Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Calidad de datos de Microsoft Purview para orígenes de datos locales permite a las organizaciones evaluar, supervisar y mejorar la calidad de los datos almacenados en sistemas internos, como bases de datos y plataformas heredadas. Admite flujos de trabajo de validación, detección de errores y corrección basados en reglas, a la vez que garantiza el cumplimiento de las directivas de la organización. Al integrarse con la infraestructura existente, proporciona información coherente sobre la calidad de los datos y la gobernanza en entornos locales y en la nube.
Mediante el uso de un entorno de ejecución de integración de datos autohospedado, puede escalar los procesos de calidad de datos mediante la conexión segura de orígenes de datos locales a Purview. En este artículo se describe el entorno de ejecución de integración de datos autohospedado basado en Kubernetes, Linux, que mejora la infraestructura subyacente y proporciona varias ventajas clave:
- Escalabilidad: capacidad de escalar a cientos de máquinas.
- Rendimiento: rendimiento mejorado para el examen de cargas de trabajo.
- Seguridad (en contenedores): habilita la implementación en contenedores en un clúster de Kubernetes, lo que elimina la necesidad de hospedar el entorno de ejecución de integración de datos directamente en una máquina Windows.
Orígenes de datos admitidos
- Oracle
- SQL Server
Arquitectura
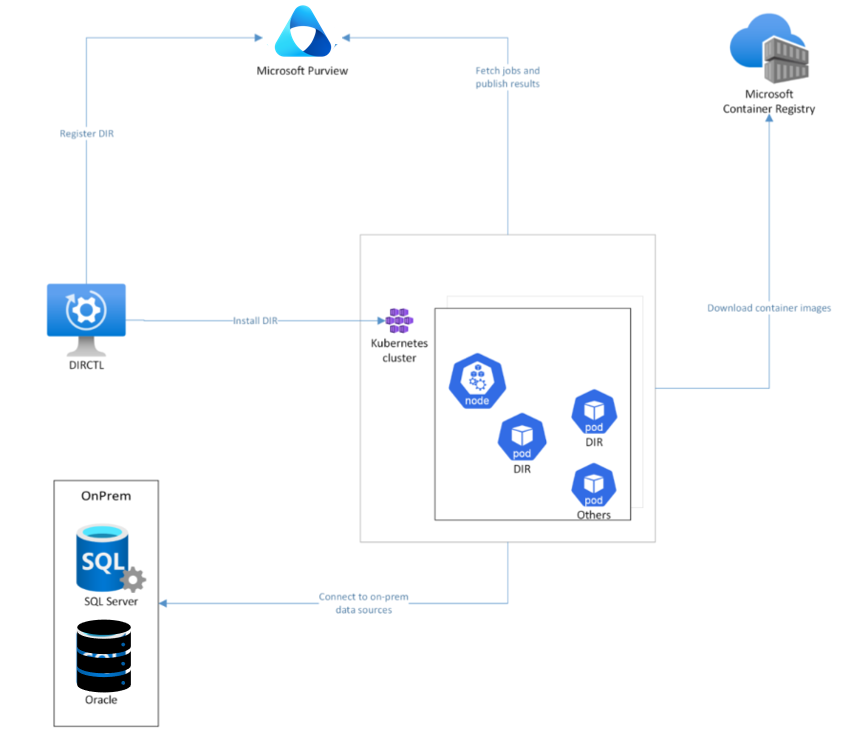
En una vista arquitectónica de alto nivel, al instalar un entorno de ejecución de integración de datos basado en Kubernetes, se crean automáticamente varios pods en los nodos del clúster de Kubernetes. Una herramienta de línea de comandos denominada DIRCTL desencadena esta instalación. DIRCTL se conecta a Microsoft Purview Service para registrar el entorno de ejecución de integración de datos y conectarse al clúster de Kubernetes para instalar el entorno de ejecución de integración de datos autohospedado.
Durante la instalación, el proceso descarga imágenes del entorno de ejecución de integración de datos de MCR (Registros de contenedor de Microsoft) en los pods del entorno de ejecución de integración de datos. Una vez finalizada la instalación, los pods del clúster se conectan al servicio Purview para extraer trabajos de examen. A medida que se extrae un trabajo de detección, puede conectar el origen de datos local para el examen de calidad de datos.
Requisitos previos
Integración de datos herramienta línea de comandos en tiempo de ejecución (DIRCTL)
Necesita la herramienta de línea de comandos en tiempo de ejecución de Integración de datos (DIRCTL) para configurar el entorno de ejecución de integración de datos. Para obtener instrucciones de descarga e instalación, consulte Configuración de la herramienta DIRCTL para el entorno de ejecución de integración autohospedado (versión preliminar).
Funciones
Para configurar un entorno de ejecución integrado autohospedado en Purview, necesita el rol Administrador de gobernanza de datos.
Clúster de Kubernetes
Necesita un clúster de Kubernetes basado en Linux existente o debe preparar uno. Identifique los nodos mediante un selector de nodos, que sigue la definición del selector de nodos de Kubernetes. Configuración mínima:
- Tipo de contenedor: Linux
- Versión de Kubernetes: 1.24.9 o posterior
- Sistema operativo de nodo: sistema operativo basado en Linux que se ejecuta en la arquitectura x86
- Especificación de nodo: CPU mínima de ocho núcleos, 32 GB de memoria y al menos 80 GB de espacio disponible en disco duro
- Recuento de nodos: 1 o más (escalador automático de clústeres fijo y no habilitado)
- Número de pod por nodo: 20 o más (número máximo de pods: recuento de otros pods que no pertenecen a Self-Hosted IR)
Nota:
La carpeta /var/irstorage/ de cada nodo está reservada para el entorno de ejecución integrado autohospedado. Se puede leer y escribir en el entorno de ejecución de integración de datos. Puede obtener registros de esta carpeta o cargar controladores externos en esta carpeta. Data Integration Runtime crea la carpeta si no existe y no elimina la carpeta después de eliminar el entorno de ejecución de integración de datos. Las imágenes de contenedor que usa Data Integration Runtime se administran mediante la recolección de elementos no utilizados de Kubernetes, que no se limpia mediante el entorno de ejecución de integración de datos. Configure el umbral adecuado para el clúster de Kubernetes.
La conectividad saliente es necesaria para extraer imágenes de contenedor, así como para realizar operaciones adicionales, lo que incluye actividades como la extracción de trabajos de calidad de datos y la inserción de estadísticas generadas.
Contexto de Kubernetes
El contexto de Kubernetes, que contiene información del clúster de Kubernetes y los permisos y credenciales del usuario para este clúster, es necesario para comunicarse con el clúster de Kubernetes. Para facilitar la configuración de los permisos del usuario para la administración de DIR, puede empezar con el rol Administración de Kubernetes. Este contexto se genera con la configuración del clúster de Kubernetes y se guarda en un archivo de configuración. Dónde y cómo puede obtener este archivo depende de la configuración del clúster de Kubernetes.
Si usa kubeadm init para configurar el clúster de Kubernetes, puede encontrar el archivo de configuración en
/etc/Kubernetes/admin.conf.Si usa AKS, puede seguir las instrucciones de AKS para usar el comando az del módulo de PowerShell para obtener las credenciales de este clúster en el equipo local. Puede combinar el contexto con el archivo de configuración en
$HOME/.kube/configdirectamente.Si usa otras herramientas para configurar un clúster de Kubernetes, consulte la documentación de Kubernetes.
Después de obtener el archivo de configuración para el contexto de Kubernetes, combínelo en el archivo
$HOME/.kube/configde configuración de la máquina donde desea ejecutar el comando IRCTL. O bien, puede establecer el archivo de configuración del contexto de Kubernetes en una variable de entorno denominadaKUBECONFIG. Para obtener más información sobre el contexto de Kubernetes, consulte cómo configurar el acceso a varios clústeres.
Configuración de un entorno de ejecución de integración de datos autohospedado
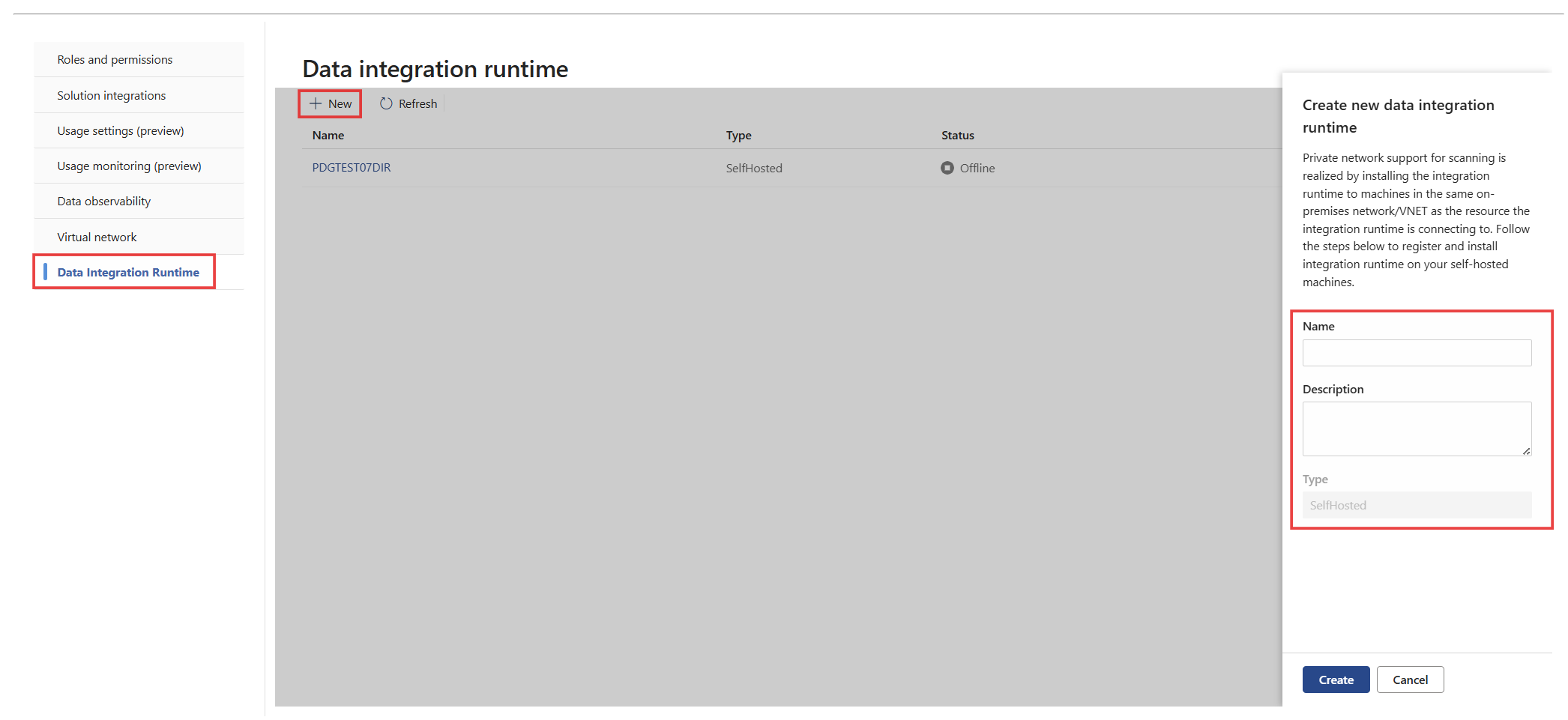
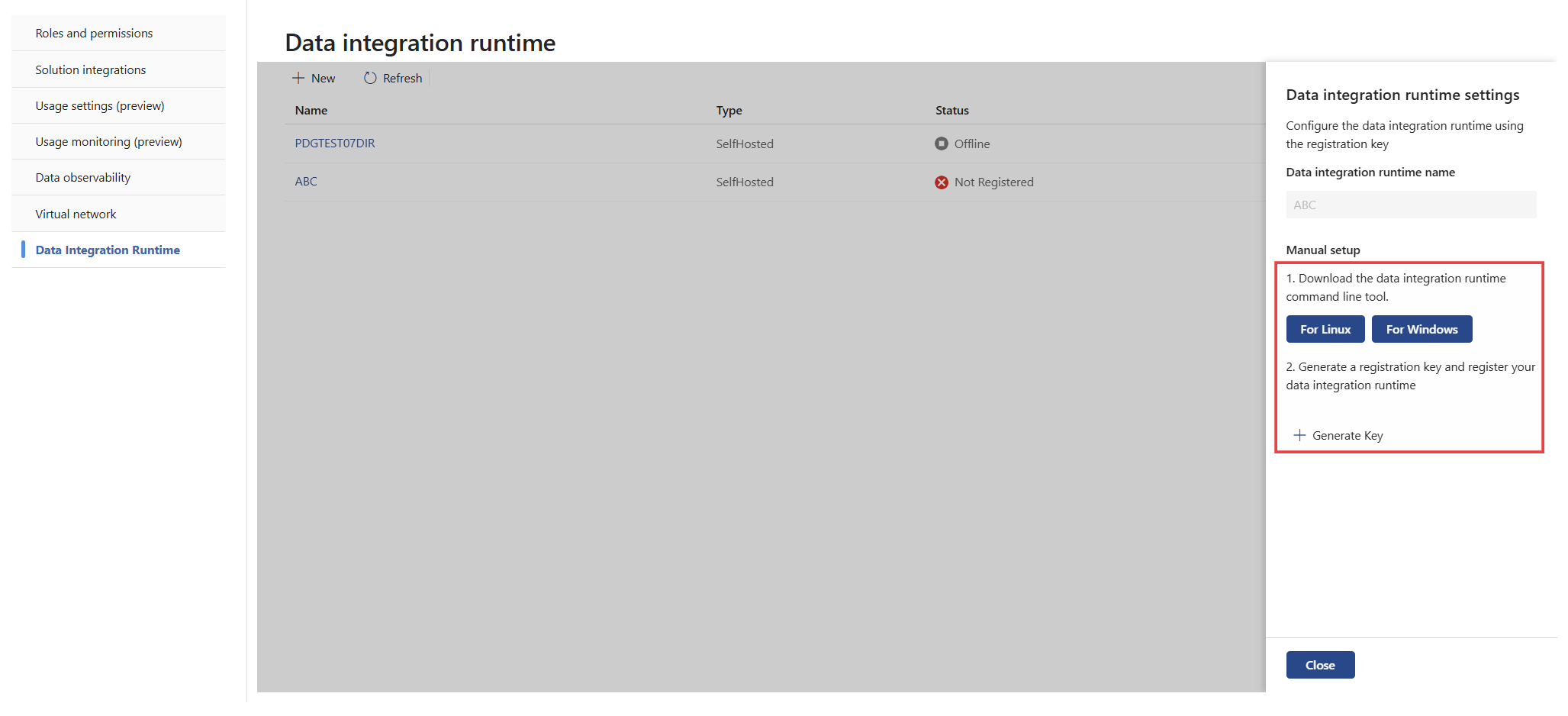
Vaya a Configuración>Catálogo unificado de Microsoft Purview>Integración de datos Tiempo de ejecución y, a continuación, seleccione Nuevo para crear un entorno de ejecución de integración de datos.
Escriba un nombre y una descripción para el entorno de ejecución integrado autohospedado y, a continuación, seleccione Crear.
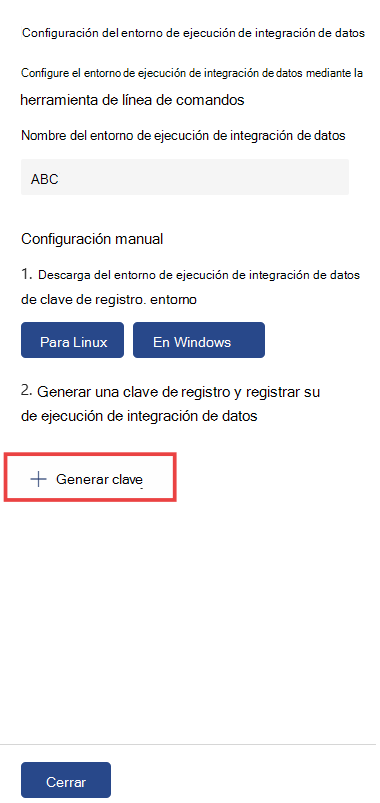
Seleccione Generar clave para generar una clave de registro y registrar el entorno de ejecución de integración de datos.
Copie el valor de clave y seleccione Listo.
Sugerencia
Si es necesario, puede volver a generar una clave o revocar una clave generada.
Seleccione For Linux to download the Integración de datos Runtime Command Line (DIRCTL) tool (Línea de comandos en tiempo de ejecución de Integración de datos ( DIRCTL). Obtenga detalles sobre cómo instalar y administrar DIRCTL.
En la máquina en la que desea ejecutar la línea de comandos DIRCTL, instale DIRCTL desde la descarga. DIRCTL se conecta al clúster de Kubernetes mediante el contexto de la configuración de Kube. Si no especifica un contexto, DIRCTL usa el contexto actual. Puede establecer el contexto de una de estas dos maneras:
- Ejecute
kubectlla línea de comandos y ejecute este comando para confirmar el contexto actual:-
kubectl config get-contexts: enumera todos los contextos configurados en la máquina -
kubectl config current-context: obtenga el nombre del contexto actual. kubectl config use-context <name of context>
-
- Ejecute DIRCTL y ejecútelo
-contextpara especificar el contexto en la configuración de Kube.
- Ejecute
Ejecute el comando DIRCTL Create:
./DIRCTL create - -registration-key <registration-key copied from the portal>. El comando DIRCTL Create registra un nuevo entorno de ejecución de integración de datos con Data Quality e inicia la creación de una aplicación en Kubernetes como un pod específico del entorno de ejecución de integración de datos registrado. Controla el aprovisionamiento de recursos y la configuración esenciales para la funcionalidad del entorno de ejecución de integración de datos, a la vez que mantiene la compatibilidad con los requisitos del sistema existentes.
Una vez finalizado el registro, puede comprobar el estado del entorno de ejecución de integración de datos en la página Integración de datos runtime de Configuración. El estado se muestra como En línea. También puede comprobar el estado del entorno de ejecución de integración de datos ejecutando este comando: ./DIRCTL describe.
Sugerencia
Estos son los puntos de conexión públicos a los que se conecta Data Integration Runtime que deben permitirse en la lista:
- < >purview_account_name.purview.azure.com
- Mcr.microsoft.com
- *.data.mcr.microsoft.com
Configuración de la conexión del origen de datos local con Data Integration Runtime
Conexión a la base de datos de Oracle
Cree conexiones asociándolas a una instancia de Data Integration Runtime.
- En Catálogo unificado, vaya a Calidad de los datos de administración de>estado.
- Seleccione el dominio de gobernanza donde creó el producto de datos con el recurso de datos de Oracle.
- Seleccione Administrar y, a continuación, seleccione Conexión para configurar la conexión para la base de datos de Oracle.
Agregue la siguiente información para configurar la conexión:
- Escriba un nombre para mostrar para la conexión.
- Escriba una descripción.
- En Tipo de origen, seleccione Oracle.
- Seleccione el entorno de ejecución de integración de datos que creó como parte del requisito previo.
- Escriba el nombre de host .
- Escriba el número de puerto .
- Escriba el nombre del servicio.
- Escriba el nombre del esquema.
- Seleccione un método de autenticación.
- Escriba el nombre de usuario.
- En Credencial, escriba la suscripción Azure, Azure Key Vault conexión, Nombre secreto y Versión secreta.
- Seleccione Enviar para completar la configuración de conexión.
Sugerencia
Si no tiene toda la información necesaria, seleccione Guardar como borrador para continuar más adelante cuando tenga el resto de la información para completar la configuración de conexión.
En esta imagen se muestra cómo crear una conexión:

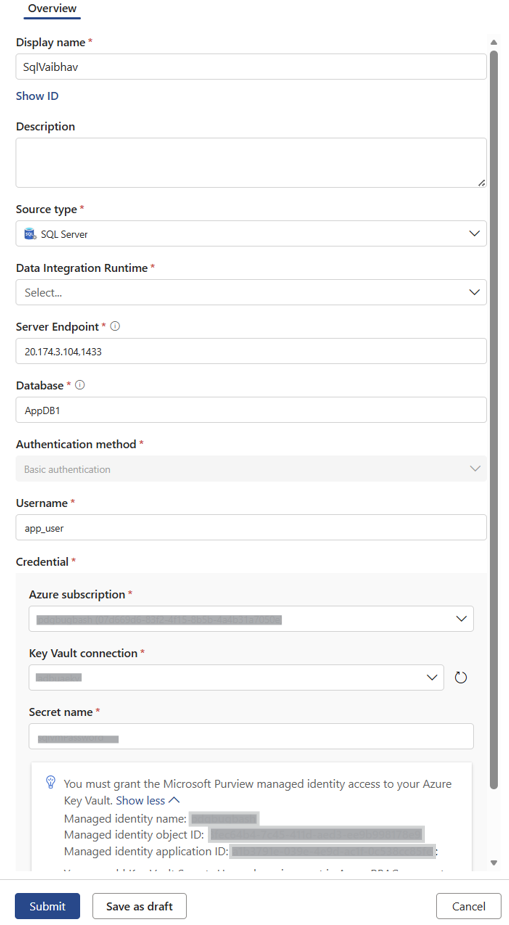
Conexión a la base de datos de SQL Server
Cree conexiones asociándolas a una instancia de Data Integration Runtime, al igual que para Oracle. En SQL Server, una base de datos única puede contener tablas que pertenecen a varios esquemas, por lo que puede usar una única conexión para examinar todos los esquemas de una sola base de datos. Una conexión solo acepta información de base de datos, pero no esquema. Cree conexiones para SQL Server igual que para otros tipos de orígenes de datos.
- En Catálogo unificado, vaya a Calidad de los datos de administración de>estado.
- Seleccione el dominio de gobernanza donde creó el producto de datos con el recurso de datos de Oracle.
- Seleccione Administrar y, a continuación, seleccione Conexión para configurar la conexión para la base de datos de Oracle.
Agregue la siguiente información para configurar la conexión correctamente:
- Escriba un nombre para mostrar para la conexión.
- Escriba una descripción.
- En Tipo de origen, seleccione SQL Server.
- Seleccione el entorno de ejecución de integración de datos que creó como parte del requisito previo.
- Escriba el punto de conexión del servidor.
- Escriba el nombre de la base de datos .
- Seleccione un método de autenticación.
- Escriba el nombre de usuario.
- En Credencial, escriba la suscripción Azure, Azure Key Vault conexión y El nombre del secreto.
- Seleccione Enviar para completar la configuración de conexión.
Sugerencia
Si no tiene toda la información necesaria, seleccione Guardar como borrador para continuar más adelante cuando tenga el resto de la información para completar la configuración de conexión.
En esta imagen se muestra cómo crear una conexión:
Examen de calidad de datos
Después de completar la configuración de conexión, siga la generación de perfiles de calidad de datos y el examen de documentos para medir y supervisar la calidad de los datos de Oracle y SQL Server orígenes de datos locales.
- Información general sobre la calidad de los datos
- Orígenes de datos admitidos
- Configuración de la conexión del origen de datos
- Examen de calidad del producto de datos
- Examen de calidad de recursos de datos
- Examen incremental de calidad de datos
Alta disponibilidad y escalabilidad
Asigne varios nodos en el clúster de Kubernetes para lograr alta disponibilidad mediante el selector de nodos durante la instalación del entorno de ejecución de integración autohospedado compatible con Kubernetes. Las ventajas de tener varios nodos incluyen:
Mayor disponibilidad del entorno de ejecución de integración autohospedado para que no sea un único punto de error para los exámenes.
Más exámenes simultáneos. Cada nodo puede controlar muchas ejecuciones de examen al mismo tiempo. Puede escalar horizontalmente manualmente los nodos del clúster de Kubernetes si necesita más exámenes simultáneos.
Al examinar algunos orígenes, como Azure Blob, Azure Data Lake Storage Gen2 y Azure Files, cada ejecución de examen puede usar varios nodos para mejorar el rendimiento del examen. Para otros orígenes, los exámenes solo se ejecutan en uno de los nodos.
Puede actualizar las funcionalidades del entorno de ejecución de integración autohospedado compatible con Kubernetes mediante el escalado horizontal o escalado horizontal manual de los nodos del clúster de Kubernetes.
Nota:
Debe cargar todos los controladores necesarios para el examen en cada nuevo nodo.
Requisito de red
| Nombre de dominio | Puerto de salida | Description |
|---|---|---|
Nube pública: <tenantID>-api.purview-service.microsoft.com Azure Government: <tenantID>-api.purview-service.microsoft.us China: <tenantID>-api.purview-service.microsoft.cn |
443 | Necesario para conectarse al servicio Microsoft Purview. Si usa puntos de conexión privados de Microsoft Purview, el punto de conexión privado de la cuenta cubre este punto de conexión. |
Nube pública: <purview_account>.purview.azure.com Azure Government: <purview_account>.purview.azure.us China: <purview_account>.purview.azure.cn |
443 | Necesario para conectarse al servicio Microsoft Purview. Si usa puntos de conexión privados de Microsoft Purview, el punto de conexión privado de la cuenta cubre este punto de conexión. |
| mcr.microsoft.com | 443 | Necesario para descargar imágenes. |
| *.data.mcr.microsoft.com | 443 | Necesario para descargar imágenes. |