Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Los cuadernos de Jupyter Notebook proporcionan un entorno interactivo para explorar, analizar y visualizar datos en el lago de datos Microsoft Sentinel y las tablas federadas. Con los cuadernos, puede escribir y ejecutar código, documentar el flujo de trabajo y ver los resultados, todo en un solo lugar. Esto facilita la exploración de datos, la compilación de soluciones de análisis avanzados y el uso compartido de información con otros usuarios. Al aprovechar Python y Apache Spark dentro de Visual Studio Code, los cuadernos le ayudan a transformar los datos de seguridad sin procesar en inteligencia accionable.
En este artículo se muestra cómo explorar e interactuar con datos de Data Lake mediante cuadernos de Jupyter Notebook en Visual Studio Code.
Requisitos previos
Incorporación al lago de datos Microsoft Sentinel
Para usar cuadernos en el lago de datos Microsoft Sentinel, primero debe incorporarlos al lago de datos. Si no se ha incorporado al lago de datos de Sentinel, consulte Incorporación a Microsoft Sentinel lago de datos. Si se ha incorporado recientemente al lago de datos, puede tardar algún tiempo hasta que se ingiere suficiente volumen de datos para poder crear análisis significativos mediante cuadernos.
Permissions
Microsoft Entra ID roles proporcionan un acceso amplio a todas las áreas de trabajo del lago de datos. También puede conceder acceso a áreas de trabajo individuales mediante Azure roles de RBAC. Los usuarios con Azure permisos de RBAC para Microsoft Sentinel áreas de trabajo pueden ejecutar cuadernos en esas áreas de trabajo en el nivel de lago de datos. Para obtener más información, vea Roles y permisos en Microsoft Sentinel.
Opcionalmente, Microsoft Sentinel ámbito o RBAC de nivel de fila se puede configurar para restringir aún más el acceso a los datos dentro de un área de trabajo. Cuando está habilitado, el ámbito de nivel de fila limita los datos devueltos por las consultas en función del ámbito asignado por el usuario. Si el ámbito de nivel de fila no está configurado, el modelo de permisos de nivel de área de trabajo existente se aplica sin cambios. Para obtener más información, vea Configurar Microsoft Sentinel ámbito (RBAC de nivel de fila) (versión preliminar).
Para crear nuevas tablas personalizadas en el nivel de análisis, se debe asignar a la identidad administrada de Data Lake el rol Colaborador de Log Analytics en el área de trabajo de Log Analytics.
Para asignar el rol, siga estos pasos:
- En el Azure Portal, vaya al área de trabajo de Log Analytics a la que desea asignar el rol.
- Seleccione Control de acceso (IAM) en el panel de navegación izquierdo.
- Seleccione Agregar asignación de roles.
- En la tabla Rol, seleccione Colaborador de Log Analytics y, a continuación, seleccione Siguiente.
- Seleccione Identidad administrada y seleccione Seleccionar miembros.
- La identidad administrada de Data Lake es una identidad administrada asignada por el sistema denominada
msg-resources-<guid>. Seleccione la identidad administrada y seleccione Seleccionar. - Seleccione Revisar y asignar.
Para obtener más información sobre cómo asignar roles a identidades administradas, consulte Asignación de roles Azure mediante el Azure Portal.
Instalar Visual Studio Code y la extensión Microsoft Sentinel
Si aún no tiene Visual Studio Code, descargue e instale Visual Studio Code para Mac, Linux o Windows.
La extensión de Microsoft Sentinel para Visual Studio Code (VS Code) se instala desde marketplace de extensiones. Para instalar la extensión, siga estos pasos:
- Seleccione el Marketplace extensiones en la barra de herramientas de la izquierda.
- Busque Sentinel.
- Seleccione la extensión Microsoft Sentinel y seleccione Instalar.
- Una vez instalada la extensión, aparece el icono de escudo de Microsoft Sentinel en la barra de herramientas izquierda.

Instale la extensión de GitHub Copilot para Visual Studio Code para habilitar la finalización de código y sugerencias en cuadernos.
- Busque GitHub Copilot en Marketplace de extensiones e instálelo.
- Después de la instalación, inicie sesión en GitHub Copilot con su cuenta de GitHub.
Exploración de tablas de niveles de Data Lake
Después de instalar la extensión Microsoft Sentinel, puede empezar a explorar las tablas de niveles de Data Lake y crear cuadernos de Jupyter Notebook para analizar los datos.
Inicio de sesión en la extensión Microsoft Sentinel
Seleccione el icono de escudo de Microsoft Sentinel en la barra de herramientas izquierda.
Aparece un cuadro de diálogo con el texto siguiente La extensión "Microsoft Sentinel" quiere iniciar sesión con Microsoft. Seleccione Permitir.

Seleccione el nombre de la cuenta para completar el inicio de sesión.

Si tiene varias cuentas de invitado asociadas a su inicio de sesión, puede cambiar sin problemas entre cuentas. Para cambiar entre cuentas, seleccione el nombre de la cuenta en la parte inferior izquierda de la ventana de Visual Studio Code. Solo se puede seleccionar una cuenta a la vez.

Importante
Al cambiar entre cuentas, se desconectan las sesiones de pyspark activas.



Visualización de tablas y trabajos de Data Lake
Una vez que inicie sesión, la extensión Sentinel muestra una lista de tablas y trabajos de Lake en el panel izquierdo. Las tablas se agrupan por la base de datos y la categoría. Las tablas federadas se muestran en la categoría Tablas federadas en Tablas del sistema. Seleccione una tabla para ver las definiciones de columna.
Para obtener información sobre los trabajos, vea Trabajos y programación. Para obtener más información sobre las tablas federadas, consulte Uso de tablas federadas en el lago de datos de Microsoft Sentinel.

Creación de un cuaderno
Para crear un cuaderno, use uno de los métodos siguientes.
Escriba > en el cuadro de búsqueda o presione Ctrl+Mayús+P y, a continuación, escriba Crear nuevo Jupyter Notebook.

Seleccione Archivo > nuevo archivo y, a continuación, seleccione Jupyter Notebook en la lista desplegable.

En el nuevo cuaderno, pegue el código siguiente en la primera celda.
from sentinel_lake.providers import MicrosoftSentinelProvider data_provider = MicrosoftSentinelProvider(spark) table_name = "EntraGroups" df = data_provider.read_table(table_name) df.select("displayName", "groupTypes", "mail", "mailNickname", "description", "tenantId").show(100, truncate=False)


El editor proporciona la finalización de código de IntelliSense para la MicrosoftSentinelProvider clase y los nombres de tabla en el lago de datos.
Seleccione el triángulo Ejecutar para ejecutar el código en el cuaderno. Los resultados se muestran en el panel de salida debajo de la celda de código.

Seleccione Microsoft Sentinel en la lista para obtener una lista de grupos en tiempo de ejecución.
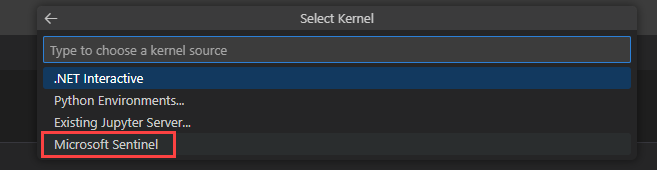
Seleccione Medio para ejecutar el cuaderno en el grupo de tiempo de ejecución de tamaño medio. Para obtener más información sobre los distintos tiempos de ejecución, consulte Selección del entorno de ejecución de Microsoft Sentinel adecuado.
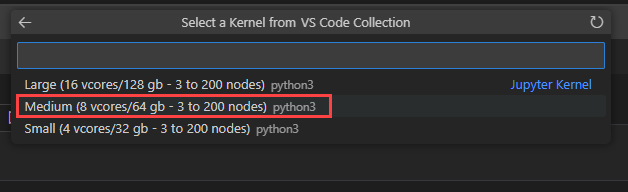



Nota:
Al seleccionar el kernel, se inicia la sesión de Spark y se ejecuta el código en el cuaderno. Después de seleccionar el grupo, la sesión puede tardar entre 3 y 5 minutos en iniciarse. Posteriormente se ejecuta más rápido, ya que la sesión ya está activa.
Cuando se inicia la sesión, se ejecuta el código del cuaderno y los resultados se muestran en el panel de salida debajo de la celda de código, por ejemplo: 
Para ver cuadernos de ejemplo que muestran cómo interactuar con el lago de datos de Microsoft Sentinel, consulte Cuadernos de ejemplo para Microsoft Sentinel lago de datos.
Barra de estado
La barra de estado de la parte inferior del cuaderno proporciona información sobre el estado actual del cuaderno y la sesión de Spark. La barra de estado incluye la siguiente información:
Porcentaje de uso de núcleo virtual para el grupo de Spark seleccionado. Mantenga el puntero sobre el porcentaje para ver el número de núcleos virtuales usados y el número total de núcleos virtuales disponibles en el grupo. Los porcentajes representan el uso actual en cargas de trabajo interactivas y de trabajo para la cuenta que ha iniciado sesión.
Estado de conexión de la sesión de Spark, por ejemplo
Connecting, ,ConnectedoNot Connected.

Establecer tiempos de espera de sesión
Puede establecer las advertencias de tiempo de espera y tiempo de espera de sesión para cuadernos interactivos. Para cambiar el tiempo de espera, seleccione el estado de conexión en la barra de estado de la parte inferior del cuaderno. Seleccione una de las opciones siguientes:
Establecer período de tiempo de espera de sesión: establece el tiempo en minutos antes de que se agote el tiempo de espera de la sesión. El valor predeterminado es 30 minutos.
Restablecer período de tiempo de espera de sesión: restablece el tiempo de espera de la sesión al valor predeterminado de 30 minutos.
Establecer período de advertencia de tiempo de espera de sesión: establece el tiempo en minutos antes del tiempo de espera en que se muestra una advertencia de que la sesión está a punto de agotarse el tiempo de espera. El valor predeterminado es 5 minutos.
Restablecer período de advertencia de tiempo de espera de sesión: restablece la advertencia de tiempo de espera de sesión al valor predeterminado de 5 minutos.


Uso de GitHub Copilot en cuadernos
Use GitHub Copilot para ayudarle a escribir código en cuadernos. GitHub Copilot proporciona sugerencias de código y autocompletar en función del contexto del código. Para usar GitHub Copilot, asegúrese de que tiene instalada la extensión GitHub Copilot en Visual Studio Code.
Copie el código de los cuadernos de ejemplo para Microsoft Sentinel data lake y guárdelo en la carpeta notebooks para proporcionar contexto para GitHub Copilot. GitHub Copilot podrá sugerir finalizaciones de código en función del contexto del cuaderno.
En el ejemplo siguiente se muestra GitHub Copilot generar una revisión de código.

Microsoft Sentinel clase Provider
Para conectarse al lago de datos de Microsoft Sentinel, use la SentinelLakeProvider clase .
Esta clase forma parte del access_module.data_loader módulo y proporciona métodos para interactuar con el lago de datos. Para usar esta clase, impórela y cree una instancia de la clase mediante una spark sesión.
from sentinel_lake.providers import MicrosoftSentinelProvider
data_provider = MicrosoftSentinelProvider(spark)
Para obtener más información sobre los métodos disponibles, vea Microsoft Sentinel referencia de clase Provider.
Seleccione el grupo de tiempo de ejecución adecuado.
Hay tres grupos en tiempo de ejecución disponibles para ejecutar los cuadernos de Jupyter Notebook en la extensión Microsoft Sentinel. Cada grupo está diseñado para diferentes cargas de trabajo y requisitos de rendimiento. La elección del grupo de tiempo de ejecución afecta al rendimiento, el costo y el tiempo de ejecución de los trabajos de Spark.
| Grupo en tiempo de ejecución | Casos de uso recomendados | Características |
|---|---|---|
| Small | Desarrollo, pruebas y análisis exploratorio ligero. Cargas de trabajo pequeñas con transformaciones sencillas. Rentabilidad priorizada. |
Adecuado para cargas de trabajo pequeñas Transformaciones sencillas. Menor costo, tiempo de ejecución más largo. |
| Medio | Trabajos ETL con combinaciones, agregaciones y entrenamiento de modelos de ML. Cargas de trabajo moderadas con transformaciones complejas. |
Rendimiento mejorado con respecto a Small. Controla el paralelismo y las operaciones moderadas que consumen mucha memoria. |
| Large | Cargas de trabajo de aprendizaje profundo y aprendizaje automático. Escalofríos de datos extensos, combinaciones grandes o procesamiento en tiempo real. Tiempo de ejecución crítico. |
Alta capacidad de proceso y memoria. Retrasos mínimos. Lo mejor para cargas de trabajo grandes, complejas o temporales. |
Nota:
Cuando se accede por primera vez, las opciones del kernel pueden tardar unos 30 segundos en cargarse.
Después de seleccionar un grupo en tiempo de ejecución, la sesión puede tardar entre 3 y 5 minutos en iniciarse.
Visualización de mensajes, registros y errores
Los registros de mensajes y los mensajes de error se muestran en tres áreas de Visual Studio Code.
Panel Salida .
- En el panel Salida, seleccione Microsoft Sentinel en la lista desplegable.
- Seleccione Depurar para incluir entradas de registro detalladas.

Los mensajes en línea del cuaderno proporcionan comentarios e información sobre la ejecución de celdas de código. Estos mensajes incluyen actualizaciones de estado de ejecución, indicadores de progreso y notificaciones de error relacionadas con el código de la celda anterior
Un elemento emergente de notificación en la esquina inferior derecha de Visual Studio Code, también conocido como mensaje del sistema, proporciona alertas en tiempo real y actualizaciones sobre el estado de las operaciones en el cuaderno y la sesión de Spark. Estas notificaciones incluyen mensajes, advertencias y alertas de error, como la conexión correcta a una sesión de Spark y las advertencias de tiempo de espera.



Trabajos y programación
Puede programar que los trabajos se ejecuten en momentos o intervalos específicos mediante la extensión de Microsoft Sentinel para Visual Studio Code. Los trabajos permiten automatizar las tareas de procesamiento de datos para resumir, transformar o analizar datos en el lago de datos Microsoft Sentinel. Los trabajos también se usan para procesar datos y escribir resultados en tablas personalizadas en el nivel de lago de datos o en el nivel de análisis. Para obtener más información sobre cómo crear y administrar trabajos, consulte Creación y administración de trabajos de Jupyter Notebook.
Parámetros y límites de servicio para cuadernos de VS Code
En la sección siguiente se enumeran los parámetros y límites del servicio para Microsoft Sentinel data lake cuando se usan cuadernos de VS Code.
| Categoría | Parámetro/límite |
|---|---|
| Tabla personalizada en el nivel de análisis | Las tablas personalizadas del nivel de análisis no se pueden eliminar de un cuaderno; Use Log Analytics para eliminar estas tablas. Para obtener más información, vea Agregar o eliminar tablas y columnas en Azure Supervisión de registros |
| Tiempo de espera del socket web de puerta de enlace | 2 horas |
| Tiempo de espera de consulta interactiva | 2 horas |
| Tiempo de espera de inactividad de sesión interactiva | 20 minutos |
| Idioma | Python |
| Tiempo de espera del trabajo del cuaderno | 8 horas |
| Número máximo de trabajos simultáneos de cuadernos | 3, los trabajos posteriores se ponen en cola |
| Número máximo de usuarios simultáneos en consultas interactivas | 8-10 en piscina grande |
| Tiempo de inicio de sesión | La sesión de proceso de Spark tarda entre 5 y 6 minutos en iniciarse. Puede ver el estado de la sesión en la parte inferior del cuaderno de VS Code. |
| Bibliotecas admitidas | Solo se admiten las bibliotecas de Azure Synapse 3.4 y la biblioteca del proveedor de Microsoft Sentinel para las funciones abstractas para consultar el lago de datos. No se admiten instalaciones pip ni bibliotecas personalizadas. |
| Límite de experiencia de usuario de VS Code para mostrar registros | 100 000 filas |
Solución de problemas
En la tabla siguiente se enumeran los errores comunes que puede encontrar al trabajar con cuadernos, sus causas raíz y las acciones sugeridas para resolverlos.
| Categoría de error | Nombre del error | Código de error | Mensaje de error | Acción sugerida |
|---|---|---|---|---|
| DatabaseError | DatabaseNotFound | 2001 | No se encontró la base de datos {DatabaseName}. | Compruebe si existe la base de datos. Si la base de datos es nueva, espere a que se actualicen los metadatos. |
| DatabaseError | AmbiguousDatabaseName | 2002 | Varias bases de datos (identificadores: {DatabaseID1}, {DatabaseID2}, ...) comparten el nombre {DatabaseName}. Proporcione un identificador de base de datos específico. | Especifique un identificador de base de datos cuando varias bases de datos tengan el mismo nombre. |
| DatabaseError | DatabaseIdMismatch | 2003 | No se encontró la base de datos ({DatabaseName}, id. {DatabaseID}). | Compruebe el nombre y el identificador de la base de datos. Para obtener identificadores de base de datos, enumere todas las bases de datos. |
| DatabaseError | ListDatabasesFailure | 2004 | No se pueden capturar bases de datos. Reinicie la sesión e inténtelo de nuevo. | Reinicie la sesión y vuelva a intentar la operación después de unos minutos. |
| TableError | TableDoesNotExist | 2100 | La tabla {TableName} no se encuentra en la base de datos {DatabaseName}. | Compruebe que la tabla existe en la base de datos. Si la tabla o base de datos es nueva, espere unos minutos e inténtelo de nuevo. |
| TableError | ProvisioningIncomplete | 2101 | La tabla {TableName} no está lista. Espere unos minutos antes de intentarlo de nuevo. | La tabla se está aprovisionando. Espere unos minutos antes de intentarlo de nuevo. |
| TableError | DeltaTableMissing | 2102 | La tabla {TableName} está vacía. Las nuevas tablas pueden tardar hasta unas horas en estar listas. | Puede tardar unas horas en sincronizar completamente una tabla de análisis en el lago de datos. En el caso de las tablas que solo están en el lago de datos, compruebe si los datos deben cargarse o restaurarse. |
| TableError | TableDoesNotExistForDelete | 2103 | No se puede eliminar la tabla. No se encontró la tabla {TableName}. | Compruebe que la tabla existe en la base de datos. Si la tabla o base de datos es nueva, espere unos minutos e inténtelo de nuevo. |
| AuthorizationFailure | MissingSASToken | 2201 | No se puede acceder a la tabla. Reinicie la sesión e inténtelo de nuevo. | Error de autorización al intentar capturar el token de acceso de la tabla. Reinicie la sesión e inténtelo de nuevo. |
| AuthorizationFailure | InvalidSASToken | 2202 | No se puede acceder a la tabla. Reinicie la sesión e inténtelo de nuevo. | Error de autorización al intentar capturar el token de acceso de la tabla. Reinicie la sesión e inténtelo de nuevo. |
| AuthorizationFailure | TokenExpired | 2203 | No se puede acceder a la tabla. Reinicie la sesión e inténtelo de nuevo. | Error de autorización al intentar capturar el token de acceso de la tabla. Reinicie la sesión e inténtelo de nuevo. |
| AuthorizationFailure | TableInsufficientPermissions | 2204 | Acceso necesario para la tabla {TableName} en la base de datos {DatabaseName}. | Póngase en contacto con un administrador para solicitar acceso a la tabla o a la base de datos (área de trabajo). |
| AuthorizationFailure | InternalTableAccessDenied | 2205 | El acceso a la tabla {TableName} está restringido. | Solo se puede acceder a las tablas definidas por el sistema o por el usuario desde un cuaderno. |
| AuthorizationFailure | TableAuthFailure | 2206 | No se pueden guardar datos en la tabla. Reinicie la sesión e inténtelo de nuevo. | Error de autorización al intentar guardar datos en la tabla. Reinicie la sesión e inténtelo de nuevo. |
| ConfigurationError | HadoopConfigFailure | 2301 | No se puede actualizar la configuración de sesión. Reinicie la sesión e inténtelo de nuevo. | Este problema es transitorio y se puede resolver reiniciando la sesión e intentó de nuevo. Si este problema persiste, póngase en contacto con el soporte técnico. |
| DataError | JsonParsingFailure | 2302 | Los metadatos de tabla se han dañado. Póngase en contacto con el soporte técnico para obtener ayuda. | Póngase en contacto con el soporte técnico para obtener ayuda. Proporcione el identificador de inquilino, el nombre de la tabla y el nombre de la base de datos. |
| TableSchemaError | TableSchemaMismatch | 2401 | Columna no encontrada en la tabla de destino. Alinee el esquema dataframe y la tabla de destino o use el modo de sobrescritura. | Actualice el esquema dataframe para que coincida con la tabla de la base de datos de destino. También puede reemplazar la tabla completamente en modo de sobrescritura. |
| TableSchemaError | MissingRequiredColumns | 2402 | Falta la columna {ColumnName} en el dataframe. Compruebe el esquema dataframe y alinee con la tabla de destino. | Actualice el esquema dataframe para que coincida con la tabla de la base de datos de destino. También puede reemplazar la tabla completamente en modo de sobrescritura. |
| TableSchemaError | ColumnTypeChangeNotAllowed | 2403 | No se puede cambiar el tipo de datos de la columna {ColumnName}. | No se permite un cambio de tipo de datos para la columna. Compruebe las columnas existentes en la tabla de destino y alinee todos los tipos de datos del dataframe. |
| TableSchemaError | ColumnNullabilityChangeNotAllowed | 2404 | No se puede cambiar la nulabilidad de la columna {ColumnName}. | No se puede actualizar la configuración de nulabilidad de la columna. Compruebe la tabla de destino y alinee la configuración con dataframe. |
| IngestionError | FolderCreationFailure | 2501 | No se puede crear almacenamiento para la tabla {TableName}. | Este problema es transitorio y se puede resolver reiniciando la sesión e intentó de nuevo. Si este problema persiste, póngase en contacto con el soporte técnico. |
| IngestionError | SubJobRequestFailure | 2502 | No se puede crear un trabajo de ingesta para la tabla {TableName}. | Este problema es transitorio y se puede resolver reiniciando la sesión e intentó de nuevo. Si este problema persiste, póngase en contacto con el soporte técnico. |
| IngestionError | SubJobCreationFailure | 2503 | No se puede crear un trabajo de ingesta para la tabla {TableName}. | Este problema es transitorio y se puede resolver reiniciando la sesión e intentó de nuevo. Si este problema persiste, póngase en contacto con el soporte técnico. |
| InputError | InvalidWriteMode | 2601 | Modo de escritura no válido. Use anexar o sobrescribir. | Especifique un modo de escritura válido (anexar o sobrescribir) antes de guardar el dataframe. |
| InputError | PartitioningNotAllowed | 2602 | No se pueden crear particiones de tablas de análisis. | Quite las particiones de todas las columnas de las tablas de análisis. |
| InputError | MissingTableSuffixLake | 2603 | Nombre de tabla personalizada no válido. Todos los nombres de tablas personalizadas del lago de datos deben terminar con _SPRK. | Agregue _SPRK como sufijo al nombre de la tabla antes de escribirlo en el lago de datos. |
| InputError | MissingTableSuffixLA | 2604 | Nombre de tabla personalizada no válido. Todos los nombres de tablas de análisis personalizados deben terminar con _SPRK_CL. | Agregue _SPRK_CL como sufijo al nombre de la tabla antes de escribirlo en el almacenamiento de análisis. |
| UnknownError | InternalServerError | 2901 | Se ha producido un error. Reinicie la sesión e inténtelo de nuevo. | Este problema es transitorio y se puede resolver reiniciando la sesión e intentó de nuevo. Si este problema persiste, póngase en contacto con el soporte técnico. |
Nota:
No se admite la consulta de tablas heredadas como AzureDiagnostics.