen | 2 | <your-app>-medium-w2 |
| Moyen | 3 | <your-app>-medium-w3 |
| Moyen | 4 | <your-app>-medium-w4 |
| Grand | 6 | <your-app>-large-w6 |
| Grand | 8 | <your-app>-large-w8 |
| Grand | 10 | <your-app>-large-w10 |
Configurer la taille du calcul
Utilisez l’interface CLI Databricks pour définir la taille de calcul lors de la création ou de la mise à jour d’une application :
# Create a new app with Medium compute
databricks apps create <app-name> --compute-size MEDIUM
# Update an existing app to Large compute
databricks apps update <app-name> --compute-size LARGE
Configurer le nombre de travailleurs avec des bundles d'Automatisation déclaratifs
start-server (via AgentServer.run()) accepte directement un --workers indicateur. Transmettez le nombre de travailleurs dans le command tableau à l’aide d’une variable DAB :
variables:
app_name:
default: 'my-agent-medium-w2'
workers:
default: '2'
resources:
apps:
load_test_app:
name: ${var.app_name}
source_code_path: .
config:
command: ['uv', 'run', 'start-server', '--workers', '${var.workers}']
env:
- name: MOCK_CHUNK_DELAY_MS
value: '10'
- name: MOCK_CHUNK_COUNT
value: '80'
targets:
medium-w2:
default: true
variables:
app_name: 'my-agent-medium-w2'
workers: '2'
large-w8:
variables:
app_name: 'my-agent-large-w8'
workers: '8'
Déployer et vérifier
Déployez chaque cible avec l’interface CLI Databricks :
databricks bundle deploy --target medium-w2
databricks bundle run load_test_app --target medium-w2
Vérifiez que les applications sont actives avant d’exécuter des tests de charge :
databricks apps get <app-name> --output json | jq '{app_status, compute_status, url}'
Note
Attendez que toutes les applications atteignent le statut ACTIVE avant de continuer. Les applications qui sont encore en cours de démarrage produisent des résultats trompeurs.
Étape 4 : Exécuter des tests de charge
Configurer l’authentification
Sélectionnez votre authentification en fonction de la durée prévue d'exécution :
-
Tests courts (moins d’environ 1 heure) : utilisez vos informations d’identification utilisateur existantes à partir de
databricks auth login. Aucune configuration supplémentaire n’est requise. - Tests longs (plus d’environ 1 heure, comme les exécutions de nuit) : utilisez M2M OAuth avec un principal de service. Les jetons U2M expirent et interrompent votre test en cours d'exécution. La création d’un principal de service nécessite l’accès administrateur de l’espace de travail.
Pour M2M OAuth, exportez les informations d’identification du principal de service avant d’exécuter des tests :
export DATABRICKS_HOST=https://your-workspace.cloud.databricks.com
export DATABRICKS_CLIENT_ID=<your-client-id>
export DATABRICKS_CLIENT_SECRET=<your-client-secret>
Informations de référence sur les paramètres
| Paramètre | Obligatoire | Par défaut | Description |
|---|---|---|---|
--app-url |
Oui | — | URL d’application à tester (reproductible) |
--client-id |
Pour les tests longs |
DATABRICKS_CLIENT_ID Env |
Identifiant client de service principal (M2M OAuth) |
--client-secret |
Pour les tests longs |
DATABRICKS_CLIENT_SECRET Env |
Clé secrète client du principal de service (M2M OAuth) |
--label |
Non | Dérivé automatiquement de l’URL | Étiquette lisible par application (répétable) |
--compute-size |
Non | Détection automatique ou medium |
Balise de calcul de taille par application : medium, large (répétable) |
--max-users |
Non | 300 |
Nombre maximal d’utilisateurs simulés simultanés |
--step-size |
Non | 20 |
Utilisateurs ajoutés par étape de rampe |
--step-duration |
Non | 30 |
Secondes par étape de rampe |
--spawn-rate |
Non | 20 |
Taux de génération utilisateur (utilisateurs/s) |
--run-name |
Non | <timestamp> |
Nom de cette exécution : résultats enregistrés dans load-test-runs/<run-name>/ |
--dashboard |
Non | Désactivé | Générer un tableau de bord HTML interactif une fois les tests terminés |
Exemples de commandes
Test rapide d’application unique (courte exécution : utilise votre databricks auth login session) :
cd load-test-scripts/
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--dashboard --run-name quick-test
Matrice complète sur les 6 configurations recommandées (longue durée : transmettre les authentifiants M2M). Passez les --compute-size flags dans le même ordre que --app-url :
uv run run_load_test.py \
--app-url https://my-app-medium-w2.aws.databricksapps.com \
--app-url https://my-app-medium-w3.aws.databricksapps.com \
--app-url https://my-app-medium-w4.aws.databricksapps.com \
--app-url https://my-app-large-w6.aws.databricksapps.com \
--app-url https://my-app-large-w8.aws.databricksapps.com \
--app-url https://my-app-large-w10.aws.databricksapps.com \
--compute-size medium --compute-size medium --compute-size medium \
--compute-size large --compute-size large --compute-size large \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--dashboard --run-name overnight-sweep
Plusieurs exécutions pour la cohérence statistique :
for RUN in r1 r2 r3 r4 r5; do
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--max-users 1000 --step-size 20 --step-duration 10 \
--run-name my_test_${RUN} --dashboard || break
done
Que se passe-t-il pendant l'exécution d'un programme
-
Contrôle d’intégrité : vérifie que le streaming de l'application fonctionne correctement (réception
[DONE]). - Préchauffement : envoie des requêtes séquentielles pour réchauffer l’application.
-
Rampe vers la saturation : augmente progressivement les utilisateurs simultanés toutes les
step_durationsecondes. - Détection de saturation : quand QPS plafonne malgré l'ajout de plus d'utilisateurs, vous avez atteint le seuil de débit.
Durée estimée
Chaque application sous test s’exécute via sa propre rampe, de sorte que le temps d’exécution total est mis à l’échelle avec le nombre de configurations dans votre matrice. Utilisez la formule ci-dessous pour planifier votre fenêtre d’exécution.
Durée par application : (max_users / step_size) * step_duration secondes.
Avec les valeurs par défaut (--max-users 300 --step-size 20 --step-duration 30) :
- 15 étapes x 30 secondes = environ 7,5 minutes par application
- Pour la matrice de configuration 6 recommandée : environ 45 minutes par exécution
Étape 5 : Afficher et interpréter les résultats
Ouvrez le tableau de bord :
open load-test-runs/<run-name>/dashboard.html(Facultatif) Régénérez le tableau de bord à partir de données existantes, par exemple après la mise à jour du modèle :
cd load-test-scripts/ uv run dashboard_template.py ../load-test-runs/<run-name>/
Sections du tableau de bord
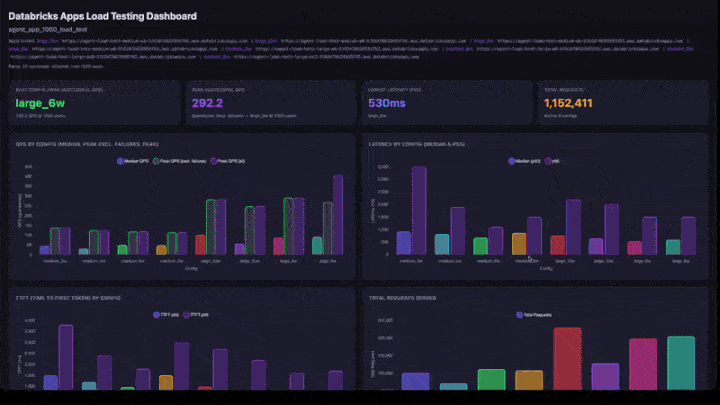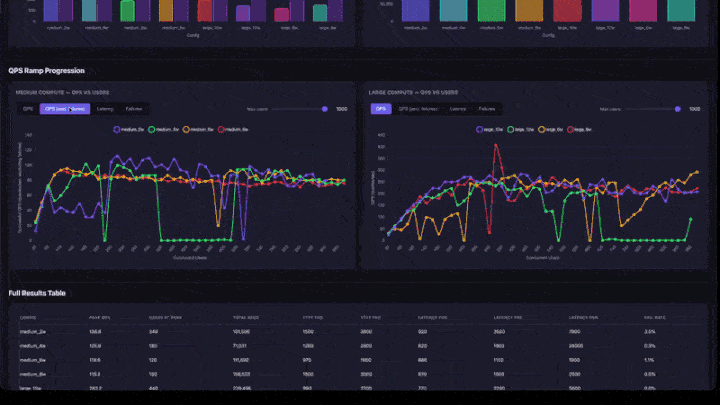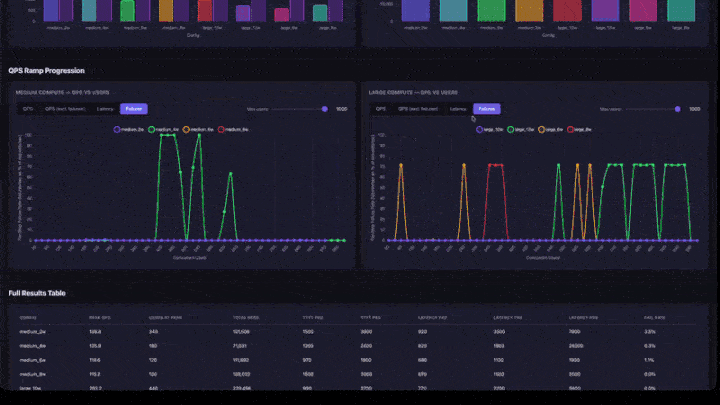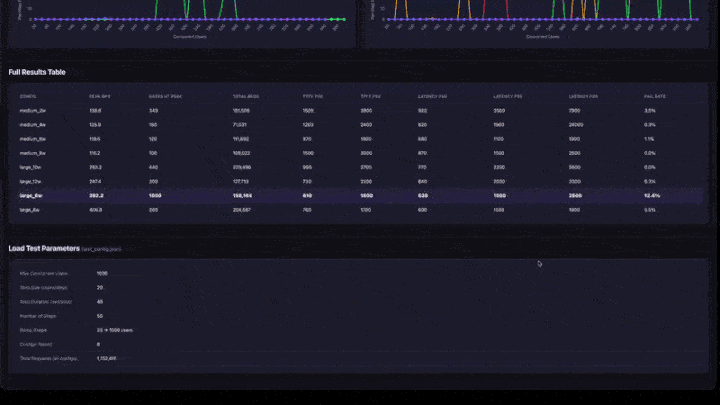
Le tableau de bord interactif comprend les éléments suivants :
- Cartes KPI : meilleure configuration (par pic de réussite de QPS), pic global QPS, latence la plus faible et nombre total de requêtes traitées.
- QPS by Config : graphique à barres groupées montrant QPS médiane, pic QPS à l’exclusion des défaillances et pic de QPS côte à côte pour chaque configuration.
- Latence par configuration : barres groupées affichant la latence p50 et p95.
- TTFT by Config : temps jusqu'au premier jeton (p50 et p95).
- Nombre total de demandes traitées : nombre de demandes par configuration.
- Progression de la rampe QPS : graphiques en courbes avec des onglets pour QPS, QPS (à l’exclusion des défaillances), latence et échecs. Inclut un curseur de nombre maximal d’utilisateurs pour grossir dans des plages de concurrence inférieures. Les graphiques sont regroupés par taille de calcul (moyenne et grande côte à côte).
- Tableau des résultats complets : toutes les configurations avec le pic QPS, les utilisateurs au sommet, les centiles de latence et le taux d’échec.
- Paramètres de test : résumé de la configuration pour la reproductibilité.
Comment interpréter les résultats
- Peak QPS : le nombre maximal de QPS atteint lors de toute étape de montée en charge. Il s’agit du plafond de débit pour cette configuration.
- Utilisateurs au sommet : nombre d’utilisateurs simultanés lorsque le pic de QPS a été atteint. L’ajout d’utilisateurs au-delà de ce point n’augmente pas le débit.
- Taux d’échec : doit être de 0% ou très faible. Un taux d’échec élevé indique que l’application est surchargée à ce niveau d’accès concurrentiel.
- Graphique de rampe QPS : recherchez où la ligne s’aplatit. C’est le point de saturation : l’ajout d’utilisateurs supplémentaires n’augmente pas le débit.
Résolution des problèmes
| Problème | Solution |
|---|---|
| Jeton d’authentification expiré à la mi-test | Pour les tests de plus de ~1 heure, passez de U2M à M2M OAuth en passant --client-id et --client-secret |
| Échec de la vérification de santé | Vérifiez que l’application est ACTIVE : databricks apps get <name> --output json |
| 0 QPS ou aucun résultat | Vérifier load-test-runs/<run-name>/<label>/locust_output.log les erreurs |
| Faible QPS malgré un nombre élevé d’utilisateurs | L’application est saturée. Essayez d'augmenter le nombre de workers ou d'avoir une capacité de calcul accrue. |
| Taux d’échec élevé | L’application est surchargée. Réduisez ou augmentez les --max-users workers/calcul. |
| Le tableau de bord n’affiche aucune donnée de rampe | Vérifiez results_stats_history.csv qu’il existe dans chaque sous-répertoire de résultat |
Étapes suivantes
- Testez avec des appels LLM réels : ignorez l’étape de simulation et déployez votre agent réel pour mesurer la latence de bout en bout, y compris le temps de réponse LLM.
- Paramétrez le nombre de workers : utilisez les résultats de la matrice de test pour trouver le nombre de workers optimal pour votre taille de calcul.
- Tutoriel : Évaluer et améliorer une application GenAI pour mesurer la précision, la pertinence et la sécurité en même temps que le débit.