Basar su modelo en la generación aumentada de recuperación
La ingeniería de avisos ayuda a guiar cómo responde un modelo, pero no puede proporcionar al modelo conocimientos que aún no tiene. Los modelos de lenguaje se entrenan en grandes conjuntos de datos, pero esos datos de entrenamiento tienen una fecha límite y no incluyen la información privada de la organización. Cuando un modelo carece de contexto relevante, podría generar respuestas que son creíbles, pero son objetivamente incorrectas.
Para abordar este desafío, puede basar el modelo proporcionando datos fácticos pertinentes para basar sus respuestas. La generación aumentada de recuperación (RAG) es la técnica más común para la puesta en tierra de un modelo de lenguaje.
Comprender la puesta a tierra
Cuando se usa un modelo de lenguaje sin fundamentos, la única información que tiene procede de sus datos de entrenamiento. El resultado puede ser gramaticalmente correcto y estructurado lógicamente, pero puede ser inexacto o incluir detalles fabricados. Por ejemplo, preguntando "¿Qué hoteles ofrece en París?" sin datos de base podrían devolver nombres ficticios de hoteles.

Cuando fundamenta una solicitud, proporciona datos relevantes de un origen de confianza junto con la pregunta del usuario. A continuación, el modelo genera una respuesta basada en esos datos, lo que genera respuestas más precisas y contextualmente relevantes.
Tenga en cuenta la diferencia:
- Sin fundamento: el modelo se basa solo en sus datos de entrenamiento y puede inventar nombres o detalles de hoteles.
- Fundamentado: el modelo recibe los datos reales del catálogo de hoteles como contexto y responde con nombres reales de hoteles, precios y disponibilidad.

La contextualización mejora la precisión factual de las respuestas al conectar el modelo con información específica, actual y relevante para las necesidades del usuario.
Funcionamiento de RAG
RAG es un patrón que recupera información relevante de un origen de datos e la incluye en el mensaje antes de que el modelo genere una respuesta. El proceso sigue tres pasos:
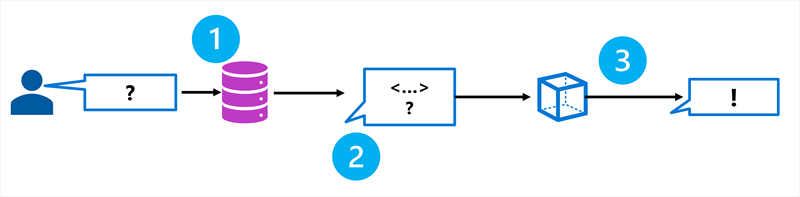
- Recuperar: busque un origen de datos para obtener información relevante para la pregunta del usuario.
- Aumentar: agregue la información recuperada al indicador como contexto.
- Generar: envíe el mensaje aumentado al modelo de lenguaje para generar una respuesta fundamentada.
Al recuperar el contexto de un origen de datos especificado, asegúrese de que el modelo usa información pertinente, up-to-date en lugar de confiar únicamente en sus datos de entrenamiento.
Creación de incrustaciones para la búsqueda
Un componente crítico de RAG es la capacidad de encontrar eficazmente la información más relevante en el origen de datos. Aquí es donde entran las incrustaciones y la búsqueda de vectores .
Una inserción es una representación matemática del texto como vector, una lista de números de punto flotante que captura el significado de palabras, oraciones o documentos. Para crear incrustaciones, envíe su contenido a un modelo de incrustación, como un modelo de incrustación de Azure OpenAI disponible en Microsoft Foundry.
Por ejemplo, imagine dos documentos:
- "Los niños jugaron alegremente en el parque".
- "Los niños corrieron felizmente por el parque infantil".
Estas oraciones usan palabras diferentes, pero tienen significados similares. Al crear incrustaciones para cada una, sus vectores están cerca en el espacio multidimensional, lo que refleja su similitud semántica.

La similitud coseno mide la proximidad de dos vectores calculando el ángulo entre ellos. Un valor cercano a 1 significa que los vectores son muy similares. Este enfoque matemático permite encontrar documentos relevantes incluso cuando las palabras exactas no coinciden.
Uso de Azure AI Search para la recuperación
Azure AI Search proporciona el componente de recuperación para soluciones RAG en Microsoft Foundry. Permite traer sus propios datos, crear un índice que se puede buscar y consultarlo para recuperar información relevante.

Para usar Azure AI Search con RAG, haga lo siguiente:
- Agregar los datos a Microsoft Foundry desde orígenes como Azure Blob Storage, Azure Data Lake Storage Gen2 o Microsoft OneLake. También puede cargar archivos directamente.
- Cree un índice mediante un modelo de inserción para generar representaciones vectoriales del contenido. El índice se almacena en Azure AI Search.
- Consulte el índice cuando un usuario haga una pregunta. El sistema convierte la pregunta en una inserción, busca el contenido más similar y devuelve los resultados pertinentes.
Azure AI Search admite varias técnicas de búsqueda:
- Búsqueda de palabras clave: coincide con los términos exactos de la consulta en el texto del índice.
- Búsqueda semántica: usa modelos semánticos para que coincidan con el significado de la consulta en lugar de palabras clave exactas.
- Búsqueda vectorial: usa incrustaciones para buscar contenido semánticamente similar.
- Búsqueda híbrida: combina la palabra clave, la semántica y la búsqueda de vectores para obtener los resultados más precisos. Se recomienda la búsqueda híbrida para aplicaciones de IA generativas.
Implementación de RAG con el Azure AI Foundry SDK
Después de crear un índice de Azure AI Search, puede conectarlo a un modelo a través del proyecto de Microsoft Foundry. El SDK de azure-ai-projects le permite obtener un cliente de OpenAI autenticado y usar la API de respuestas para generar respuestas fundamentadas.
El código de Python siguiente muestra una implementación básica:
from azure.ai.projects import AIProjectClient
from azure.identity import DefaultAzureCredential
project = AIProjectClient(
endpoint=os.environ["PROJECT_ENDPOINT"],
credential=DefaultAzureCredential(),
)
client = project.get_openai_client()
response = client.responses.create(
model="gpt-4o",
input=[
{"role": "system", "content": "You are a helpful travel advisor. "
"Use the following hotel data to answer: " + retrieved_context},
{"role": "user", "content": "Which hotels do you offer in Paris?"},
],
)
print(response.output_text)
En este ejemplo, retrieved_context representa los documentos devueltos desde el índice de Azure AI Search. Al insertar esos resultados en el mensaje del sistema, la respuesta del modelo se basa en los datos reales en lugar de su conocimiento general de entrenamiento.
Cuándo usar RAG
RAG es más eficaz cuando:
- El modelo necesita conocimientos específicos del dominio: Su organización tiene datos privados en los que el modelo no se ha entrenado, como un catálogo de productos, documentos de directivas o knowledge base internos.
- Cambios en la información con frecuencia: los datos se actualizan periódicamente, como el inventario, los precios o las noticias. RAG recupera los datos actuales en el momento de realizar la consulta sin volver a entrenar.
- La precisión fáctica es fundamental: necesita respuestas basadas en datos reales en lugar del conocimiento general del modelo.
- Los datos de entrenamiento del modelo base tienen un límite: los eventos o la información que se produjeron después de la fecha límite de entrenamiento del modelo deben ser accesibles.
Para el escenario de la agencia de viajes, RAG permite a los clientes formular preguntas sobre hoteles, destinos y directivas de reserva específicos, todo ello con base en los datos reales del catálogo de la agencia.
Sugerencia
Si está creando agentes que necesitan conocimientos sólidos sin administrar su propia infraestructura de búsqueda, considere Foundry IQ, un almacén de conocimientos gestionado que simplifica la base para los agentes de IA. Para más información, consulte Construya agentes de IA mejorados con conocimiento utilizando Foundry IQ.