Muistiinpano
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Tämä resepti näyttää, miten SynapseML:ää ja Foundry Toolsia käytetään Apache Sparkissa monimuuttujapoikkeamien havaitsemiseen. Monimuuttujapoikkeamien havaitsemiseen kuuluu poikkeamien havaitseminen monien muuttujien tai aikasarjojen välillä, samalla kun otetaan huomioon kaikki eri muuttujien väliset korrelaatiot ja riippuvuudet. Tässä skenaariossa käytetään SynapseML:ää ja Foundry Toolsia kouluttaakseen mallin monimuuttujapoikkeamien havaitsemiseen. Mallia käytetään sitten päättelemään monimuuttujapoikkeavuuksia aineistossa, joka sisältää synteettisiä mittauksia kolmesta IoT-anturista.
Tärkeä
20. syyskuuta 2023 alkaen et voi luoda uusia Anomaly Detector -resursseja. Poikkeamatunnistuspalvelu jää eläkkeelle 1. lokakuuta 2026.
Lisätietoja Azure AI Anomaly Detector:sta löytyy Anomaly Detector -tietolähteestä.
Edellytykset
- Azure-tilaus – Luo yksi ilmaiseksi
- Liitä muistikirjasi Lakehouseen. Valitse vasemmalla puolella Lisää lisätäksesi olemassa olevan lakehousen tai luodaksesi lakehousen.
Asetusten määrittäminen
Aloita aiemmin luodusta Anomaly Detector resurssista ja tutki tapoja käsitellä erimuotoisia tietoja.
Poikkeamien tunnistus resurssin luominen
Muistio
20. syyskuuta 2023 lähtien et voi luoda uusia Anomaly Detector -resursseja. Seuraavat vaiheet pätevät vain, jos sinulla on olemassa oleva Anomaly Detector -resurssi. Monimuuttujaisten anomalioiden havaitsemismenetelmästä, joka ei vaadi poikkeamadetektoripalvelua, katso Multivariate Anomaly Detection with Isolation Forest.
- Azure-portaalissa valitse resurssiryhmästäsi Create ja kirjoita sitten Anomaly Detector. Valitse Poikkeamien tunnistus resurssi.
- Nimeä resurssi ja käytä mieluiten samaa aluetta kuin muu resurssiryhmä. Käytä muiden oletusasetuksia, ja valitse sitten Review + Create ja sitten Luo.
- Kun olet luonut poikkeamien havaitsemisen resurssin, avaa se ja valitse
Keys and Endpointspaneeli vasemmasta siirtymisruudusta. Kopioi Poikkeamien tunnistus resurssin avain ympäristömuuttujaanANOMALY_API_KEYtai tallenna se muuttujaananomalyKey.
Tallennustilin resurssin luominen
Välitietojen tallentamiseksi sinun täytyy luoda Azure Blob Storage -tili. Luo kyseisellä tallennustilillä säilö välitietojen tallentamista varten. Merkitse kontin nimi ylös ja kopioi connection string kyseiseen konttiin. Tarvitset sitä muuttujan ja containerName ympäristömuuttujan täyttämiseen BLOB_CONNECTION_STRING myöhemmin.
Anna palveluavaimesi
Ensiksi aseta ympäristömuuttujat palveluavaimillesi. Seuraava solu asettaa ANOMALY_API_KEY ja BLOB_CONNECTION_STRING ympäristömuuttujat Azure Key Vault:n tallennettujen arvojen perusteella. Jos suoritat tämän opetusohjelman omassa ympäristössäsi, muista määrittää nämä ympäristömuuttujat ennen kuin jatkat:
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Lue ANOMALY_API_KEY ja BLOB_CONNECTION_STRING ympäristömuuttujat ja määritä containerName ja-muuttujat location :
# An Anomaly Detector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Yhdistä tallennustiliin, jotta poikkeamatunnistin voi tallentaa välitulokset kyseiselle tallennustilille:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Tuo kaikki tarvittavat moduulit:
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.services import *
Lue mallitiedot Spark DataFrameen:
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
Voit nyt luoda estimator objektin, jota käytät mallisi kouluttamiseen. Määritä koulutusdatan aloitus- ja lopetusajat. Määritä myös käytettävät syötesarakkeet sekä sarakkeen nimi, joka sisältää aikaleimat. Lopuksi, määritä käytettävän datapisteiden määrä anomalioiden tunnistuksen liukuikkunassa ja aseta connection string Azure Blob Storage Accountille:
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Sovita estimator dataan:
model = estimator.fit(df)
Kun koulutus on suoritettu, käytä mallia päättelyyn. Seuraavan solun koodi määrittelee aloitus- ja lopetusajat niille datalle, joissa haluat havaita poikkeamat:
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
Edellisessä solussa .show(5) näkyy viisi ensimmäistä dataframe-riviä. Tulokset johtuvat siitä, null että ne osuvat päättelyikkunan ulkopuolelle.
Jos haluat näyttää tulokset vain päätellyille tiedoille, valitse tarvittavat sarakkeet. Voit sitten järjestää dataframen rivit kasvavassa järjestyksessä ja suodattaa tuloksen näyttämään vain päättelyikkunan rivejä. Tässä se inferenceEndTime vastaa dataframen viimeistä riviä, joten voit jättää sen huomiotta.
Lopuksi, jotta tulokset piirretään paremmin, muunna Spark-tietokehys Pandas-tietokehykseksi:
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
contributors Muotoile sarake, joka tallentaa kunkin anturin osallistumispisteet havaittuihin poikkeavuuksiin. Seuraava solu käsittelee tämän ja jakaa kunkin anturin kontribuutiopisteet omaan sarakkeeseensa:
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Nyt sinulla on antureiden 1, 2 ja 3 panospisteet sarakkeissa series_0, series_1, ja series_2 vastaavasti.
Piirrä tulokset suorittamalla seuraava solu. Parametri minSeverity määrittää piirrettävien poikkeamien vähimmäisvakavuuden:
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
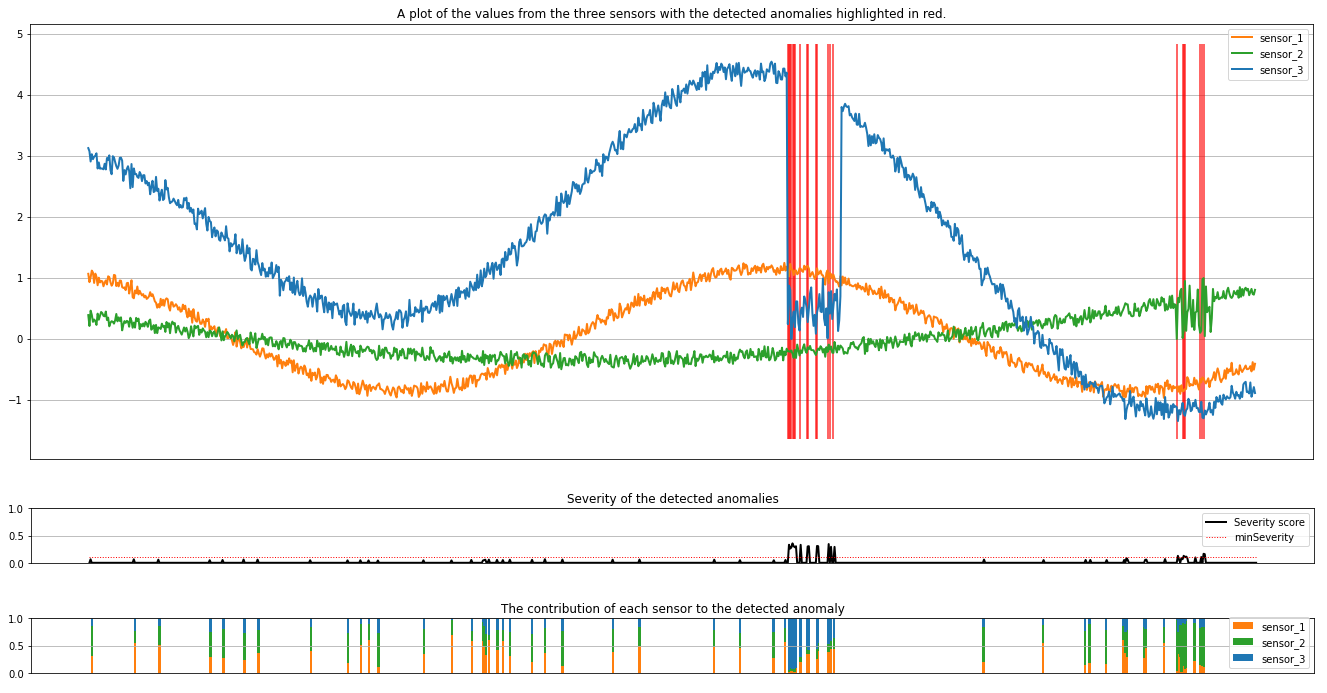
Kaaviot näyttävät antureiden raakatiedot (pääteikkunan sisällä) oranssilla, vihreällä ja sinisellä. Ensimmäisen kuvan punaiset pystyviivat näyttävät havaitut poikkeavuudet, joiden vakavuus on suurempi tai yhtä suuri minSeveritykuin .
Toinen kaavio näyttää kaikkien havaittujen poikkeamien vakavuuspisteet niin, että minSeverity kynnysarvo näkyy pisteviivalla.
Lopuksi viimeinen piirto näyttää kunkin anturin tietojen osuuden havaituista poikkeamista. Se auttaa diagnosoimaan ja ymmärtämään kunkin poikkeaman todennäköisimmän syyn.
Liittyvä sisältö
- Multivariate Anomaly Detection with Isolation Forest – ei vaadi Azure AI Anomaly Detector resurssia.
- LightGBM:n käyttö SynapseML:n kanssa
- Kuinka käyttää Foundry Toolsia SynapseML:n kanssa
- SynapseML:n käyttäminen hyperparametrien hienosäätämiseen