Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Visualización actual:![]() Versión - Cambio a la versión del nuevo portal de Foundry
Versión - Cambio a la versión del nuevo portal de Foundry
En este artículo, aprenderá a usar el portal de Foundry para implementar un modelo Foundry en un recurso Foundry para inferencia. Los modelos Foundry incluyen modelos como los de Azure OpenAI, Meta Llama, y más. Después de implementar un modelo Foundry, puede interactuar con él en Foundry Playground y usarlo desde el código.
En este artículo se utiliza un Modelo de Foundry de socios y la comunidad Llama-3.2-90B-Vision-Instruct para ilustrarlo. Los modelos de asociados y comunidad requieren que se suscriba a Azure Marketplace antes de la implementación. Por otro lado, Foundry Models vendido directamente por Azure, como Azure OpenAI en Foundry Models, no tiene este requisito. Para obtener más información sobre los "Foundry Models", incluidas las regiones en las que están disponibles para su implementación, consulte Foundry Models vendidos directamente por Azure y Foundry Models de socios y la comunidad.
Requisitos previos
Para completar este artículo, necesita lo siguiente:
Una suscripción Azure con un método de pago válido. Si no tiene una suscripción de Azure, cree un cuenta de Azure de pago para comenzar. Si usa modelos de GitHub, puede upgrade a Foundry Models y crear una suscripción de Azure en el proceso.
El rol Colaborador de Cognitive Services o los permisos equivalentes del recurso Foundry necesarios para crear y administrar implementaciones. Para obtener más información, consulte Roles de RBAC de Azure.
Un proyecto Microsoft Foundry. Este tipo de proyecto se administra en un recurso Foundry.
Modelos Foundry de asociados y de la comunidad requieren acceso a Azure Marketplace para crear suscripciones. Asegúrese de que tiene los permisos necesarios para suscribirse a las ofertas de modelo. Modelos Foundry vendidos directamente por Azure no tienen este requisito.
Implementación de un modelo
Implemente un modelo siguiendo estos pasos en el portal de Foundry:
-
Inicie sesión en Microsoft Foundry. Asegúrese de que el interruptor New Foundry está desactivado. Estos pasos hacen referencia a Foundry (clásico).

Vaya a la sección Catálogo de modelos en el portal de Foundry.
Seleccione un modelo y revise sus detalles en la tarjeta del modelo. En este artículo se usa
Llama-3.2-90B-Vision-Instructpara ilustrarlo.Seleccione Usar este modelo.
Para Foundry Models de socios y comunidad, debe suscribirse a Azure Marketplace. Este requisito se aplica a
Llama-3.2-90B-Vision-Instruct, por ejemplo. Lea los términos de uso y seleccione Aceptar y Continuar para aceptar los términos.Nota
Para Foundry Models vendidos directamente por Azure, como el modelo Azure OpenAI
gpt-4o-mini, no se suscribe a Azure Marketplace.Configure las opciones de implementación:
- De forma predeterminada, la implementación usa el nombre del modelo. Puede modificar este nombre antes de la implementación.
- Durante la inferencia, el nombre de implementación se usa en el
modelparámetro para enrutar las solicitudes a esta implementación determinada.
Propina
Cada modelo admite diferentes tipos de implementación, lo que proporciona garantías de residencia o rendimiento de datos diferentes. Consulte Tipos de implementación para obtener más detalles. En este ejemplo, el modelo admite el tipo de implementación Global Standard.
El portal de Foundry selecciona automáticamente el recurso Foundry asociado al proyecto como recurso de IA conectada. Seleccione Personalizar para cambiar la conexión si es necesario. Si va a desplegar en el tipo de implementación API sin servidor, el proyecto y el recurso deben estar en una de las regiones admitidas de implementación para el modelo.
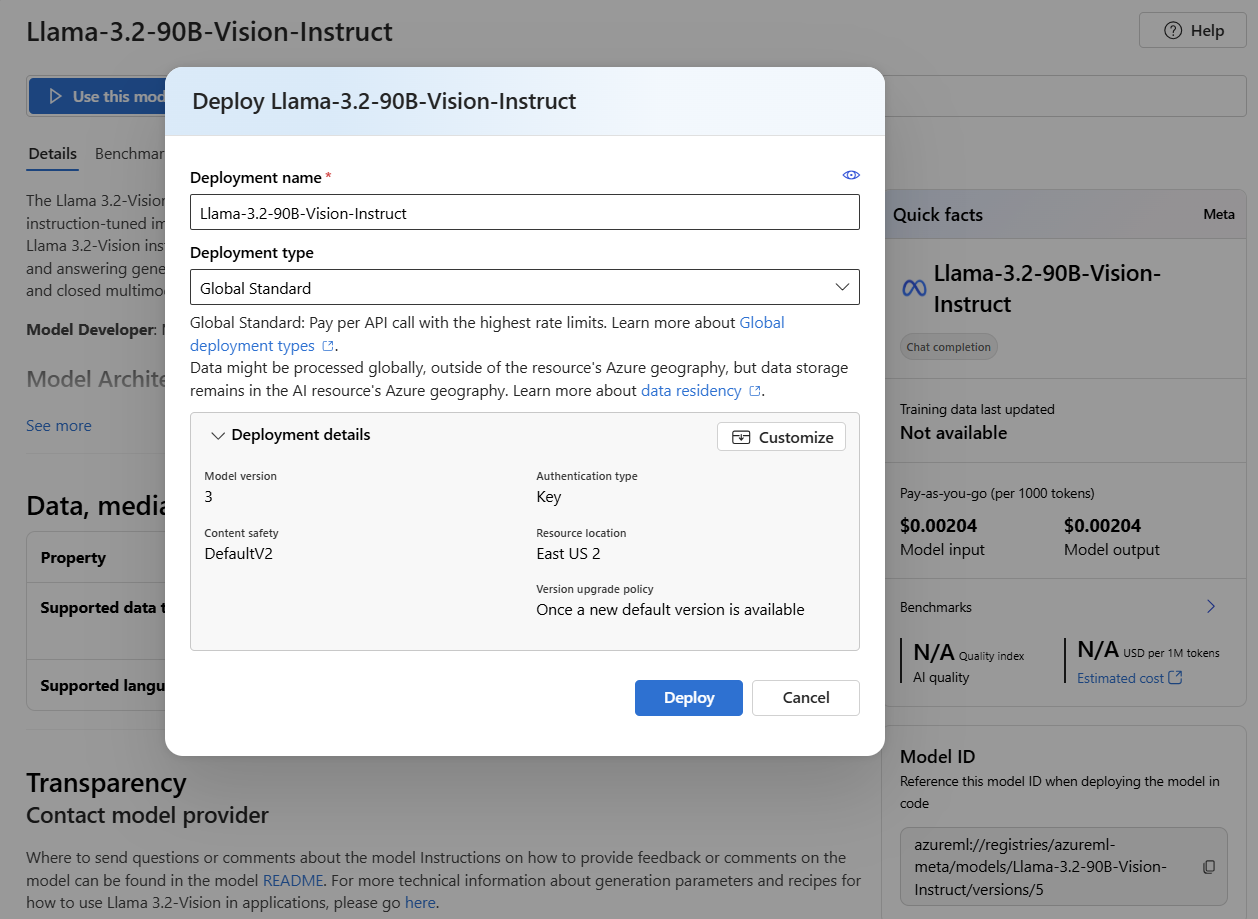
Seleccione Implementar. La página de detalles de implementación del modelo se abre durante la creación de la implementación.
Una vez completada la implementación, el modelo está listo para su uso. También puede usar foundry Playgrounds para probar interactivamente el modelo.

Administrar modelos
Puede administrar las implementaciones de modelos existentes en el recurso mediante el portal de Foundry.
Vaya a la sección Modelos y puntos de conexión en el portal de Foundry.
El portal agrupa y muestra implementaciones de modelos por recurso. Seleccione en la sección de su recurso Foundry la implementación del modelo Llama-3.2-90B-Vision-Instruct. Esta acción abre la página de implementación del modelo.


Prueba de la implementación en el área de juegos
Puede interactuar con el nuevo modelo en el portal de Foundry mediante el área de juegos. El área de juegos es una interfaz basada en web que le permite interactuar con el modelo en tiempo real. Use el área de juegos para probar el modelo con diferentes avisos y ver las respuestas del modelo.
En la página de implementación del modelo, seleccione Abrir en el área de juegos. Esta acción abre el entorno de pruebas de chat con el nombre de la implementación ya seleccionada.

Escriba su mensaje y vea los resultados.
Utilice Ver código para ver detalles sobre cómo acceder a la implementación del modelo programáticamente.

Uso del modelo con código
Para ejecutar la inferencia en el modelo implementado, consulte los ejemplos siguientes:
Para usar la API Responses con Modelos Foundry vendidos directamente por Azure, como los modelos de AI de Microsoft, DeepSeek y Grok, consulte el documento 'Cómo generar respuestas de texto con modelos de Microsoft Foundry'.
Para usar la API de respuestas con modelos openAI, consulte Introducción a la API de respuestas.
Para usar la API de finalizaciones de chat con modelos vendidos por asociados, como el modelo llama implementado en este artículo, consulte Compatibilidad de modelos con finalizaciones de chat.
Límites de disponibilidad regional y cuota de un modelo
Para Foundry Models, la cuota predeterminada varía según el modelo y la región. Es posible que algunos modelos solo estén disponibles en algunas regiones. Para obtener más información sobre los límites de disponibilidad y cuota, consulte las cuotas y límites de los Modelos de Fundición de Microsoft Azure OpenAI y las cuotas y límites de los Modelos de Fundición de Microsoft.
Cuota para implementar y ejecutar la inferencia en un modelo
En el caso de los modelos de Foundry, la implementación y ejecución de la inferencia consumen cuota que Azure asigna a la suscripción por región y por modelo en unidades de tokens por minuto (TPM). Cuando te inscribas en Foundry, recibirás la cuota predeterminada para la mayoría de los modelos disponibles. A continuación, asigna TPM a cada implementación a medida que las creas, lo que reduce la cuota disponible para ese modelo. Puede seguir creando implementaciones y asignarlas a TPMs hasta alcanzar el límite de cuota.
Al alcanzar el límite de cuota, solo puede crear nuevas implementaciones de ese modelo si:
- Solicite más cuota mediante el envío de un formulario de aumento de cuota.
- Ajuste la cuota asignada en otras implementaciones de modelos en el portal de Foundry para liberar tokens para nuevas implementaciones.
Para obtener más información sobre la cuota, consulte Cuotas y límites de los modelos de Foundry de Microsoft y Administrar la cuota de Azure OpenAI.
Solución de problemas
| Problema | Resolución |
|---|---|
| Cuota superada | Solicitar más cuota o reasignar TPM a partir de implementaciones existentes. |
| Región no admitida | Compruebe la disponibilidad regional e implemente en una región admitida. |
| Error de suscripción de Marketplace | Compruebe que tiene los permisos required para suscribirse a ofertas de Azure Marketplace. |
| Estado de implementación muestra Error | Confirme que el modelo está disponible en la región seleccionada y que tiene cuota suficiente. |