Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S'APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Data Factory dans Microsoft Fabric est la prochaine génération de Azure Data Factory, avec une architecture plus simple, une IA intégrée et de nouvelles fonctionnalités. Si vous débutez avec l'intégration des données, commencez par Fabric Data Factory. Les charges de travail ADF existantes peuvent être mises à niveau vers Fabric pour accéder à de nouvelles fonctionnalités dans la science des données, l’analytique en temps réel et la création de rapports.
Les flux de données sont disponibles dans les pipelines Azure Data Factory et les pipelines Azure Synapse Analytics. Cet article s’applique aux flux de données de mappage. Si vous débutez avec les transformations, reportez-vous à l’article d’introduction Transformer des données à l’aide de flux de données de mappage.
Conseil
Pour connaître la transformation équivalente (colonne personnalisée) dans Dataflow Gen2, consultez un guide de Dataflow Gen2 pour le mappage des utilisateurs du flux de données.
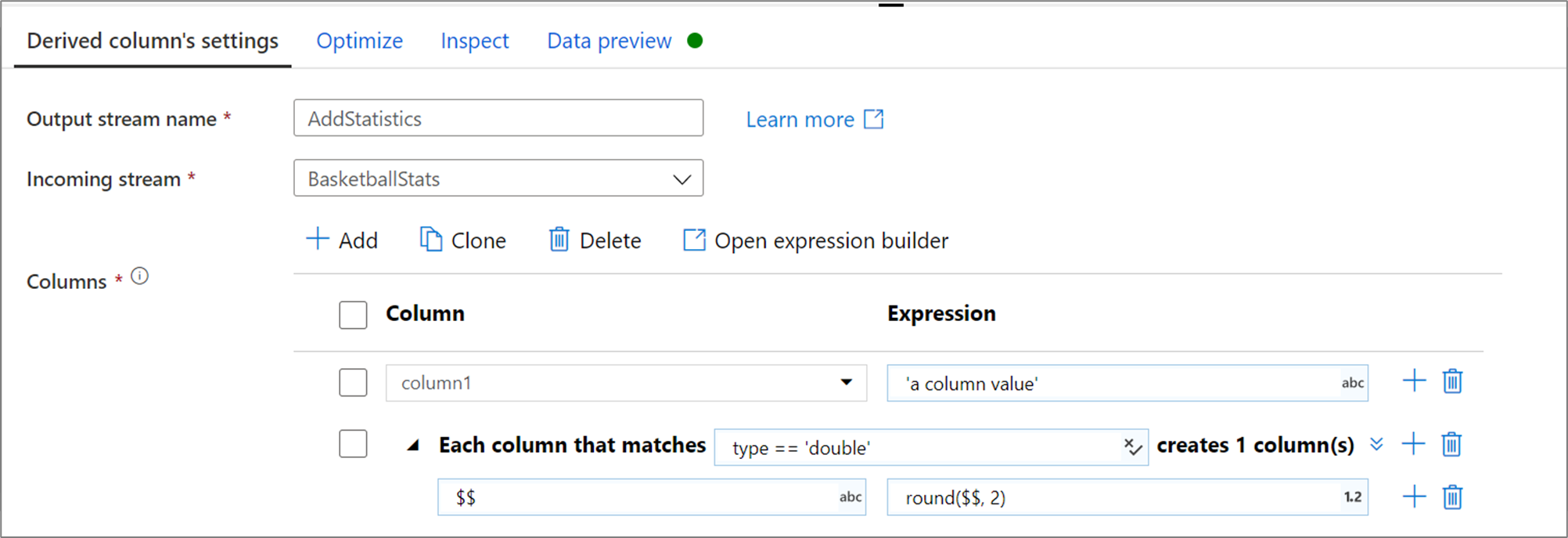
Utilisez la transformation de colonne dérivée pour générer de nouvelles colonnes dans votre flux de données ou pour modifier des champs existants.
Créer et mettre à jour des colonnes
Lors de la création d’une colonne dérivée, vous pouvez soit générer une nouvelle colonne, soit en mettre une à jour. Dans la zone de texte Colonne , entrez la colonne que vous créez. Pour remplacer une colonne existante dans votre schéma, vous pouvez utiliser la liste déroulante Colonne. Pour générer l’expression de la colonne dérivée, sélectionnez-la dans la zone de texte Entrer une expression . Vous pouvez soit commencer à entrer votre expression, soit ouvrir le générateur d’expressions pour construire votre logique.

Pour ajouter d’autres colonnes dérivées, sélectionnez sur Ajouter au-dessus de la liste des colonnes ou l’icône plus en regard d’une colonne dérivée existante. Choisissez Ajouter une colonne ou Ajouter un modèle de colonne.

Modèles de colonne
Dans les cas où votre schéma n’est pas défini explicitement ou si vous souhaitez mettre à jour un ensemble de colonnes en bloc, vous devez créer des modèles de colonnes. Les modèles de colonne vous permettent de faire correspondre les colonnes à l’aide de règles basées sur les métadonnées de colonne et de créer des colonnes dérivées pour chaque colonne correspondante. Pour plus d’informations, consultez Comment générer des modèles de colonne dans la transformation de colonne dérivée.
Génération de schémas à l’aide du générateur d’expressions
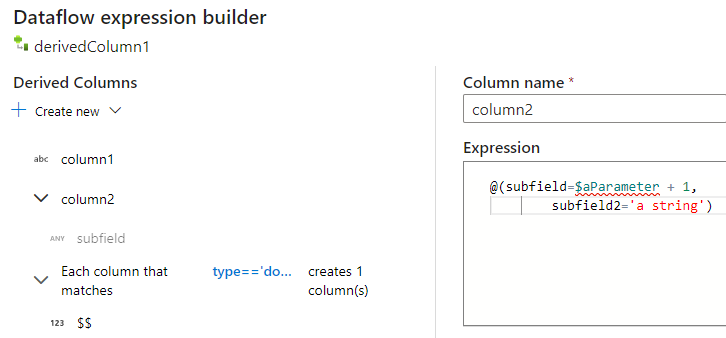
Lors de l’utilisation du générateur d’expressions du flux de données de mappage, vous pouvez créer, modifier et gérer vos colonnes dérivées dans la section Colonnes dérivées. Toutes les colonnes créées ou modifiées dans la transformation sont répertoriées. Choisissez de manière interactive la colonne ou le modèle que vous modifiez en sélectionnant le nom de la colonne. Pour ajouter une autre colonne, sélectionnez Créer et choisissez si vous souhaitez ajouter une seule colonne ou un modèle.

Lorsque vous travaillez avec des colonnes complexes, vous pouvez créer des sous-colonnes. Pour ce faire, sélectionnez l’icône plus en regard de n’importe quelle colonne, puis sélectionnez Ajouter un sous-column. Pour plus d’informations sur la gestion des types complexes dans le flux de données, consultez Traitement JSON dans le flux de données de mappage.

Pour plus d’informations sur la gestion des types complexes dans le flux de données, consultez Traitement JSON dans le flux de données de mappage.
Script de flux de données
Syntaxe
<incomingStream>
derive(
<columnName1> = <expression1>,
<columnName2> = <expression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <deriveTransformationName>
Exemple
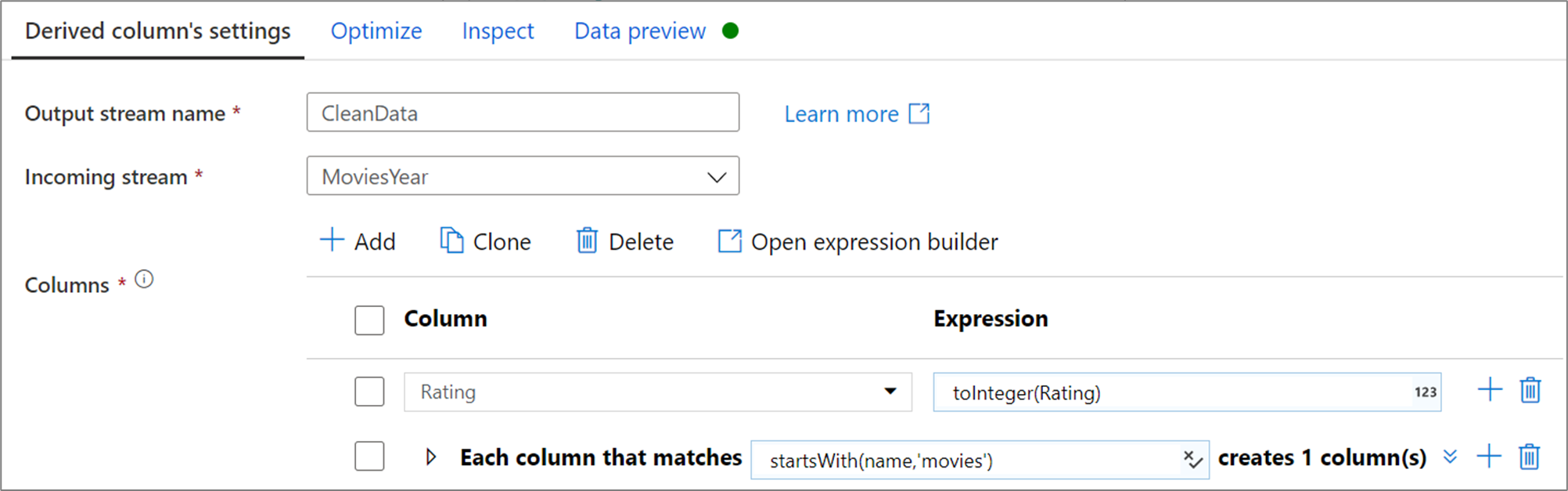
L’exemple ci-dessous est une colonne dérivée nommée CleanData qui prend un flux entrant MoviesYear et crée deux colonnes dérivées. La première colonne dérivée remplace la colonne Rating par la valeur de Rating en tant que type entier. La deuxième colonne dérivée est un modèle qui correspond à chaque colonne dont le nom commence par « movies ». Pour chaque colonne mise en correspondance, elle crée une colonne movie égale à la valeur de la colonne correspondante précédée de « movie_ ».
Dans l’IU, cette transformation se présente comme dans l’image ci-dessous :
Le script de flux de données pour cette transformation se trouve dans l’extrait de code ci-dessous :
MoviesYear derive(
Rating = toInteger(Rating),
each(
match(startsWith(name,'movies')),
'movie' = 'movie_' + toString($$)
)
) ~> CleanData
Contenu connexe
- En savoir plus sur le langage d’expression Mapping Data Flow.