Verankern Sie Ihr Modell mit durch Abruf angereicherter Generierung.
Tipp
Weitere Details finden Sie auf der Registerkarte "Text und Bilder ".
Das Prompt-Engineering hilft dabei zu steuern, wie ein Modell reagiert, kann dem Modell jedoch keine Kenntnisse geben, die es nicht bereits besitzt. Sprachmodelle werden auf großen Datasets trainiert, aber diese Schulungsdaten weisen einen Stichtag auf und enthalten nicht die privaten Informationen Ihrer Organisation. Wenn ein Modell keinen relevanten Kontext hat, kann es Antworten generieren, die plausibel klingen, aber sachlich falsch sind.
Um diese Herausforderung zu bewältigen, können Sie das Modell ermuntern , indem Sie ihm relevante, faktenbezogene Daten zur Grundlage seiner Antworten bereitstellen. Retrieval Augmented Generation (RAG) ist die am häufigsten verwendete Technik zur Erdung eines Sprachmodells.
Grundlegendes zur Erdung
Wenn Sie ein Sprachmodell ohne Grundlage verwenden, stammen die einzigen Informationen, die es aus seinen Schulungsdaten hat. Das Ergebnis kann grammatikalisch korrekt und logisch strukturiert sein, kann aber ungenau sein oder erstellte Details enthalten. So könnte beispielsweise die Frage "Welche Hotels bieten Sie in Paris?" ohne Bodendaten fiktive Hotelnamen zurückgeben.

Wenn Sie eine Eingabeaufforderung untermauern, liefern Sie relevante Daten aus einer vertrauenswürdigen Quelle zusammen mit der Benutzerfrage. Das Modell generiert dann eine Antwort basierend auf diesen Daten, wodurch genauere und kontextbezogenere Antworten erzeugt werden.
Berücksichtigen Sie den Unterschied:
- Nicht geerdet: Das Modell basiert nur auf seinen Schulungsdaten und kann Hotelnamen oder Details erfinden.
- Fundiert: Das Modell verarbeitet Ihre tatsächlichen Hotelkatalogdaten im Kontext, um mit echten Hotelnamen, Preisen und der Verfügbarkeit zu antworten.

Die Verankerung erhöht die inhaltliche Genauigkeit der Antworten, indem das Modell mit spezifischen, aktuellen und relevanten Informationen verbunden wird, die den Anforderungen des Benutzers entsprechen.
Funktionsweise von RAG
RAG ist ein Muster, das relevante Informationen aus einer Datenquelle abruft und in die Eingabeaufforderung einschließt, bevor das Modell eine Antwort generiert. Der Prozess folgt diesen drei Schritten:
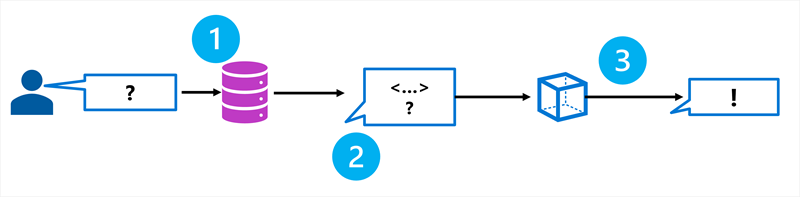
- Abrufen: Suchen Sie eine Datenquelle nach Informationen, die für die Frage des Benutzers relevant sind.
- Erweiterung: Fügen Sie der Eingabeaufforderung die abgerufenen Informationen als Kontext hinzu.
- Generieren: Senden Sie die erweiterte Eingabeaufforderung an das Sprachmodell, um eine geerdete Antwort zu generieren.
Durch das Abrufen von Kontextinformationen aus einer angegebenen Datenquelle stellen Sie sicher, dass das Modell relevante, aktuelle Informationen verwendet, anstatt sich ausschließlich auf seine Schulungsdaten zu verlassen.
Erstellen von Einbettungen für die Suche
Eine wichtige Komponente von RAG ist die Möglichkeit, die relevantesten Informationen in Ihrer Datenquelle effizient zu finden. Hier kommen Einbettungen und Vektorsuche ein.
Eine Einbettung ist eine mathematische Darstellung von Text als Vektor – eine Liste von Gleitkommazahlen, die die Bedeutung von Wörtern, Sätzen oder Dokumenten erfassen. Sie erstellen Einbettungen, indem Sie Ihre Inhalte an ein Einbettungsmodell senden, z. B. ein Azure OpenAI-Einbettungsmodell, das in Microsoft Foundry verfügbar ist.
Stellen Sie sich beispielsweise zwei Dokumente vor:
- „Die Kinder spielten fröhlich im Park.“
- „Kinder liefen glücklich auf dem Spielplatz herum.“
Diese Sätze verwenden unterschiedliche Wörter, weisen jedoch ähnliche Bedeutungen auf. Wenn Sie Einbettungen für jeden erstellen, sind ihre Vektoren eng im mehrdimensionalen Raum zusammen und spiegeln ihre semantische Ähnlichkeit wider.

Kosinusgleichheit misst, wie nah zwei Vektoren sind, indem der Winkel zwischen ihnen berechnet wird. Ein Wert in der Nähe von 1 bedeutet, dass die Vektoren sehr ähnlich sind. Mit diesem mathematischen Ansatz können Sie relevante Dokumente auch dann finden, wenn die genauen Wörter nicht übereinstimmen.
Verwenden von Azure KI-Suche für den Abruf
Azure KI-Suche stellt die Abrufkomponente für RAG-Lösungen in Microsoft Foundry bereit. Sie können ihre eigenen Daten mitbringen, einen durchsuchbaren Index erstellen und ihn abfragen, um relevante Informationen abzurufen.

Um Azure KI-Suche mit RAG zu verwenden, führen Sie folgende Aktionen aus:
- Fügen Sie Ihre Daten aus Quellen wie Azure Blob Storage, Azure Data Lake Storage Gen2 oder Microsoft OneLake zu Microsoft Foundry hinzu. Sie können Dateien auch direkt hochladen.
- Erstellen Sie einen Index mithilfe eines Einbettungsmodells, um Vektordarstellungen Ihrer Inhalte zu generieren. Der Index wird in Azure KI-Suche gespeichert.
- Fragen Sie den Index ab, wenn ein Benutzer eine Frage stellt. Das System konvertiert die Frage in eine Einbettung, sucht nach dem ähnlichsten Inhalt und gibt die relevanten Ergebnisse zurück.
Azure KI-Suche unterstützt verschiedene Suchtechniken:
- Stichwortsuche: Entspricht exakten Begriffen in der Abfrage dem Text im Index.
- Semantische Suche: Verwendet semantische Modelle, um der Bedeutung der Abfrage statt exakten Schlüsselwörtern zu entsprechen.
- Vektorsuche: Verwendet Einbettungen, um semantisch ähnliche Inhalte zu finden.
- Hybridsuche: Kombiniert Schlüsselwörter, Semantik und Vektorsuche für die genauesten Ergebnisse. Die Hybridsuche wird für generative KI-Anwendungen empfohlen.
Implementieren von RAG mit dem Azure AI Foundry SDK
Nachdem Sie einen Azure KI-Suche Index erstellt haben, können Sie ihn über Ihre Microsoft Foundry-project mit einem Modell verbinden. Mit dem azure-ai-projects SDK können Sie einen authentifizierten OpenAI-Client abrufen und die Antwort-API verwenden, um geerdete Antworten zu generieren.
Der folgende Python-Code zeigt eine grundlegende Implementierung:
from azure.ai.projects import AIProjectClient
from azure.identity import DefaultAzureCredential
project = AIProjectClient(
endpoint=os.environ["PROJECT_ENDPOINT"],
credential=DefaultAzureCredential(),
)
client = project.get_openai_client()
response = client.responses.create(
model="gpt-4o",
input=[
{"role": "system", "content": "You are a helpful travel advisor. "
"Use the following hotel data to answer: " + retrieved_context},
{"role": "user", "content": "Which hotels do you offer in Paris?"},
],
)
print(response.output_text)
In diesem Beispiel stellt retrieved_context die von Ihrem Azure KI-Suche Index zurückgegebenen Dokumente dar. Durch das Einfügen dieser Ergebnisse in die Systemnachricht basiert die Antwort des Modells auf Ihren tatsächlichen Daten anstatt auf seinem allgemeinen Schulungswissen.
Wann soll RAG verwendet werden?
RAG ist am effektivsten, wenn:
- Das Modell benötigt domänenspezifische Kenntnisse: Ihre Organisation verfügt über private Daten, auf die das Modell nicht trainiert wurde, z. B. einen Produktkatalog, Richtliniendokumente oder interne knowledge base.
- Informationen ändern sich häufig: Ihre Daten werden regelmäßig aktualisiert, z. B. Bestand, Preise oder Neuigkeiten. RAG ruft aktuelle Daten zur Abfragezeit ohne neues Training ab.
- Die sachliche Genauigkeit ist entscheidend: Sie benötigen Antworten, die auf realen Daten basieren und nicht auf dem Allgemeinwissen des Modells.
- Die Schulungsdaten des Basismodells haben einen Stichtag: Ereignisse oder Informationen, die nach diesem Stichtag aufgetreten sind, müssen zugänglich sein.
Für das Szenario des Reisebüros ermöglicht RAG kunden, Fragen zu bestimmten Hotels, Destinationen und Buchungsrichtlinien zu stellen, die alle in den tatsächlichen Katalogdaten der Agentur verankert sind.
Tipp
Wenn Sie Agenten erstellen, die fundiertes Wissen benötigen, ohne Ihre eigene Suchinfrastruktur zu verwalten, sollten Sie Foundry IQ in Betracht ziehen – einen verwalteten Wissensspeicher, der die Erdung für KI-Agenten vereinfacht. Weitere Informationen finden Sie unter Wissensgestützte KI-Agenten mit Foundry IQ erstellen.