Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se ofrecen instrucciones prácticas para planear la capacidad y el proceso de las cargas de trabajo de Spark en Microsoft Fabric, que abarcan escenarios de desarrollo, migración y producción.
Directrices para el ajuste de tamaño
En esta sección se ofrecen instrucciones prácticas para cambiar el tamaño y configurar cargas de trabajo de Spark en Microsoft Fabric. Trata escenarios como el desarrollo nuevo, la migración desde Synapse y el ajuste de capacidad para su uso en producción.
Escenario: no está familiarizado con Fabric y necesita instrucciones sobre el planeamiento de la capacidad.
Comience con la capacidad de prueba: si no está familiarizado con Fabric, comience con la capacidad de prueba. Ofrece capacidad F4 (4 unidades de capacidad) o capacidad F64 (64 unidades de capacidad) durante 60 días. Esta configuración es ideal para desarrollar y probar cargas de trabajo de Spark. Para calcular la capacidad necesaria, vaya a Planear el tamaño de la capacidad y al Estimador de SKU de Microsoft Fabric (versión preliminar).
Elección del grupo de inicio frente al grupo personalizado:
Grupos de inicio: Normalmente, quiere usar grupos de inicio para las cargas de trabajo de Spark. Microsoft Fabric aprovisiona previamente estos grupos, lo que garantiza tiempos de inicio de sesión rápidos. Son ideales para entornos de desarrollo en los que no se requieren bibliotecas personalizadas, punto de conexión privado administrado (MPE) o Private Link (PL). Los grupos de inicio pueden mejorar significativamente la productividad del desarrollador.
Grupos personalizados: Use grupos personalizados al habilitar el punto de conexión privado administrado (MPE) o Private Link (PL).
Para obtener más información sobre los grupos iniciales y personalizados, consulte la documentación de computación de Apache Spark para la ingeniería de datos y la ciencia de datos.
Generación de perfiles de cuadernos de Spark:
Para supervisar las aplicaciones de Spark en Fabric, puede usar:
Servidor de historial de Spark: para explorar en profundidad los detalles de una sola aplicación y el nivel de fase más granular, el nivel de tarea, los sesgos, el plan lógico y el plan físico.
Interfaz de usuario de uso de recursos: para analizar el uso del ejecutor y la cantidad de ejecutores escalados hacia arriba o hacia abajo después de cada etapa.
Interfaz de usuario de supervisión: métricas de 30 días de la definición de trabajo de Spark/Cuaderno de alto nivel (SJD)/Detalles de ejecución de canalización, como el tiempo de ejecución, el estado, enviado por etc. La interfaz de usuario de supervisión es buena para la visibilidad entre aplicaciones.
Extensión del emisor de diagnóstico: para emitir registros a destinos como Azure Log Analytics, Azure Storage y Azure Event Hubs. Esto es excelente para el análisis de tendencias a largo plazo.
Por lo general, empiece a generar perfiles de la aplicación con grupos de inicio (grupos de Spark medianos (8 núcleos virtuales y 64 GB de memoria)). Comience con un mínimo de un nodo y observe el tiempo de ejecución.
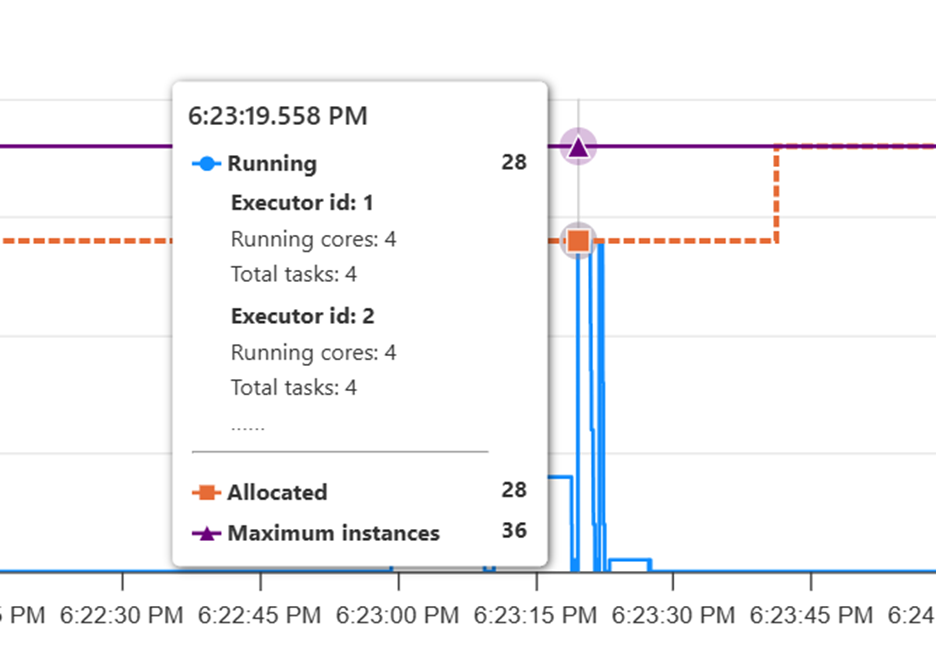
Para observar el uso de recursos, vaya a la interfaz de usuario de uso de recursos de Spark. En la interfaz de usuario de uso de recursos, si las instancias asignadas son menores que las instancias máximas de la fase con el mayor número de tareas, reduzca el número máximo de nodos en la escala automática de Spark para que coincida con las instancias asignadas.

Si las instancias máximas y asignadas se superponen, considere la posibilidad de aumentar la configuración máxima de nodos para mejorar el paralelismo y mejorar el rendimiento.


Manejo del sesgo de datos:
- Si detecta asimetría de datos, es posible que la adición de más recursos no le ayude. Direccione las asimetrías mediante técnicas como la repartición cuando la distribución de datos desigual provoca la asimetría.
- Consulte el artículo de desarrollo y supervisión de esta serie para obtener guía sobre la identificación y corrección de los sesgos.
Evaluación del uso: Use la aplicación Métricas de capacidad para evaluar el uso y calcular el tamaño de capacidad óptimo para las cargas de trabajo. Consulte la documentación Supervisión del consumo de capacidad de Apache Spark para obtener más detalles. Después de analizar el uso de la capacidad de prueba, elija la capacidad de pago por uso adecuada para sus PoCs y, a continuación, muévase a la capacidad respaldada por una reserva (RI) o la facturación con escalado automático. RI es un compromiso de un año de duración. Una capacidad de pago por uso se puede cancelar en cualquier momento. RI ofrece aproximadamente un descuento del 40% en comparación con la capacidad de pago por demanda.
Escenario: ejecución de cargas de trabajo de Spark en capacidad de pago por uso. ¿Cuál es el modelo de capacidad óptimo que elegir?
Si ejecuta cargas de trabajo de Spark en una capacidad de pago por uso, considere la posibilidad de realizar la transición al escalado automático. El escalado automático proporciona la misma flexibilidad contractual que el pago por uso, pero con la ventaja de eliminar el riesgo de limitación. Sin embargo, los trabajos se ponen en cola si no hay recursos suficientes y a un costo menor.
También puede considerar un modelo híbrido mediante una reserva para cargas de trabajo estables y escalabilidad automática para cargas de trabajo más variables. Las reservas proporcionan el mejor rendimiento de costos, siempre y cuando las capacidades permanezcan bien utilizadas (más de 75% en promedio para el plazo del contrato).
En general, no hay muchas razones por las que podría preferir el pago según consumo sobre las opciones discutidas anteriormente.
Ya tiene una capacidad de pago por uso que ejecuta cargas de trabajo no Spark, y que dispone de más capacidad adicional para ejecutar trabajos de Spark: el coste marginal de añadir otro trabajo a esta capacidad es 0 (aunque si añade demasiados, podría reducirse el rendimiento). Incluso aquí, debería considerar reservar por un año a un costo reducido si es posible.
Tiene un proyecto de PoC o de desarrollo de corta duración, donde la predicción de costos es más importante que la eficiencia de los costos; en este caso, se paga una cantidad fija cada mes. Si sobrepasa la capacidad, no se le cobrará más; en su lugar, se le reducirá la velocidad. Con Autoscale, se le cobra por lo que usa, lo que podría causar sobrecostos si se ejecuta código defectuoso en su entorno de desarrollo. En el caso de un proyecto de desarrollo con un presupuesto estrechamente administrado, esto podría ser una compensación valiosa.
Para optimizar aún más el uso de recursos:
Puede ejecutar varios cuadernos de Spark en una sola sesión de Spark de alta simultaneidad para optimizar el uso de recursos.
Habilite el motor de ejecución nativo (NEE) para aumentar significativamente el rendimiento.
Escenario: está migrando las cargas de trabajo de Synapse a Fabric.
Si va a migrar cargas de trabajo de Synapse a Fabric, es posible que se pregunte qué cambia, qué permanece igual y si puede reutilizar las dimensiones de Synapse existentes.
Migración y optimización:
Use la utilidad de migración Synapse to Fabric para mover las cargas de trabajo.
Active la facturación de Autoscale para Spark. Si el entorno y Lakehouse son los mismos, ejecute los notebooks o flujos de trabajo en modo de alta simultaneidad (característica no disponible en Synapse) para mejorar el rendimiento.
Perfilar los cuadernos usando el motor de ejecución nativo (NEE) para optimizar el rendimiento de sus cargas de trabajo.
Directrices generales de configuración de proceso:
| Escenario | Guidance |
|---|---|
| Tareas de transformación intensivas con intercambios y uniones | Usar nodos más grandes (de 16 a 64 núcleos) |
| Trabajos explosivos o imprevisibles | Use Escalabilidad automática de Spark + Asignación dinámica para permitir que el clúster crezca o reduzca según sea necesario. Funciona bien cuando los trabajos varían en tamaño. |
| Muchos trabajos paralelos pequeños (por ejemplo, microtrabajos de streaming o por lotes) | Use nodos pequeños o medianos. Configure un número mínimo de nodos para evitar retrasos en el arranque en frío. Para trabajos más pequeños, puede organizarlos mediante notebookutils.notebook.runMultiple(), que permite ejecutar varios cuadernos en paralelo. |
| Trabajos procesados en serie pequeños o trabajos de desarrollo | Use nodos pequeños o medianos en modo de nodo único (controlador y ejecutor comparte 1 máquina virtual). |
| Trabajos grandes con particiones conocidas | Dimensionar el clúster manualmente: elige el tamaño mínimo de nodo y cuenta basado en el volumen de datos y las etapas de mezcla. |
| Aprendizaje automático o distribuido | Use muchos nodos medianos o grandes para maximizar el paralelismo y distribuir el proceso uniformemente. |
| Para ejecutar solo código de Python | Uso del kernel de Python |