Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Le modèle chorégraphique décentralise la logique de flux de travail et distribue les responsabilités à d’autres composants au sein d’un système. Au lieu de dépendre d’un orchestrateur central, les services décident quand et comment traiter une opération métier.
Contexte et problème
Vous divisez généralement une application basée sur le cloud en plusieurs petits services qui fonctionnent ensemble pour traiter une transaction métier de bout en bout. Une seule opération au sein d’une transaction peut entraîner plusieurs appels point à point entre tous les services. Dans l’idéal, ces services sont faiblement couplés. Il est difficile de concevoir un flux de travail distribué, efficace et évolutif, car il implique une communication interservice complexe.
Un modèle commun pour la communication consiste à utiliser un service centralisé ou un orchestrateur. Les requêtes entrantes passent par l’orchestrateur qui délègue les opérations aux services respectifs. Chaque service termine ses responsabilités et n'est pas au courant du flux de travail global.

Vous implémentez généralement le modèle d’orchestrateur en tant que logiciel personnalisé qui a des connaissances sur les responsabilités des services au sein du système. L’un des avantages de cette approche est que l’orchestrateur peut consolider l’état d’une transaction en fonction des résultats des opérations individuelles effectuées par les services en aval.
Cette approche crée également des obstacles. L’ajout ou la suppression de services risque de rompre la logique existante, parce qu’il faut reconnecter certaines parties du chemin de communication. Cette dépendance complique la mise en œuvre de l’orchestrateur ainsi que sa maintenance. L’orchestrateur peut affecter négativement la fiabilité de la charge de travail. Sous charge, il peut introduire des goulots d’étranglement des performances et être le point de défaillance unique (SPoF). Il peut également entraîner des défaillances en cascade dans les services en aval.
Solution
Déléguer la logique de gestion des transactions entre les services. Laissez chaque service participer au flux de travail de communication pour une opération métier et décider quand et comment le traiter.
Le modèle chorégraphique réduit la dépendance vis-à-vis des logiciels personnalisés qui centralisent le flux de travail de communication. Les composants implémentent une logique commune lorsqu’ils chorégraphient le flux de travail entre eux sans communiquer directement entre eux.
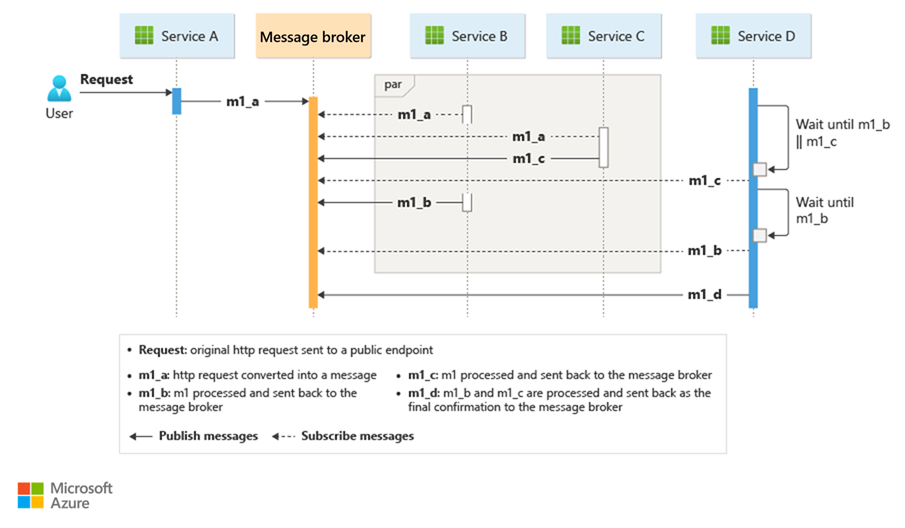
Une façon courante d’implémenter la chorégraphie consiste à utiliser un répartiteur de messages qui met en mémoire tampon les requêtes jusqu’à ce que les composants en aval les réclament et les traitent. L’image suivante montre la gestion des demandes par le biais d’un modèle d’abonné à l’éditeur.

Le client demande la file d'attente sous forme de messages dans un courtier de messages.
Les services ou l’abonné interrogent le répartiteur pour déterminer s’il peut traiter ce message en fonction de sa logique métier implémentée. Le répartiteur peut également envoyer des messages aux abonnés intéressés par ce message.
Chaque service abonné effectue son opération comme le message l'indique et répond au répartiteur par un message indiquant la réussite ou l’échec de l'opération.
Si l’opération réussit, le service peut renvoyer un message vers la même file d’attente ou une autre file d’attente de messages afin qu’un autre service puisse continuer le flux de travail si nécessaire. Si l’opération échoue, le répartiteur de messages collabore avec d’autres services pour compenser cette opération ou l’ensemble de la transaction.
Problèmes et considérations
Tenez compte des points suivants lorsque vous décidez comment implémenter ce modèle :
La gestion des défaillances peut être difficile. Les composants d’une application peuvent gérer des tâches atomiques et dépendre d’autres parties du système. L’échec d’un composant peut affecter d’autres composants, ce qui peut entraîner des retards lors de la fin de la demande globale.
Pour gérer correctement les défaillances, vous implémentez une logique de gestion des défaillances, ce qui introduit une complexité. La logique de gestion des défaillances, telle que la compensation des transactions, est également sujette aux défaillances.
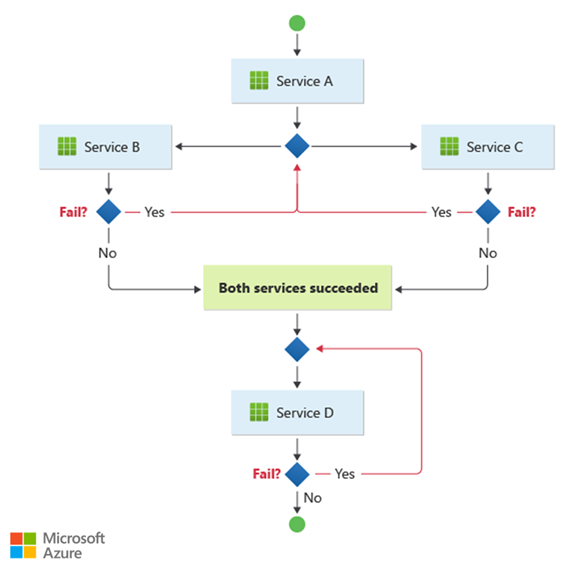
Ce modèle convient à un flux de travail qui traite des opérations métier indépendantes en parallèle. Le workflow peut devenir compliqué lorsque la chorégraphie doit se produire dans une séquence. Par exemple, service D peut démarrer son opération uniquement une fois que Service B et Service C ont terminé leurs opérations avec succès.
Ce modèle présente des défis si le nombre de services augmente rapidement. De nombreuses parties mobiles indépendantes compliquent le flux de travail entre les services. Vous devez utiliser de manière cohérente le suivi distribué et les identificateurs de corrélation pour maintenir l’observabilité.
Dans une conception pilotée par l’orchestrateur, le composant central peut déléguer des responsabilités de résilience, telles que la gestion des nouvelles tentatives pour les défaillances temporaires, nontransientes et de délai d’attente, à un gestionnaire de résilience dédié.
Lorsque vous supprimez l’orchestrateur dans une conception basée sur la chorégraphie, les composants en aval ne prennent pas en charge la résilience. Ils restent centralisés dans le gestionnaire de résilience. Toutefois, les composants en aval doivent communiquer directement avec ce gestionnaire, ce qui augmente la communication point à point.
L’évolution du schéma d’événement peut entraîner des changements cassants dans les consommateurs au fil du temps. Dans ce modèle, plusieurs services indépendants consomment les mêmes événements. Si un producteur modifie la structure des données d’un événement, il peut briser les consommateurs en aval qui dépendent de l’ancien schéma. Utilisez un registre de schémas pour gérer les contrats d’événements et utiliser l’évolution rétrocompatible à mesure que les services évoluent indépendamment.
L’ordre des événements n’est pas garanti en cas de nouvelles tentatives ou de mise à l'échelle horizontale. Concevez en tenant compte de l'idempotence et réémettez les messages en séquence pour gérer les événements en double ou dans le désordre.
Les topologies d’événements décentralisées peuvent créer un comportement émergent à grande échelle. Lorsque de nombreux services réagissent aux événements des uns aux autres, le système peut produire involontairement des boucles de rétroaction ou des tempêtes d’événements. Un événement mineur peut déclencher une cascade de réactions en aval. Pour empêcher les chaînes d’événements circulaires, utilisez des garde-fous comme le filtrage des événements, les limites de concurrence des consommateurs, la limitation et les règles explicites.


Quand utiliser ce modèle
Utilisez ce modèle dans les situations suivantes :
Les composants en aval gèrent les opérations atomiques indépendamment. Considérez ce modèle comme un mécanisme d’incendie et d’oubli , dans lequel un composant effectue une tâche qui n’a pas besoin de gestion active. Une fois la tâche terminée, le composant envoie une notification aux autres composants.
Vous prévoyez fréquemment de mettre à jour et de remplacer les composants. Ce modèle vous permet de modifier l’application avec moins d’efforts et une interruption minimale des services existants.
Vous utilisez des architectures serverless pour les flux de travail simples. Les composants peuvent être éphémères et pilotés par des événements. Lorsqu’un événement se produit, le service crée des composants qui effectuent une tâche et le service supprime les composants une fois cette tâche terminée.
La communication entre les contextes délimités nécessite un couplage libre entre les limites du domaine. Pour la communication à l’intérieur d’un contexte délimité unique, appliquez plutôt un modèle d’orchestrateur.
L’orchestrateur central introduit un goulot d’étranglement des performances.
Ce modèle peut ne pas convenir lorsque :
L’application est complexe et nécessite un composant central capable de gérer une logique partagée afin de préserver la légèreté des composants en aval.
La communication point à point entre les composants est inévitable.
Vous devez utiliser la logique métier pour consolider toutes les opérations gérées par les composants en aval.
Conception de la charge de travail
Évaluez comment utiliser le modèle de chorégraphie dans la conception d'une charge de travail pour répondre aux objectifs et principes abordés dans les piliers du cadre Azure Well-Architected Framework. Le tableau suivant fournit des conseils sur la façon dont ce modèle prend en charge les objectifs de chaque pilier.
| Pilier | Comment ce modèle soutient les objectifs des piliers. |
|---|---|
| L’excellence opérationnelle permet de fournir une qualité de charge de travail grâce à des processus standardisés et à la cohésion de l’équipe. | Les composants distribués de ce modèle sont autonomes et conçus pour être remplaçables. Vous pouvez donc modifier la charge de travail avec moins de modification globale du système. - OE :04 Outils et processus |
| L’efficacité des performances permet à votre charge de travail de répondre efficacement aux demandes par le biais d’optimisations de la mise à l’échelle, des données et du code. | Ce modèle offre une solution de rechange en cas de goulots d’étranglement des performances dans une topologie d’orchestration centralisée. - PE :02 Planification de la capacité - PE :05 Mise à l’échelle et partitionnement |
Si ce modèle introduit des compromis au sein d’un pilier, considérez-les contre les objectifs des autres piliers.
Exemple
Cet exemple montre le modèle chorégraphique en créant une charge de travail native cloud basée sur des événements qui s’exécute en même temps que des microservices. Lorsqu’un client demande d’expédier un package, la charge de travail affecte un drone. Une fois le colis prêt à être récupéré par le drone planifié, le processus de livraison commence. Pendant que le colis est en transit, le flux de travail gère la livraison jusqu'à ce qu'il atteigne le statut 'expédié'.

Le service d’ingestion reçoit les demandes du client et les convertit en messages qui incluent les détails de remise. Les transactions commerciales commencent après que les services consomment ces nouveaux messages.
Une transaction commerciale pour un cliente unique requiert trois opérations commerciales distinctes :
Créez ou mettez à jour un package.
Attribuez un drone pour livrer le colis.
Gérez la livraison, y compris la vérification et l’envoi d’une notification lorsque le colis est livré.
Les packages, les planificateurs de drones et les microservices de livraison effectuent le traitement métier. Les services utilisent la messagerie au lieu d’un orchestrateur central pour communiquer entre eux. Chaque service doit implémenter un protocole à l’avance qui coordonne le flux de travail d’entreprise de manière décentralisée.
Conception
Les services traitent les transactions métier dans une séquence via plusieurs étapes. Un seul bus de messagerie est partagé par chaque tronçon entre tous les services métier.
Lorsqu’un client envoie une demande de remise via un point de terminaison HTTP, le service d’ingestion le reçoit, le convertit en message, puis publie le message dans le bus de messages partagé. Les services commerciaux abonnés consomment les nouveaux messages ajoutés au bus. Lorsqu’un service d’entreprise reçoit le message, il termine l’opération correctement, ou la demande échoue ou expire. Si la requête réussit, le service répond au bus avec le Ok code d’état, déclenche un nouveau message d’opération et l’envoie au bus de messages. Si la requête échoue ou expire, le service signale l’échec en envoyant le code de raison au bus de messages, puis ajoute le message à une file d’attente de lettres mortes (DLQ). Le service déplace également les messages qu’il ne peut pas recevoir ou traiter dans un délai spécifique vers la DLQ.
Cette conception utilise plusieurs bus de messages pour traiter l’ensemble de la transaction métier. Azure Service Bus et Azure Event Grid fournissent la plateforme de service de messagerie pour cette conception. La charge de travail s’exécute sur Azure Container Apps, qui héberge Azure Functions pour l’ingestion. Container Apps gère le traitement piloté par les événements qui exécute la logique métier.
Cette conception garantit également que la chorégraphie se produit dans une séquence. Un espace de noms Service Bus unique contient une rubrique qui comporte deux abonnements et une file d’attente prenant en compte les sessions. Le service d’ingestion publie des messages dans la rubrique. Le service de colis et le service de planification de drone s’abonnent au sujet et publient des notifications qui informent la file d’attente des demandes réussies. Incluez un identificateur de session commun qui associe un GUID à l’identificateur de livraison afin que les services puissent gérer dans l’ordre des séquences de messages connexes. Le service de remise attend deux messages associés pour chaque transaction. Le premier message indique que le package est prêt à être expédié, et le deuxième message signale qu’un drone est planifié.
Dans cette conception, Service Bus gère les messages à valeur élevée qui ne doivent pas être perdus ou dupliqués pendant l’ensemble du processus de remise. Lorsque le package est livré, un changement d’état est publié sur Event Grid. L’expéditeur de l’événement n’a aucune attente quant à la façon dont le changement d’état est géré. Les services d’organisation en aval que cette conception n’inclut pas peuvent écouter ce type d’événement et exécuter une logique métier spécifique, comme l’envoi d’un e-mail d’état de commande à l’utilisateur.
Si vous déployez ce modèle dans un autre service de calcul, tel que AKS, vous pouvez implémenter le modèle d'application Publisher-Subscriber réutilisable avec deux conteneurs dans le même pod. Un conteneur exécute l’ambassadeur qui interagit avec le bus de messages que vous choisissez pendant que l’autre conteneur exécute la logique métier. Cette approche améliore les performances et la scalabilité. L’ambassadeur et le service métier partagent le même réseau, ce qui réduit la latence et augmente le débit.
Pour éviter les opérations de nouvelle tentative en cascade susceptibles d’entraîner plusieurs tentatives, les services d’entreprise doivent immédiatement marquer des messages inacceptables. Enrichissez ces messages à l’aide de codes de raison courants ou d’un code d’application défini afin que les services puissent les déplacer vers une DLQ. Envisagez d’implémenter le modèle Saga pour gérer les problèmes de cohérence des services en aval. Par exemple, un autre service gère les messages de lettre morte uniquement à des fins de correction, en exécutant une compensation, un réessai ou une transaction pivot.
Les services métier sont idempotents pour s’assurer que les opérations de nouvelle tentative ne créent pas de ressources en double. Par exemple, le service de paquet utilise des opérations upsert pour ajouter des données au stockage de données.
Étapes suivantes
Centralisez la gestion des schémas d’événements à l’aide du registre de schémas dans Azure Event Hubs pour maintenir la compatibilité à mesure que vos services évoluent.
Passez en revue les options de messagerie asynchrone dans Azure pour en savoir plus sur les différents choix d’infrastructure disponibles pour implémenter un flux de travail décentralisé.
Évaluez les fonctionnalités techniques de différentes plateformes pour choisir le service de messagerie Azure approprié pour vos exigences de chorégraphie spécifiques.
Ressources associées
Tenez compte de ces motifs dans votre conception pour la chorégraphie :
Modularisez le service métier à l’aide du modèle Ambassadeur.
Implémentez le modèle d'équilibrage de charge basé sur la file d'attente pour gérer les pics de charge de travail.
Utilisez la messagerie distribuée asynchrone par le biais du modèle Publisher-Subscriber.
Utilisez des transactions de compensation pour annuler une série d’opérations réussies si une ou plusieurs opérations associées échouent.