Bereitstellen von Modellen zu Endpunkten
Tipp
Weitere Details finden Sie auf der Registerkarte "Text und Bilder ".
Nachdem Sie ein Modell aus dem Katalog ausgewählt haben, stellen Sie es bereit, um es über Endpunkte zugänglich zu machen, die Ihre Anwendungen verwenden können. Das Microsoft Foundry-Portal führt Sie durch den Bereitstellungsprozess und stellt Tools zum sofortigen Testen Ihrer bereitgestellten Modelle bereit.
Grundlegendes zu Bereitstellungstypen
Microsoft Foundry unterstützt mehrere Bereitstellungstypen, die jeweils unterschiedliche Merkmale für die Datenhaltung, Skalierung und Abrechnung bieten:
- Globale Standardmodellbereitstellungen können jede Azure-Region auf Pay-per-Token-Basis verwenden. Sie sind am besten für allgemeine Workloads geeignet und stellen das höchste Kontingent bereit.
- Global bereitgestellte Bereitstellungen können in jeder Azure-Region genutzt werden, wobei ihre Nutzung auf der Basis von reservierten Bereitstellungsdurchsatzeinheiten (PTU) erfolgt, um einen vorhersehbaren hohen Durchsatz zu bieten.
- Globale Batchbereitstellungen können eine beliebige Azure-Region mit einem Rabatt von 50% für große asynchrone Aufträge innerhalb von 24 Stunden verwenden.
- Data Zone Standard-Bereitstellungen stellen sicher, dass Daten innerhalb einer bestimmten Datenzone auf Pay-per-Token-Basis verbleiben. Sie eignet sich am besten für Szenarien, in denen die Eu/US-Datenzonencompliance erforderlich ist.
- Bereitstellungen von Datenzonen bieten einen vorhersehbaren Durchsatz basierend auf reservierten PTUs innerhalb einer Datenzone.
- Datenzonen-Batch-Implementierungen sind für große asynchrone Batch-Jobs innerhalb einer Datenzone ausgelegt.
- Standardbereitstellungen werden in einer einzelnen Region auf Pay-per-Token-Basis bereitgestellt. Sie sind hervorragend geeignet, wenn Sie regionale Anforderungen an die Datenresidenz oder Szenarien mit niedrigem Datenvolumen erfüllen müssen.
- Regionale Bereitstellungen stellen reservierte PTUs in einer einzelnen Region bereit.
- Entwickler Entwicklerbereitstellungen verwenden eine beliebige Azure-Region auf Pay-per-Token-Basis und dienen nur einer fein abgestimmten Modellauswertung.
Jedes Modell im Katalog gibt an, welche Bereitstellungstypen unterstützt werden. Das Portal wählt automatisch die beste Bereitstellungsoption basierend auf Ihren Umgebungs- und Modellanforderungen aus. Globale Standardbereitstellungen in Foundry-Ressourcen sollten nach Möglichkeit für maximale Funktionen verwendet werden.
Bereitstellen eines Modells
So stellen Sie ein Modell aus dem Microsoft Foundry-Portal bereit:
Navigieren Sie zuerst zu dem Modell, das Sie im Modellkatalog ausgewählt haben. Wählen Sie auf der Startseite des Foundry-Portals " Entdecken " in der Navigation und dann " Modelle " im linken Bereich aus. Öffnen Sie die Modellkarte, um die Spezifikationen und unterstützten Bereitstellungstypen zu überprüfen.
Wählen Sie "Bereitstellen" aus, um den Bereitstellungsprozess zu starten. Sie können Folgendes auswählen:
- Standardeinstellungen für die schnelle Bereitstellung mit empfohlenen Konfigurationen
- Benutzerdefinierte Einstellungen zum Anpassen Der Bereitstellungsoptionen
Wenn für das Modell ein Azure Marketplace-Abonnement erforderlich ist (allgemein für Modelle von Partnern und der Community), werden Nutzungsbedingungen angezeigt. Überprüfen Sie diese Bedingungen, und wählen Sie "Zustimmen" aus, und fahren Sie mit der Annahme fort. Modelle, die direkt von Azure verkauft werden, z. B. Azure OpenAI-Modelle wie GPT-4o-mini, erfordern keine Marketplace-Abonnements.
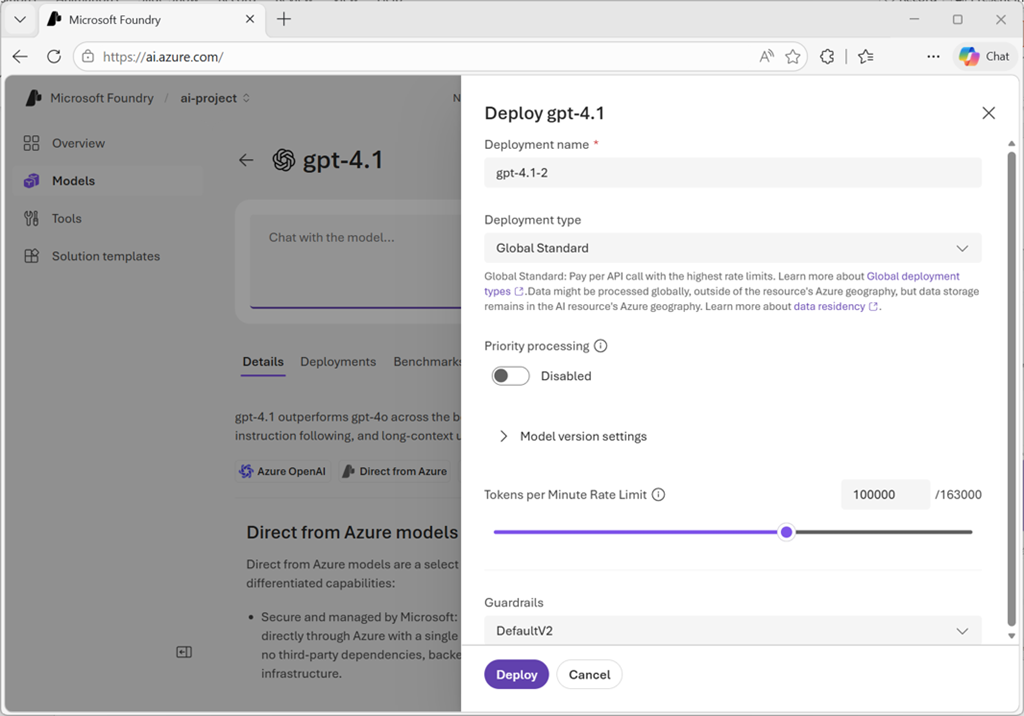
Konfigurieren Sie Ihre Bereitstellungseinstellungen:
-
Bereitstellungsname: Standardmäßig verwendet das System den Modellnamen. Sie können dies ändern, um aussagekräftige Namen für mehrere Bereitstellungen desselben Modells zu erstellen. Während der Ableitung verwendet Ihr Code diesen Bereitstellungsnamen im
modelParameter, um Anforderungen weiterzuleiten. - Bereitstellungstyp: Das Portal wählt automatisch den entsprechenden Bereitstellungstyp basierend auf dem Modell und Ihrer Umgebung aus. Jedes Modell unterstützt unterschiedliche Bereitstellungstypen, die unterschiedliche Datenhaltungs- oder Durchsatzgarantien bieten.
Für verwaltete Computebereitstellungen konfigurieren Sie außerdem Folgendes:
- SKU des virtuellen Computers: Wählen Sie aus unterstützten VM-Typen aus. Sie benötigen ein Rechenkontingent für Azure Machine Learning für die ausgewählte SKU in Ihrem Abonnement.
- Anzahl der Instanzen: Geben Sie an, wie viele Instanzen für die Lastverteilung und Redundanz bereitgestellt werden sollen.
Nachdem Sie alle Einstellungen konfiguriert haben, wählen Sie "Bereitstellen" aus. Wenn die Bereitstellung abgeschlossen ist, landen Sie auf dem Foundry Playground, in dem Sie das Modell interaktiv testen können. Stellen Sie sicher, dass der Bereitstellungsstatus in Ihrer Bereitstellungsliste "Erfolgreich " angezeigt wird.
Verwalten von bereitgestellten Modellen
Nach der Bereitstellung verwalten Sie Ihre Modelle im Abschnitt "Build " im Microsoft Foundry-Portal. Wählen Sie " Erstellen " in der Navigation und dann " Modelle " im linken Bereich aus, um die Liste der Bereitstellungen in Ihrer Ressource anzuzeigen.
Wählen Sie in der Bereitstellungsliste ein bestimmtes Modell aus, um dessen Details anzuzeigen:
- Bereitstellungskonfiguration und -status
- Endpunkt-URL für API-access
- Authentifizierungsschlüssel oder Token
- Überwachungs- und Nutzungsmetriken
- Option zum Anpassen der Bereitstellungseinstellungen oder Löschen der Bereitstellung
Die Seite mit den Bereitstellungsdetails enthält die Informationen, die Ihre Anwendungen benötigen, um eine Verbindung mit dem Modell herzustellen und zu verwenden.
Testen im Spielplatz
Das Microsoft Foundry-Portal enthält interaktive Spielplätze, in denen Sie bereitgestellte Modelle sofort testen, ohne Code zu schreiben. Nach Abschluss der Bereitstellung landen Sie automatisch im Spielplatz, oder Sie können eine Bereitstellung aus Ihrer Modellliste auswählen, um den Playground zu öffnen.
Der Playground wählt Ihre Bereitstellung vor, sodass Sie sofort mit dem Testen beginnen können. In der Chatschnittstelle:
Geben Sie Eingabeaufforderungen in das Meldungsfeld ein, und beobachten Sie Antworten. Der Playground zeigt sowohl Ihre Eingabe als auch die generierte Ausgabe des Modells an und hilft Ihnen dabei, Das Verhalten und die Qualität zu verstehen.
Experimentieren Sie mit verschiedenen Arten von Eingabeaufforderungen, um verschiedene Funktionen zu testen:
- Einfache Fragen zum Überprüfen des grundlegenden Verständnisses
- Komplexe Probleme mit mehrstufigen Argumentationen
- Anfragen nach bestimmten Formaten oder Stilrichtungen
- Randfälle, die Einschränkungen aufzeigen können
Passen Sie Systemmeldungen an, um das Modellverhalten zu leiten. Systemnachrichten legen Kontext, Ton und Anweisungen fest, die für alle Benutzereingaben gelten. Sie können das Modell beispielsweise anweisen, "als Kundenservice-Mitarbeiter zu antworten" oder "präzise technische Erklärungen bereitzustellen".
Ändern Sie Parameter wie Temperatur (Kreativität vs. Konsistenz), maximale Token (Grenzwerte für die Antwortlänge) und Top-p (Kernsampling) zur Feinabstimmung des Erzeugungsverhaltens.
Wählen Sie die Registerkarte "Code " aus, um Beispiele zum programmgesteuerten Aufrufen des bereitgestellten Modells anzuzeigen. Die Codebeispiele zeigen Authentifizierung, Endpunktkonfiguration und Anforderungsformatierung in Sprachen wie Python, C# und JavaScript. Sie können diese Beispiele direkt in Ihre Anwendung kopieren.
Der Playground dient als Entwicklungsumgebung für schnelles Engineering und Tests, bevor sie das Modell in Ihre Anwendung integrieren.
Zugriff auf Modelle programmgesteuert
Wenn Sie bereit sind, das Modell in Ihre Anwendung zu integrieren, benötigen Sie drei wichtige Informationen aus den Bereitstellungsdetails:
Endpunkt-URL: Der API-Endpunkt, an den Ihre Anwendung Anforderungen sendet. Microsoft Foundry unterstützt Projektendpunkte für foundry-spezifische Funktionen und OpenAI v1-Endpunkte zur umfassenden Kompatibilität mit OpenAI-Modell-APIs.
Authentifizierungsschlüssel: Der geheime Schlüssel oder Token, den Ihre Anwendung für die Authentifizierung von Anforderungen darstellt. Alternativ können Sie die Microsoft Entra ID-Authentifizierung verwenden und Ihre Anwendung ein Authentifizierungstoken basierend auf ihrer Identität präsentieren lassen. Die Entra-ID-Authentifizierung wird für Produktionsszenarien empfohlen.
Bereitstellungsname: Der Name, den model Sie während der Bereitstellung angegeben haben, wird im Parameter der API-Anforderungen verwendet, um an Ihre spezifische Bereitstellung weiterzuleiten.
Ihre Anwendung verwendet diese Details, um API-Anforderungen zu erstellen. Das Microsoft Foundry-Portal bietet SDKs und REST-API-Dokumentationen für verschiedene Programmiersprachen sowie Codebeispiele mit Anforderungsformatierung, Authentifizierung und Antwortbehandlung.
Nachdem Ihr Modell bereitgestellt und getestet wurde, können Sie es in Anwendungen integrieren oder mit automatisierten Metriken und Testdatensätzen umfassendere Auswertungen durchführen.