Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Le traitement du langage naturel englobe les techniques qui analysent, comprennent et génèrent du langage humain à partir de données textuelles. Azure fournit des services managés basés sur les API et des infrastructures open source distribuées qui traitent les charges de travail de traitement du langage naturel qui vont de l’analyse des sentiments et de la reconnaissance d’entité à la classification des documents et à la synthèse de texte. Ce guide vous aide à évaluer et à choisir parmi les principales options de traitement du langage naturel sur Azure afin de pouvoir correspondre à la technologie appropriée à vos besoins en charge de travail.
Remarque
Ce guide se concentre sur les fonctionnalités de traitement du langage naturel disponibles via Azure Language et Apache Spark avec Spark NLP sur Azure Databricks ou Microsoft Fabric. Il ne fournit pas de conseils pour sélectionner des modèles de langage ou concevoir Azure solutions OpenAI. Certaines descriptions de plateforme peuvent référencer les intégrations de modèle de base ou de modèle vocal prises en charge en tant que détails d’implémentation, mais ce guide se concentre sur la sélection du service de traitement du langage naturel. Pour plus d’informations, consultez Choisir une technologie de services IA.
Comprendre le traitement du langage naturel et les modèles de langage
Avant d’évaluer Azure services, comprenez ce qu’est le traitement du langage naturel, comment il diffère des modèles de langage et quelles tâches il traite.
Distinguer le traitement en langage naturel des modèles de langage
Cette section précise la limite entre le traitement du langage naturel et les modèles de langage naturel, et interroge les principales fonctionnalités que les techniques de traitement du langage naturel permettent.
| Dimension | Traitement du langage naturel | Modèles de langage |
|---|---|---|
| Étendue | Un domaine vaste qui couvre diverses techniques de traitement de texte, notamment la tokenisation, la racination, la reconnaissance d'entités, l'analyse des sentiments et la classification des documents. | Sous-ensemble d’apprentissage profond du traitement du langage naturel axé sur la compréhension et la génération de langages de haut niveau. |
| Exemples | Analyseurs basés sur des règles, classifieurs d’entités nommées, analyseurs de sentiments, fréquence inverse de terme (TF-IDF). | GPT, BERT et des modèles similaires basés sur des transformeurs qui génèrent un texte semblable à celui des humains et sensible au contexte. |
| Sortie | Signaux structurés tels que les étiquettes, les scores, les étendues extraites et la syntaxe analysée. | Langage naturel fluide, comme le texte généré, les résumés, les réponses et les complétions. |
| Relation | Domaine parent. Le traitement en langage naturel englobe le spectre complet des méthodes de traitement de texte. | Outil dans le traitement du langage naturel. Les modèles linguistiques améliorent le traitement du langage naturel sans le remplacer. Ils gèrent des tâches cognitives plus larges, mais ne sont pas synonymes de traitement du langage naturel. |
Fonctionnalités de traitement du langage naturel
Classifiez les documents en les étiquetant en tant que courrier indésirable ou sensible. Le traitement en langage naturel catégorise automatiquement les documents en fonction du contenu pour prendre en charge la conformité et le filtrage des flux de travail.
Résumez le texte en identifiant les entités dans le document. Le traitement du langage naturel extrait les entités clés pour produire des résumés concis qui capturent les informations les plus importantes.
Étiqueter des documents avec des mots clés à l’aide d’entités identifiées. Après avoir identifié des entités, vous pouvez générer des balises de mot clé qui simplifient l’organisation des documents. Utilisez ces balises pour la recherche et la récupération basées sur le contenu.
Détecter les rubriques de navigation et de découverte de documents associées. Le traitement en langage naturel identifie les rubriques clés à l’aide d’entités extraites, qui prennent en charge la catégorisation des documents et la navigation basée sur les rubriques.
Évaluer le sentiment du texte. L’analyse des sentiments évalue le ton émotionnel du texte et classifie le contenu comme positif, négatif ou neutre.
Alimentez les sorties de traitement du langage naturel dans des flux de travail en aval. Les résultats tels que les entités extraites, les scores de sentiments et les étiquettes de rubrique servent d’entrées pour le traitement, l’indexation de recherche et l’analytique.
Identifier les cas d’usage potentiels
Les scénarios métier dans de nombreux secteurs bénéficient de solutions de traitement du langage naturel. Les cas d’usage suivants montrent comment les techniques de traitement du langage naturel répondent aux défis réels, du traitement de documents non structurés à l’activation des applications émergentes dans la cybersécurité et l’accessibilité.
Traiter des documents et du texte non structuré
Extrayez l’intelligence des documents créés par l’ordinateur. Le traitement du langage naturel permet le traitement des documents dans les secteurs financiers, médicaux, commerciaux, gouvernementaux et autres. Vous pouvez analyser des documents créés numériquement pour extraire des informations structurées à partir d’entrées non structurées. Pour les documents manuscrits, utilisez Azure Document Intelligence pour convertir du contenu manuscrit en texte avant d’appliquer des techniques de traitement du langage naturel.
Appliquez des tâches de traitement du langage naturel indépendant du secteur pour le traitement du texte. La reconnaissance d’entité nommée (NER), la classification, la synthèse et l’extraction des relations vous aident à traiter et analyser automatiquement le contenu du document non structuré. Ces tâches fonctionnent entre les domaines et ne nécessitent pas de personnalisation spécifique au secteur.
Créez des modèles spécifiques à un domaine pour une analyse spécialisée. Par exemple, ces tâches incluent des modèles de stratification des risques pour les soins de santé, la classification de l’ontologie pour la gestion des connaissances et les résumés de vente au détail pour les données produit et client. L’entraînement de modèle personnalisé dans Azure Language et Spark NLP permet d’améliorer la précision pour ces formats de documents spécifiques au domaine.
Générez des rapports automatisés à partir d’entrées de données structurées. Vous pouvez synthétiser et générer des rapports textuels complets à partir de données structurées. Cette fonctionnalité aide les secteurs comme la finance et la conformité qui nécessitent une documentation approfondie.
Activer la recherche, la traduction et l’analytique
Créez des graphiques de connaissances et activez la recherche sémantique par le biais de la récupération des informations. Le traitement du langage naturel prend en charge la création de graphiques de connaissances et la recherche sémantique, ce qui permet aux systèmes d’interpréter la signification des requêtes plutôt que de s’appuyer sur la correspondance de mots clés uniquement.
Soutenir la découverte de médicaments et les essais cliniques avec des graphiques de connaissances médicales. Les systèmes de traitement du langage naturel analysent le texte clinique. Les graphiques de connaissances médicales créés à partir de ce texte prennent en charge les pipelines de découverte de médicaments et les essais cliniques correspondants. Ces graphiques connectent des entités telles que des médicaments, des conditions et des résultats pour accélérer les flux de travail de recherche. Text analytics for health in Azure Language extrait les entités médicales, les relations et les assertions que vous pouvez utiliser pour construire ces graphiques.
Traduire du texte pour l’IA conversationnelle dans les applications orientées client. La traduction de texte permet l’IA conversationnelle dans plusieurs secteurs d’activité. Vous pouvez créer des applications multilingues orientées client qui traitent et répondent dans la langue préférée de l’utilisateur. Spark NLP fournit directement des fonctionnalités de traduction. Sur Azure, utilisez Azure Translator, qui est un service distinct de Azure Language.
Analysez les sentiments et l’intelligence émotionnelle pour la perception de la marque. L’analyse des sentiments vous permet de surveiller la perception de la marque et d’analyser les commentaires des clients en exposant des signaux émotionnels positifs, négatifs et nuances du texte.
Étendre le traitement du langage naturel aux domaines émergents
Créez des interfaces activées par la voix pour les appareils IoT (Internet des objets) et les appareils intelligents. Le traitement en langage naturel gère la sortie de texte des systèmes de reconnaissance vocale pour comprendre l’intention de l’utilisateur et extraire la signification dans les scénarios ioT et d’appareils intelligents. Les scénarios activés par la voix nécessitent Azure Speech pour la conversion de la parole en texte avant le traitement du langage naturel.
Ajustez dynamiquement la sortie du langage à l’aide de modèles de langage adaptatifs. Les modèles linguistiques adaptatifs ajustent dynamiquement la sortie du langage en fonction de différents niveaux de compréhension d’audience, qui prennent en charge la distribution de contenu éducatif et l’accessibilité.
Détecter le hameçonnage et la mauvaise information par le biais de l’analyse de texte de cybersécurité. Le traitement du langage naturel analyse les modèles de communication et l’utilisation du langage en temps réel pour identifier les menaces de sécurité potentielles dans la communication numérique. Cette analyse permet de détecter les tentatives de hameçonnage et les campagnes de fausses informations.
Évaluer Azure Langage
Azure Language est un service cloud qui fournit des fonctionnalités de traitement du langage naturel pour comprendre et analyser du texte. Vous pouvez y accéder via le portail Foundry, les API REST et les bibliothèques clientes pour Python, C#, Java et JavaScript sans infrastructure à gérer. Pour le développement d’agents IA, vous pouvez également accéder à ces fonctionnalités via le serveur MCP (Language Model Context Protocol) Azure. Vous pouvez y accéder en tant que serveur distant dans le catalogue d’outils Microsoft Foundry ou en tant que serveur auto-hébergé local.
Fonctionnalités prédéfinies
Les fonctionnalités prédéfinies ne nécessitent aucune formation de modèle et sont prêtes à être utilisées :
NER : Identifie et classe les entités dans du texte en types prédéfinis tels que les personnes, les organisations, les emplacements et les dates.
Détection d’informations personnelles : Identifie et réacte les informations d’identification personnelle (PII), y compris les données personnelles et médicales sensibles, dans le texte et les conversations transcrites.
Détection de langue : Détecte la langue d’un document dans un large éventail de langues et de dialectes.
Analyse des sentiments et exploration des opinions : Identifie les sentiments positifs, négatifs ou neutres dans le texte et lie des opinions à des éléments spécifiques tels que les attributs de produit ou les aspects du service.
Extraction d’expressions clés : Évalue le texte non structuré et retourne une liste de concepts principaux et d’expressions clés.
Résumé : Condense les documents et les conversations à l’aide d’approches extractives ou abstraites, qui prennent en charge le résumé du texte, de la conversation et du centre d’appels.
Analyse de texte pour la santé : Extrait et classifie des informations de santé pertinentes à partir d’un texte médical non structuré, y compris des entités médicales, des relations et des assertions.
Entraîner des modèles personnalisés
Vous pouvez utiliser des fonctionnalités personnalisables pour entraîner des modèles sur vos données pour gérer les tâches de traitement du langage naturel spécifiques au domaine :
- Reconnaissance d’entité nommée personnalisée (CNER) : Générez des modèles personnalisés pour extraire des catégories d’entités spécifiques au domaine à partir de texte non structuré. Utilisez CNER lorsque les catégories NER prédéfinies ne couvrent pas votre vocabulaire de domaine.
Azure Langage MCP serveur et agents
Remarque
Le serveur MCP du langage Azure et les agents de routage d’intention et de réponse aux questions exactes sont en préversion. Les fonctionnalités en préversion n’incluent pas de contrat de niveau de service (SLA), et nous ne les recommandons pas pour les charges de travail de production. Certaines fonctionnalités peuvent ne pas être prises en charge ou avoir des fonctionnalités limitées. Pour plus d’informations, consultez les conditions d’utilisation supplémentaires pour les préversions de Microsoft Azure.
Azure Language fournit des agents prédéfinis et des options de déploiement flexibles pour les charges de travail de traitement du langage naturel de production :
Agent de routage des intentions : Gère les flux de conversation. Il comprend les intentions des utilisateurs et les itinéraires vers des réponses précises par le biais d’une logique déterministe et auditable. Utilisez cet agent lorsque vous avez besoin d’un routage conversationnel transparent et déterministe.
Agent de réponse aux questions exactes : Fournit des réponses fiables et word-à-mot aux questions critiques de l’entreprise tout en conservant la supervision humaine et le contrôle de la qualité. Utilisez cet agent lorsque la précision et la cohérence de la réponse sont essentielles.
Vous pouvez accéder aux deux agents via le catalogue d’outils Foundry. Pour plus d’informations, consultez Azure Language MCP serveur et agents (aperçu).
Le serveur MCP Azure Language prend en charge plusieurs options de déploiement :
Serveur MCP hébergé sur le cloud distant : Le catalogue d’outils Foundry répertorie ce serveur. Le serveur fournit un accès géré par le cloud aux fonctionnalités de langage Azure et ne nécessite aucune infrastructure locale.
Serveur MCP auto-hébergé local : Prend en charge les déploiements locaux ou auto-gérés pour les exigences de conformité, de sécurité ou de résidence des données.
Déploiement conteneurisé : Les fonctionnalités suivantes prennent en charge le déploiement conteneurisé pour les scénarios nécessitant un traitement local ou des environnements isolés. Pour obtenir la liste complète des conteneurs disponibles et leur état de disponibilité, consultez Azure prise en charge des conteneurs IA.
- Analyse des sentiments
- Détection de langue
- Extraction d’expressions clés
- NER
- Détection PII
- CNER
- Analyse de texte pour la santé
- Résumé (aperçu)
Évaluer Apache Spark avec spark NLP
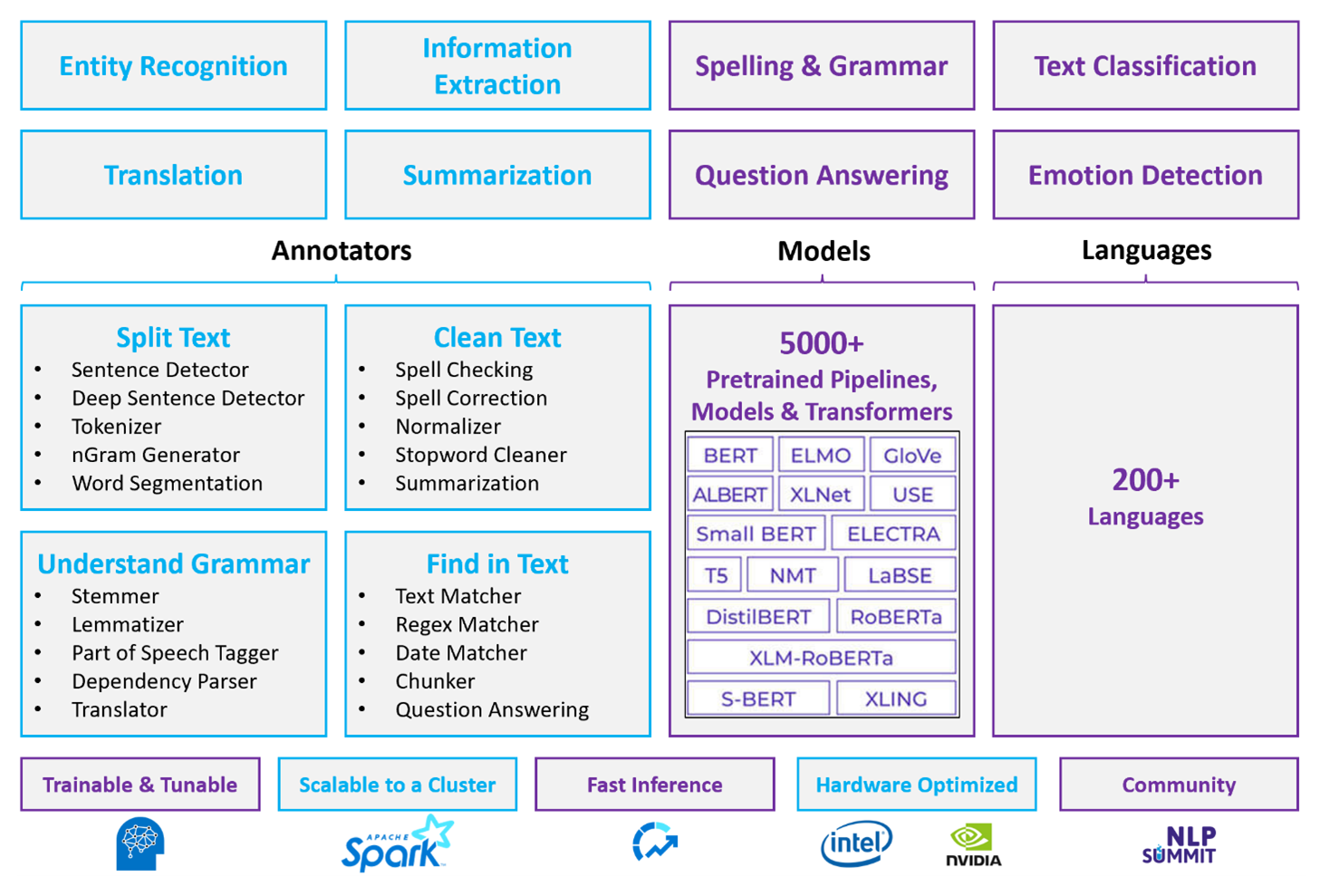
Apache Spark avec Spark NLP est une approche distribuée et open source du traitement du langage naturel qui fonctionne à l’échelle du cluster. L’écosystème de modèles prédéfinis, de performances et d’architecture de plateforme Spark NLP constitue une option forte pour les charges de travail de traitement en langage naturel personnalisables à grande échelle sur Azure Databricks ou Fabric.
Comprendre la plateforme et l’architecture
Nous vous recommandons d’utiliser Fabric ou Azure Databricks pour les charges de travail de traitement du langage naturel basé sur Apache Spark.
Apache Spark fournit un traitement en mémoire parallèle pour l’analytique big data. Fabric et Azure Databricks vous donnent accès aux fonctionnalités de traitement Apache Spark pour les charges de travail de traitement en langage naturel à grande échelle.
Spark NLP fonctionne comme une extension native de Spark ML sur les dataframes. Cette intégration permet un traitement unifié du langage naturel et des pipelines De Machine Learning avec des performances améliorées sur des clusters distribués.
Spark NLP est une bibliothèque open source avec la prise en charge de Python, Java et Scala. La bibliothèque fournit des fonctionnalités comparables à spaCy et Natural Language Toolkit (NLTK), notamment la vérification orthographique, l’analyse des sentiments et la classification des documents.

Apache®, Apache Spark et le logo de flamme sont des marques déposées ou des marques déposées de Apache Software Foundation dans le United States et/ou dans d’autres pays. L’utilisation de ces marques n’implique aucune approbation de l’Apache Software Foundation.
Évaluer les performances et l’extensibilité
Les benchmarks publics montrent des améliorations significatives de la vitesse sur d’autres bibliothèques de traitement du langage naturel. Par rapport aux frameworks tels que spaCy et NLTK, Spark NLP illustre une formation et une inférence plus rapides sur des clusters distribués. Les modèles personnalisés que Spark NLP entraînent atteignent des niveaux de précision qui correspondent à ceux d’autres frameworks de traitement du langage naturel, ce qui le rend adapté aux charges de travail de production qui nécessitent une vitesse et une précision.
Les builds optimisées pour les processeurs, les GPU et les puces Intel Xeon utilisent entièrement des clusters Apache Spark. Ces builds permettent l’apprentissage et l’inférence pour effectuer une mise à l’échelle efficace entre les nœuds de cluster.
Les incorporations MPNet et la prise en charge d’ONNX permettent un traitement précis et conscient du contexte. MPNet produit des représentations vectorielles denses qui capturent la signification sémantique et la prise en charge d’ONNX vous permet d’importer et d’exécuter des modèles optimisés pour l’inférence.
Utiliser des modèles et des pipelines prédéfinis
Les modèles Deep Learning prédéfinis gèrent NER, la classification des documents et la détection des sentiments. La bibliothèque est fournie avec des modèles d’apprentissage profond prédéfinis.
Les modèles de langage préentraînés prennent en charge les incorporations de mots, de segments, de phrases et de documents. La bibliothèque inclut des modèles de langage préentraînés qui prennent en charge les niveaux d’incorporation de mots, de bloc, de phrases et de documents. Ces incorporations fournissent des représentations vectorielles denses qui permettent des tâches en aval telles que la recherche et la classification de similarité.
Le traitement unifié du langage naturel et les pipelines Machine Learning prennent en charge la classification des documents et la prédiction des risques. L’intégration à Spark ML prend en charge le traitement unifié du langage naturel et les pipelines De Machine Learning pour les tâches telles que la classification des documents et la prédiction des risques. Avec cette approche unifiée, vous pouvez combiner le traitement de texte avec des modèles Machine Learning traditionnels dans un seul pipeline, ce qui réduit la complexité architecturale.
Résoudre les problèmes courants liés au traitement du langage naturel
Les deux Azure Language et Apache Spark avec Spark NLP font face à des défis courants dans le traitement du langage naturel à grande échelle. Si vous comprenez ces défis, vous pouvez planifier des ressources, concevoir des pipelines et définir des attentes de précision avant de vous engager dans l’une ou l’autre option.
Traitement des ressources
Le traitement du texte de forme libre nécessite des ressources et un temps de calcul significatifs. L'analyse des documents texte en forme libre est coûteuse en ressources informatiques et demande beaucoup de temps. Chaque document nécessite une tokenisation, une normalisation et une inférence de modèle avant de produire des résultats utilisables.
Les charges de travail spark NLP nécessitent souvent un déploiement de calcul GPU. Pour les pipelines spark NLP à grande échelle, les clusters à accélération GPU sur Azure Databricks ou Fabric fournissent la puissance de traitement parallèle nécessaire à l’apprentissage et à l’inférence. Les optimisations telles que la quantisation de modèle Llama 3.x permettent de réduire l’empreinte mémoire et d’améliorer le débit pour ces tâches intensives.
Azure Language nécessite la planification du débit et la gestion des quotas. Le service gère la gestion des ressources, mais les appels d’API à volume élevé nécessitent une planification minutieuse du débit. Surveillez vos taux de requête par rapport aux limites de service et aux limites de débit pour éviter la limitation et garantir des performances de traitement cohérentes.
Normalisation des documents
Les documents réels suivent rarement une structure cohérente. Cette incohérence crée des défis pour les pipelines d’extraction et nécessite des stratégies délibérées pour maintenir la précision entre les sources.
Formats incohérents : Sans format de document standardisé, l’extraction de faits spécifiques à partir de texte de forme libre peut être difficile. Par exemple, il peut s’avérer difficile d’extraire des numéros de facture et des dates de différents fournisseurs, car les dispositions de champs, les étiquettes et la mise en forme varient selon les sources.
Entraînement de modèles personnalisés : Lorsque vous entraînez des modèles sur mesure dans Spark NLP et Azure Language, vous pouvez vous adapter aux formats spécifiques aux documents de chaque domaine. Lorsque vous effectuez l'apprentissage sur des exemples représentatifs de vos documents réels, vous pouvez améliorer la précision de l'extraction pour les champs, les entités et les modèles que les modèles prédéfinis ne gèrent pas bien.
Variété et complexité des données
Diverses structures de documents et nuances linguistiques ajoutent de la complexité. Les données textuelles du monde réel sont disponibles dans de nombreux formats, styles d'écriture et langues. Le traitement de ces variantes nécessite des modèles capables de gérer l’ambiguïté, l'argot, les abréviations et la terminologie spécifique au domaine tout en conservant la précision.
Les incorporations MPNet dans Spark NLP offrent une compréhension contextuelle améliorée. Les incorporations MPNet capturent les relations contextuelles entre les mots et les expressions, ce qui permet à Spark NLP pipelines de gérer plus efficacement le texte nuanceur. Ces incorporations produisent des représentations vectorielles denses qui préservent la signification sémantique dans différents formats de document.
Les modèles personnalisés dans Azure Language s’adaptent aux modèles de texte spécifiques au domaine. Avec CNER , vous pouvez entraîner des modèles sur vos propres données étiquetées pour reconnaître des modèles spécifiques à votre domaine. Cette approche améliore la fiabilité en enseignant au modèle à reconnaître les entités et les catégories que les modèles prédéfinis ratent.
Appliquer des critères de sélection clés
Utilisez les critères suivants pour déterminer quelle option de traitement en langage naturel Azure convient le mieux à vos besoins. Chaque critère décrit une caractéristique de charge de travail et identifie le service qui l’aborde.
Fonctionnalités de traitement du langage naturel managé : Utilisez Azure Language API pour la reconnaissance d’entité, l’identification des intentions, la détection de rubriques ou l’analyse des sentiments. Ces fonctionnalités sont disponibles en tant que services managés avec une configuration minimale et vous n’avez pas besoin de provisionner ou de gérer une infrastructure.
Modèles préentraînés ou préentraînés : Utilisez Azure Language si vous envisagez d’utiliser des modèles prédéfinis ou préentraînés sans gérer l’infrastructure. Cette approche convient aux jeux de données de petite à moyenne taille et aux tâches de traitement du langage naturel standard où les modèles prédéfinis fournissent une précision suffisante. Il fournit une mise à l’échelle automatique, une sécurité intégrée et une tarification de paiement par appel sans surcharge de gestion des clusters.
La formation du modèle personnalisé sur des ensembles de données textuels volumineux : Utiliser Azure Databricks ou Fabric avec Spark NLP. Ces plateformes fournissent la puissance de calcul et la flexibilité dont vous avez besoin pour une formation approfondie des modèles sur les jeux de données de texte volumineux. Vous pouvez également télécharger des modèles via Spark NLP, notamment Llama 3.x et MPNet.
Primitives de traitement du langage naturel de bas niveau : Utilisez Azure Databricks ou Fabric avec Spark NLP pour la tokenisation, la lemmatisation et TF-IDF. Vous pouvez également utiliser une bibliothèque open source comme spaCy ou NLTK. Azure Language in Foundry Tools utilise la tokenisation en interne dans le cadre de son pipeline de modèle, mais elle n'expose pas ces étapes en tant qu'API autonomes et contrôlables.
Créer des pipelines de traitement en langage naturel à l’aide de Spark NLP
Spark NLP suit le même modèle de développement que les modèles Spark ML traditionnels lorsque vous exécutez un pipeline de traitement en langage naturel. Vous gérez des modèles entraînés à l’aide de MLflow pour le suivi des expériences et le déploiement de production.

Assembler des composants de pipeline de base
Un pipeline Spark NLP chaîne les annotateurs en séquence. Chaque annotateur transforme la sortie de l’étape précédente et génère du texte brut vers des vecteurs sémantiques.
DocumentAssembler est le point d’entrée de chaque pipeline NLP Spark. Permet
setCleanupModed’appliquer un prétraitement de texte facultatif, tel que la suppression d’étiquettes HTML ou la normalisation des espaces blancs, avant l’exécution des annotateurs en aval.SentenceDetector identifie les limites de phrase dans le document assemblé. Elle retourne des phrases détectées sous la forme d’une
Arrayseule ligne ou sous forme de lignes distinctes, en fonction de la configuration de votre pipeline. La détection précise des phrases est importante, car de nombreux annotateurs en aval fonctionnent au niveau de la phrase.Le générateur de jetons divise le texte brut en jetons discrets tels que les mots, les nombres et les symboles. Si les règles par défaut sont insuffisantes pour votre domaine, ajoutez des règles personnalisées pour gérer le vocabulaire spécialisé, les termes traits d’union ou les modèles spécifiques au domaine.
Le normaliseur affine les jetons en appliquant des expressions régulières et des transformations de dictionnaire. Il nettoie le texte pour réduire le bruit avant l’incorporation. Par exemple, vous pouvez supprimer des accents, convertir en minuscules ou appliquer des mappages de dictionnaires personnalisés pour normaliser la terminologie.
WordEmbeddings mappe les jetons aux vecteurs sémantiques pour le traitement contextuel. Chaque jeton est représenté sous la forme d’un vecteur dense qui capture sa signification par rapport à d’autres jetons. Les jetons non résolus qui n’apparaissent pas dans le vocabulaire des embeddings par défaut se transforment en vecteur zéro.
Gérer des modèles à l’aide de MLflow
Spark NLP utilise des pipelines Spark MLlib avec prise en charge native de MLflow . Vous n’avez pas besoin d’écrire de code de sérialisation ou d’intégration personnalisé.
MLflow gère le suivi des expériences, le contrôle de version des modèles et le déploiement. Vous pouvez enregistrer les paramètres de pipeline, les métriques et les artefacts pendant les jeux d'entraînement. MLflow effectue le suivi de chaque expérience, ce qui vous permet de comparer les résultats entre les itérations et de reproduire les configurations réussies.
MLflow s’intègre directement à Azure Databricks et Fabric. Sur Azure Databricks, MLflow est préinstallé et s’intègre étroitement à l’espace de travail. Fabric fournit également une expérience MLflow avec suivi d'expériences et journalisation automatique intégrés, vous n'avez donc pas besoin d'installer MLflow séparément. Si vous exécutez Spark NLP sur un autre environnement Basé sur Apache Spark, vous pouvez installer MLflow séparément et le configurer pour suivre les expériences sur un serveur de suivi à distance.
Utilisez le Registre de modèles MLflow pour promouvoir les modèles en production et gérer la gouvernance. Le Registre de modèles fournit un référentiel central pour gérer les versions de modèle dans vos pipelines de traitement en langage naturel. Dans les déploiements classiques, les modèles de transition par étapes telles que la préproduction, la production et l’archivage. Sur Azure Databricks, les déploiements plus récents utilisent Models dans le catalogue Unity, qui remplace les étapes fixes par des alias et des balises personnalisés pour une gestion plus flexible du cycle de vie. Sur Fabric, l’espace de travail fournit son propre registre de modèles basé sur MLflow.
Matrice des fonctionnalités
Les tableaux suivants résument les principales différences entre les fonctionnalités de Spark NLP sur Azure Databricks ou Fabric et Azure Language.
Fonctionnalités générales
| Capacité | Spark NLP (Azure Databricks ou Fabric) | langue Azure |
|---|---|---|
| Modèles préentraînés en tant que service | Oui | Oui |
| API REST | Oui | Oui |
| Programmabilité | Python, Scala | Consultez les langages de programmation pris en charge. |
| Prend en charge le traitement de jeux de données volumineux et de documents volumineux | Oui | Limité 1 |
1.Azure Language a des limites de taille de document par requête qui varient selon le mode. Les demandes synchrones prennent en charge jusqu’à 5 120 caractères par document et les demandes asynchrones prennent en charge jusqu’à 125 000 caractères par document. Les deux modes prennent en charge jusqu’à 25 documents par appel d’API. Vous pouvez traiter des volumes de jeux de données volumineux via le traitement par lots et la pagination, mais les documents individuels qui dépassent la limite de caractères pour votre mode choisi nécessitent une segmentation. Pour plus d’informations, consultez Data et les limites de débit pour Azure Language.
Fonctionnalités d’annotateur
| Capacité | Spark NLP (Azure Databricks ou Fabric) | langue Azure |
|---|---|---|
| Détecteur de phrases | Oui | Non |
| Détecteur de phrases approfondi | Oui | Non |
| Tokeniseur | Oui | Interne uniquement (non exposé en tant qu’API autonome) |
| Générateur N-gram | Oui | Non |
| segmentation de mots | Oui | Oui |
| Générateur de formes dérivées | Oui | Non |
| Générateur de lemmatisation | Oui | Non |
| Étiquetage des parties du discours | Oui | Non |
| Analyseur de dépendances | Oui | Non |
| Traduction | Oui | Non |
| Nettoyeur de mots vides | Oui | Non |
| Correction orthographique | Oui | Non |
| Normaliseur | Oui | Oui |
| Correspondance de texte | Oui | Non |
| TF-IDF | Oui | Non |
| Correspondance d’expression régulière | Oui | Limité |
| Correspondance de date | Oui | Limité |
| Segmenteur | Oui | Non |
Fonctionnalités de traitement du langage naturel de haut niveau
| Capacité | Spark NLP (Azure Databricks ou Fabric) | langue Azure |
|---|---|---|
| Vérification de l'orthographe | Oui | Non |
| Résumé | Oui | Oui |
| Réponses aux questions | Oui | Oui |
| Détection de sentiments | Oui | Oui |
| Détection d’émotions | Oui | Limité 2 |
| Classification de jetons | Oui | Limité 3 |
| Classification de texte | Oui | Limité 3 |
| Représentation de texte | Oui | Non |
| NER | Oui | Oui (préconstruit). CNER est disponible via des modèles personnalisés. 3 |
| Détection de langue | Oui | Oui |
| Prend en charge les langues autres que l’anglais | Yes. Consultez spark NLP langues prises en charge. | Yes. Consultez langues prises en charge par Azure. |
2.Azure Language prend en charge l'exploration des opinions, qui identifie les sentiments liés à des aspects spécifiques du texte, mais ne fournit pas de détection d'émotion dédiée (comme la joie, la colère ou la classification de la tristesse).
3.Disponiblevia des modèles personnalisés. Vous entraînez des modèles de reconnaissance d’entité personnalisée ou CNER sur vos propres données étiquetées.
Contributeurs
Microsoft conserve cet article. Les contributeurs suivants ont écrit cet article.
Auteurs principaux :
- Ananya Ghosh Chowdhury | Architecte de solution cloud principal
- Kranthi Manchikanti | Ingénieur senior des solutions IA
Autres contributeurs :
- Freddy Ayala | Architecture de solution cloud
- Tincy Elias | Architecte de solution cloud senior
- Moritz Steller | Architecte de solution cloud senior
Pour afficher les profils de LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Introduction à l’IA dans Azure
- Développer des solutions de traitement du langage naturel à l’aide des outils Foundry
Ressources associées
documentation Azure Langue :
- Vue d’ensemble du langage Azure
- Documentation de la fonderie
Documentation de Spark NLP :
composants Azure :
Ressources d'apprentissage :