Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Azure Backup offre un framework de pré-script et post-script intégré pour garantir la cohérence des applications sur les machines virtuelles Linux lors de la sauvegarde. Cette infrastructure exécute automatiquement un pré-script pour appliquer le silence aux applications avant les captures instantanées de disque et un post-script pour restaurer les applications à un fonctionnement normal après la capture.
La gestion des prescripts personnalisés et des postscripts est souvent complexe et fastidieuse. Pour simplifier ce processus, Azure Backup fournit des prescripts prêts à l’emploi et des postscripts pour les bases de données populaires afin de permettre des captures instantanées constantes par rapport à l'application tout en demandant un minimum d'effort et de maintenance.
Le diagramme suivant illustre la façon dont Sauvegarde Azure utilise des prescripts améliorés et des postscripts pour obtenir des captures instantanées cohérentes avec les applications pour les bases de données Linux afin de garantir une sauvegarde et une récupération fiables.
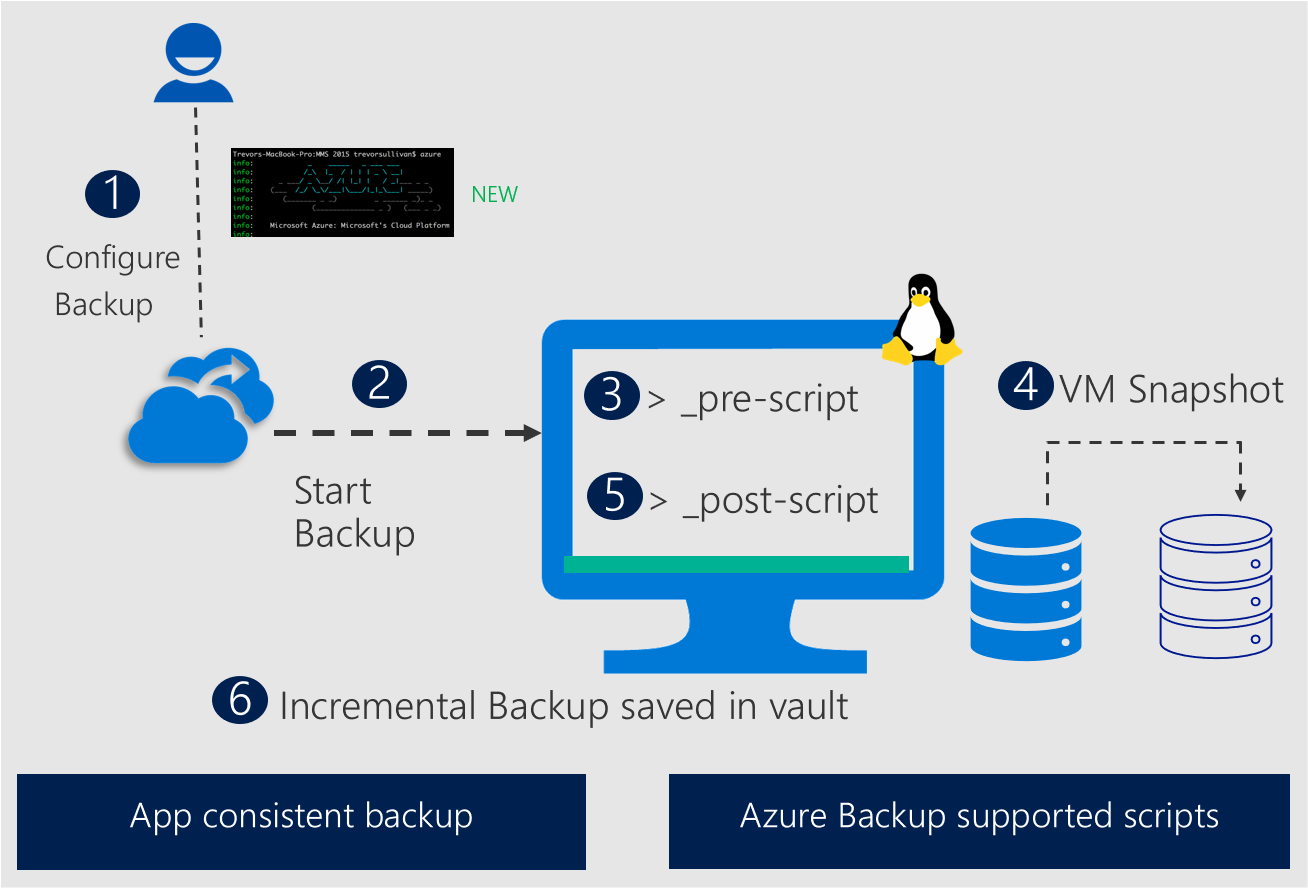
Principaux avantages d’une infrastructure prescript et postscript améliorée
Le nouveau framework prescript et postscript amélioré présente les principaux avantages suivants :
- Ces prescripts et postscripts sont directement installés dans des machines virtuelles Azure, ainsi que l’extension de sauvegarde, ce qui permet d’éliminer la création et de les télécharger à partir d’un emplacement externe.
- La définition et le contenu des prescripts et des postscripts sont disponibles pour l’affichage sur GitHub. Vous pouvez soumettre des suggestions et des modifications via GitHub, qui sont triées et ajoutées pour bénéficier à l’ensemble de la communauté.
- De nouveaux pré-scripts et postscripts pour d'autres bases de données sont disponibles via GitHub, qui sont triés et traités pour bénéficier à la communauté au sens large.
- L’infrastructure robuste est efficace pour gérer les scénarios, tels que l’échec d’exécution prescript ou les blocages. Dans tous les cas, le postscript s’exécute automatiquement pour restaurer toutes les modifications effectuées dans le prescript.
- L’infrastructure fournit également un canal de messagerie pour que les outils externes récupèrent des mises à jour et préparent leur propre plan d’action sur n’importe quel message ou événement.
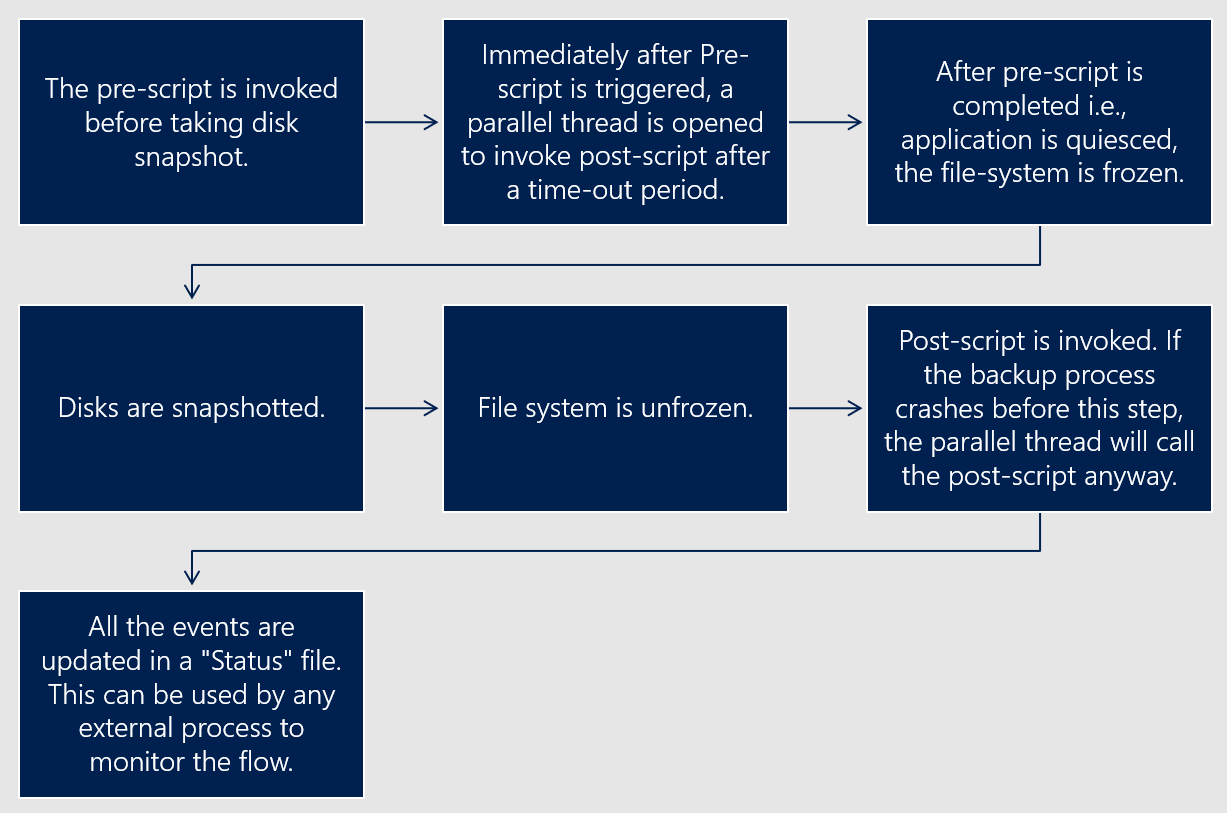
Flux de solution du cadre amélioré de prescript et postscript
Le diagramme suivant illustre le flux de solution de l’infrastructure prescript et postscript améliorée pour les captures instantanées cohérentes avec la base de données.
Matrice de prise en charge
Les bases de données suivantes sont couvertes dans le cadre amélioré :
- Oracle (généralement disponible) : consultez la matrice de prise en charge des sauvegardes de machines virtuelles Azure.
- MySQL (préversion).
Prérequis
Vous devez uniquement modifier un fichier de configuration, workload.conf dans /etc/azure, pour fournir les détails de connexion. Ainsi, Azure Backup peut se connecter à l'application appropriée et exécuter les prescripts et postscripts. Le fichier de configuration a les paramètres suivants :
[workload]
# valid values are mysql, oracle
workload_name =
command_path =
linux_user =
credString =
ipc_folder =
timeout =
Le tableau suivant décrit les paramètres.
| Paramètre | Obligatoire | Explication |
|---|---|---|
workload_name |
Oui | Contient le nom de la base de données pour laquelle vous avez besoin d’une sauvegarde cohérente avec les applications. Les valeurs actuellement prises en charge sont oracle ou mysql. |
command_path/configuration_path |
Contient un chemin d’accès au fichier binaire de charge de travail. Ce champ n’est pas obligatoire si le fichier binaire de charge de travail est défini comme variable de chemin d’accès. | |
linux_user |
Oui | Contient le nom d’utilisateur de l’utilisateur Linux ayant accès à la connexion de l’utilisateur de base de données. Si cette valeur n’est pas définie, la racine est considérée comme l’utilisateur par défaut. |
credString |
Représente la chaîne d’identification pour se connecter à la base de données. Contient la chaîne de connexion entière. | |
ipc_folder |
La charge de travail peut écrire uniquement dans certains chemins du système de fichiers. Fournissez ce chemin d’accès au dossier afin que le prescript puisse écrire les états dans ce chemin d’accès au dossier. | |
timeout |
Oui | Limite de temps maximale pour laquelle la base de données est dans un état silencieux. La valeur par défaut est de 90 secondes. Ne définissez pas de valeur inférieure à 60 secondes. |
Remarque
La définition JSON est un modèle que Sauvegarde Azure peut modifier en fonction d’une base de données particulière. Pour comprendre le fichier de configuration de chaque base de données, reportez-vous au manuel de chaque base de données.
L’expérience globale permettant d’utiliser l’infrastructure prescript et postscript améliorée est la suivante :
- Préparez l’environnement de base de données.
- Modifiez le fichier de configuration.
- Déclenchez la sauvegarde de machine virtuelle.
- Restaurez des machines virtuelles ou des disques ou des fichiers à partir du point de récupération cohérent de l’application en fonction des besoins.
Créer une stratégie de sauvegarde de base de données
Utiliser des instantanés au lieu de la diffusion en continu
En règle générale, les sauvegardes en continu (telles que complète, différentielle ou incrémentielle) et les journaux sont utilisés par les administrateurs de base de données dans leur stratégie de sauvegarde. Les points clés de la conception sont les suivants :
- Performances et coûts : une sauvegarde complète quotidienne plus les journaux est le plus rapide pendant la restauration, mais implique un coût significatif. L’inclusion du type de sauvegarde de streaming différentielle ou incrémentielle réduit le coût, mais peut affecter les performances de restauration. Mais les instantanés fournissent la meilleure combinaison entre niveau de performance et coût. Étant donné que les instantanés sont intrinsèquement incrémentiels, ils ont le moins d’effets sur les performances pendant la sauvegarde, sont restaurés rapidement et économisent également des coûts.
- Impact sur la base de données ou l’infrastructure : les performances d’une sauvegarde de streaming dépendent des E/S par seconde de stockage sous-jacents et de la bande passante réseau disponible lorsque le flux est ciblé vers un emplacement distant. Les captures instantanées n’ont pas cette dépendance, et la demande en IOPS et la bande passante réseau est réduite.
- Réutilisabilité : les commandes pour déclencher différents types de sauvegarde de streaming sont différentes pour chaque base de données. Les scripts ne peuvent donc pas être facilement réutilisés. En outre, si vous utilisez différents types de sauvegarde, veillez à évaluer la chaîne de dépendances pour maintenir le cycle de vie. Pour les instantanés, il est facile d’écrire un script, car il n’existe aucune chaîne de dépendances.
- Rétention à long terme : les sauvegardes complètes sont toujours bénéfiques pour la rétention à long terme, car vous pouvez les déplacer et les récupérer indépendamment. Pour les sauvegardes opérationnelles avec rétention à court terme, il est préférable d'utiliser des instantanés.
Une stratégie de sauvegarde qui inclut un instantané quotidien, des journaux de sauvegarde, en plus d’une sauvegarde complète occasionnelle pour une conservation à long terme, est la meilleure option pour les bases de données.
Stratégie de sauvegarde de fichier journal
L’infrastructure de pré-script et post script améliorée repose sur la sauvegarde de machine virtuelle Azure qui planifie la sauvegarde une fois par jour. Pour cette raison, la fenêtre de perte de données avec un objectif de point de récupération (RPO) de 24 heures n’est pas adaptée aux bases de données de production. Cette solution est complétée par une stratégie de sauvegarde de fichier journal dans laquelle les sauvegardes de fichier journal sont transmises de manière explicite.
Le système de fichiers réseau (NFS) sur Azure Blob Storage et NFS sur AFS (préversion) vous permettent de monter facilement des volumes directement sur des machines virtuelles de base de données et d’utiliser des clients de base de données pour transférer des sauvegardes de journaux. La fenêtre de perte de données, qui est RPO, correspond à la fréquence des sauvegardes de fichier journal. En outre, les cibles NFS n’ont pas besoin d’être très performantes. Vous n’avez peut-être pas besoin de déclencher la diffusion en continu standard (complète et incrémentielle) pour les sauvegardes opérationnelles après avoir des instantanés cohérents avec la base de données.
Remarque
Le pré-script amélioré effectue généralement le vidage de toutes les transactions du journal en transit vers la destination de sauvegarde du fichier journal, avant la suspension de la base de données pour prendre un instantané. Par conséquent, les captures instantanées sont cohérentes et fiables lors de la récupération.
Stratégie de récupération
Une fois que les captures instantanées cohérentes avec la base de données sont effectuées et que les sauvegardes de journaux sont diffusées vers un volume NFS, la stratégie de récupération de la base de données peut utiliser les fonctionnalités de récupération des sauvegardes de machines virtuelles Azure. La capacité des sauvegardes de fichier journal est également appliquée à celle-ci à l’aide du client de la base de données. Les options suivantes pour la stratégie de récupération sont les suivantes :
- Créez de nouvelles machines virtuelles à partir d’un point de récupération cohérent à la base de données. Le point de montage du journal doit déjà être connecté à la machine virtuelle. Utilisez les clients de bases de données pour exécuter des commandes de récupération pour la récupération jusqu’à une date et heure.
- Créez des disques à partir d’un point de récupération cohérent à la base de données et attachez-les à une autre machine virtuelle cible. Monter ensuite la destination du journal et utilisez les clients de bases de données pour exécuter les commandes de récupération pendant la récupération jusqu’à une date et heure.
- Utilisez une option de récupération de fichiers et générez un script. Exécutez le script sur la machine virtuelle cible et attachez le point de récupération en tant que disques iSCSI. Utilisez ensuite les clients de bases de données pour exécuter les fonctions de validation spécifiques à la base de données sur les disques attachés et valider les données de sauvegarde. Utilisez également des clients de base de données pour exporter ou récupérer quelques tables ou fichiers au lieu de récupérer l’intégralité de la base de données.
- Utilisez la fonctionnalité restauration inter-régions pour effectuer les actions précédentes à partir de régions jumelées secondaires lors d’une catastrophe régionale.
Résumé
Avec des instantanés cohérents avec les bases de données ainsi que les journaux sauvegardés à l’aide d’une solution personnalisée, vous pouvez créer une solution de sauvegarde de base de données performante et rentable. Cette solution utilise les avantages de la sauvegarde de machine virtuelle Azure et réutilise également les fonctionnalités des clients de base de données.