Note
Sie können jetzt Prep-Daten für KI-Features sowohl im Power BI Service als auch in der Power BI Desktop erstellen. Benutzer können consume diese Features überall dort verwenden, wo Copilot vorhanden sind.
Werkzeugfunktionen
Welche Funktionen bietet Power BI derzeit, um mir bei der Vorbereitung meiner Daten für Copilot zu helfen?
Heute bietet Power BI vier Hauptfunktionen zum Konfigurieren Ihres Modells für die Verarbeitung natürlicher Sprachen:
- AI-Datenschemas: Ermöglicht die Auswahl einer Teilmenge eines Schemas für die Copilot-Nutzung.
- Überprüfte Antworten: Eine konfigurierte Antwort, die ein Modellautor auf Genauigkeit und Zuverlässigkeit überprüft. Autoren können bestimmte visuelle Elemente für Copilot festlegen, die in einer überprüften Antwort verwendet werden sollen, wenn ein Benutzer eine Frage stellt, die in die zugewiesene Kategorie fällt.
- KI-Anweisungen: Anweisungen, die Sie für Ihr Modell festlegen können, um mehr Kontext zu den Daten im Modell bereitzustellen. Sie helfen Copilot zu verstehen, wann sie sich auf welche Daten konzentrieren müssen, und helfen Copilot, bestimmte Zuordnungen zu verstehen, die Sprachbenutzer bei der Interaktion mit Copilot verwenden können.
- Beschreibungen: Beschreibungen, die für Tabellen und Spalten festgelegt sind, um mehr Details zum Kontext der Daten bereitzustellen. Beschreibungen werden nur in DAX-Abfragen (Data Analysis Expressions) und Copilot-Suchfunktionen verwendet.
In welcher Reihenfolge sollte ich Copilot in Power BI Toolfunktionen implementieren?
Um den größten Wert von Copilot in Power BI zu erhalten, empfehlen wir die Implementierung der Toolfunktionen in der folgenden Reihenfolge:
Definieren Sie das KI-Datenschema.
Wählen Sie zunächst die spezifischen Tabellen, Felder und Measures aus, auf die Copilot verweisen sollten, wenn sie Datenfragen beantwortet.
Während der Modellentwicklung können Sie Elemente einschließen, die für Endbenutzerabfragen nicht relevant sind. Wenn Sie das Schema eingrenzen, helfen Sie Copilot, sich auf die aussagekräftigsten Teile Ihres Modells zu konzentrieren, wodurch die Mehrdeutigkeit reduziert wird. Diese Vorgehensweise ist für große Datasets mit überlappenden oder ähnlich benannten Feldern wichtig.
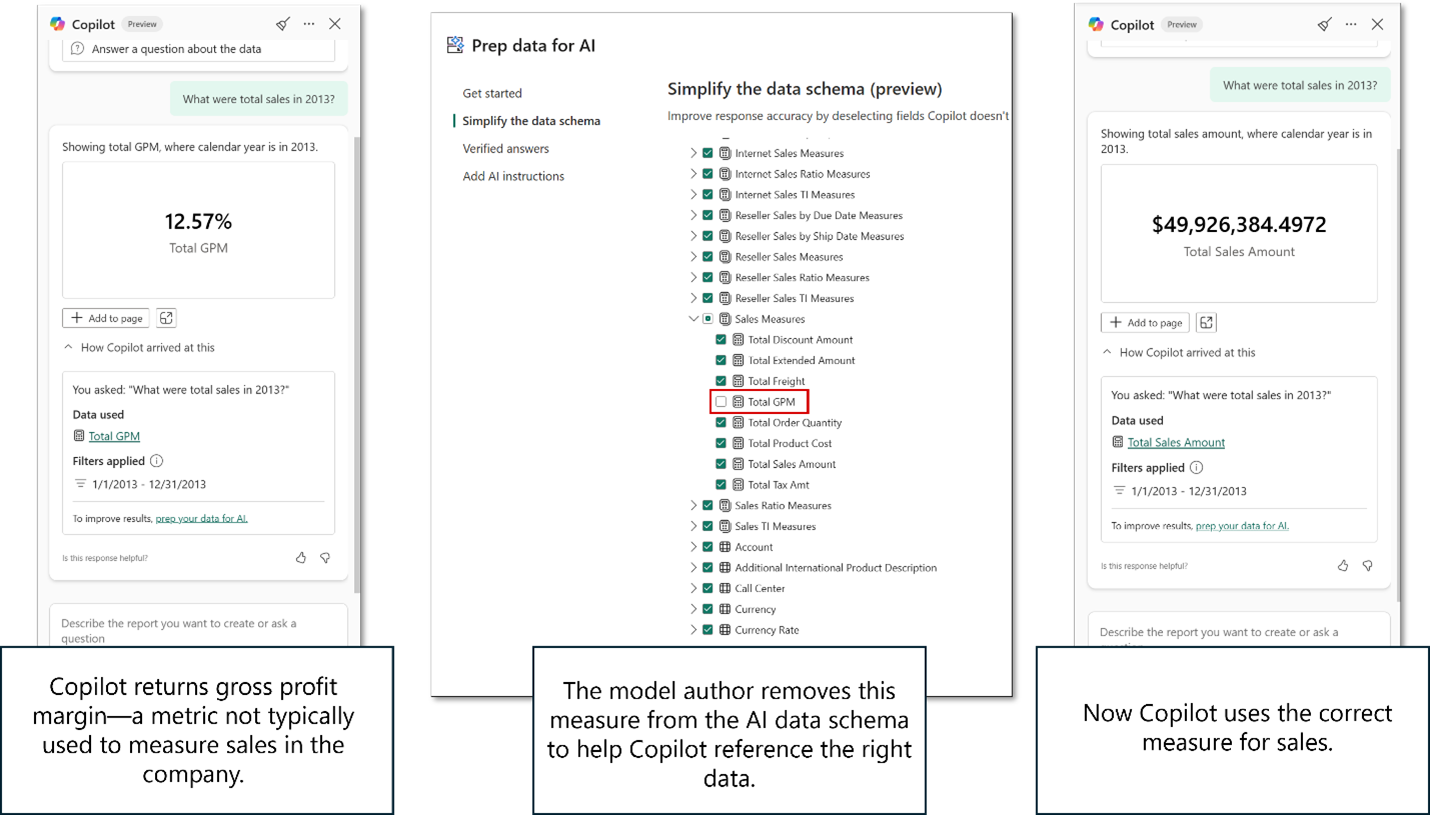
Hier ist ein Beispiel dafür, wie KI-Datenschemas helfen können, Copilot den Fokus auf die richtigen Daten zu legen:
Wenn Sie das gesamte Schema verwenden, weiß Copilot nicht immer, was der Benutzer bedeutet, wenn er verkaufs sagt. In diesem Fall hat Copilot die Bruttogewinnmarge (GPM) zurückgegeben, was eine legitime Interpretation des Umsatzes ist, aber nicht die Metrik, die dieses Team in der Regel verwendet, um den Umsatz zu analysieren.
Der Modellautor verwendet das Feature Prep-Daten für KI und entfernt das GPM-Gesamtmaß aus dem Schema, das an Copilot übergeben wird.
Wenn der Benutzer nun die gleiche Frage stellt, weiß Copilot genauer, woher er die Antwort bekommen kann, und interpretiert die Umsätze korrekt nach der Definition und Messung des Teams.
Erstellen Sie überprüfte Antworten.
Richten Sie überprüfte Antworten für häufig gestellte oder differenzierte Fragen ein, die Benutzer möglicherweise stellen.
Wählen Sie ein visuelles Element und dann " Überprüfte Antwort erstellen" aus. Fügen Sie dann Triggerausdrücke hinzu, die widerspiegeln, wie Benutzer ihre Fragen wahrscheinlich ausdrücken. Wenn Benutzer einen übereinstimmenden oder ähnlichen Ausdruck in Copilot eingeben, wird die vertrauenswürdige visuelle Darstellung zurückgegeben. Dieser Prozess trägt dazu bei, konsistente, qualitativ hochwertige Antworten über Berichte hinweg sicherzustellen.
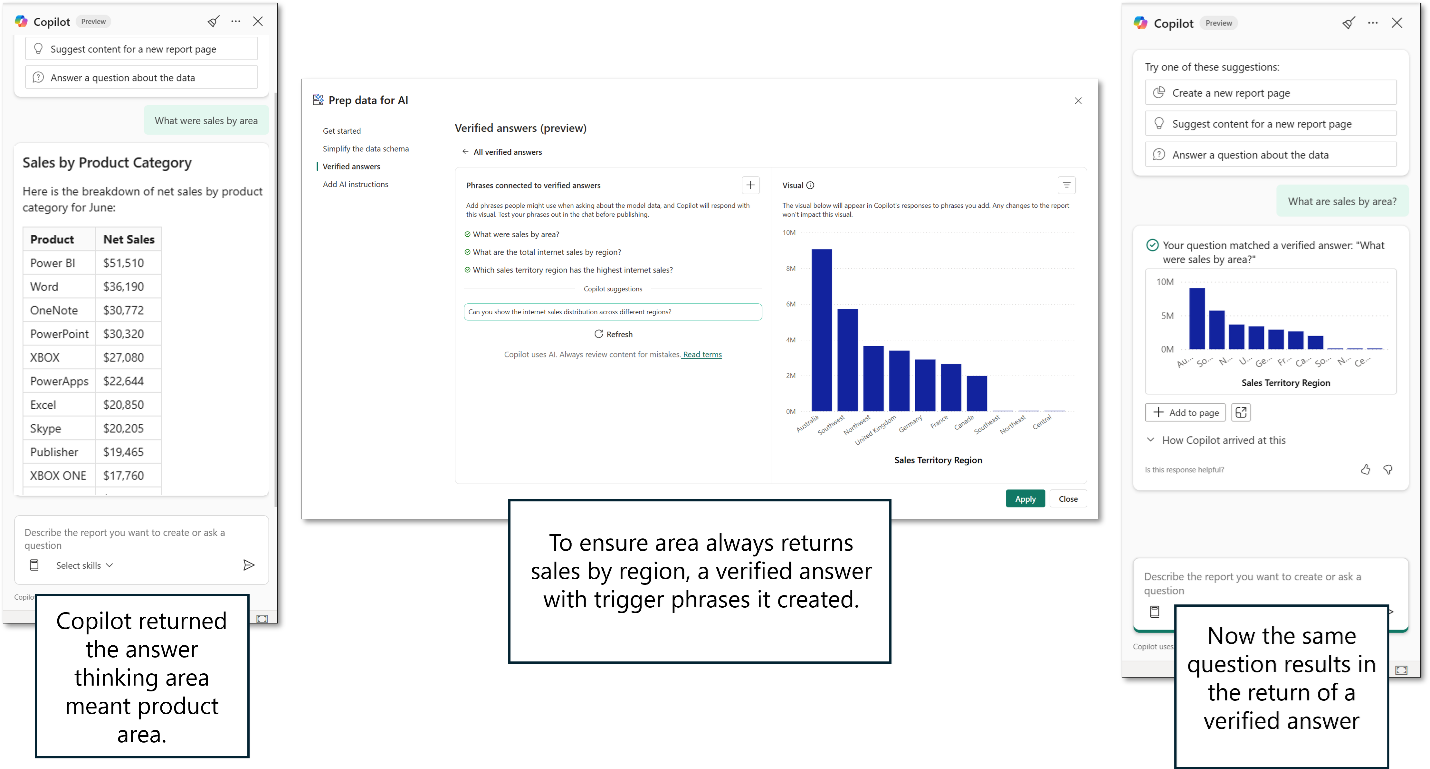
Das folgende Beispiel zeigt den Vorteil einer überprüften Antwort. Der Benutzer fragt nach Vertrieb nach Bereich. Copilot interpretiert area als produktbereich und gibt eine Liste der Produkte und deren Umsätze zurück. Der Benutzer suchte jedoch nach Umsätzen nach Region oder Standort.
Der Modellautor legt eine überprüfte Antwort mithilfe eines visuellen Elements fest, das Umsätze nach Region enthält. Anschließend enthält der Autor Triggerausdrücke, die, wenn ein Benutzer sie fragt, diese spezifische visuelle Antwort zurückgeben sollte.
Wenn der Benutzer jetzt nach Verkäufen nach Bereich fragt, gibt Copilot die überprüfte Antwort zurück, die der Modellautor genehmigt.
Fügen Sie KI-Anweisungen hinzu.
Nachdem Sie das Schema und überprüfte Antworten definiert haben, können Sie KI-Anweisungen verwenden, um das Verhalten von Copilot auf Modellebene zu leiten.
Anweisungen helfen dabei, Geschäftslogik zu verdeutlichen, Benutzerterminologien auf Modellfelder abzubilden und Copilot mitzuteilen, wie spezifische Datentypen interpretiert oder analysiert werden sollten. Sie sind hilfreich, da sie Kontext bereitstellen, den Copilot von sich aus nicht ableiten würde.
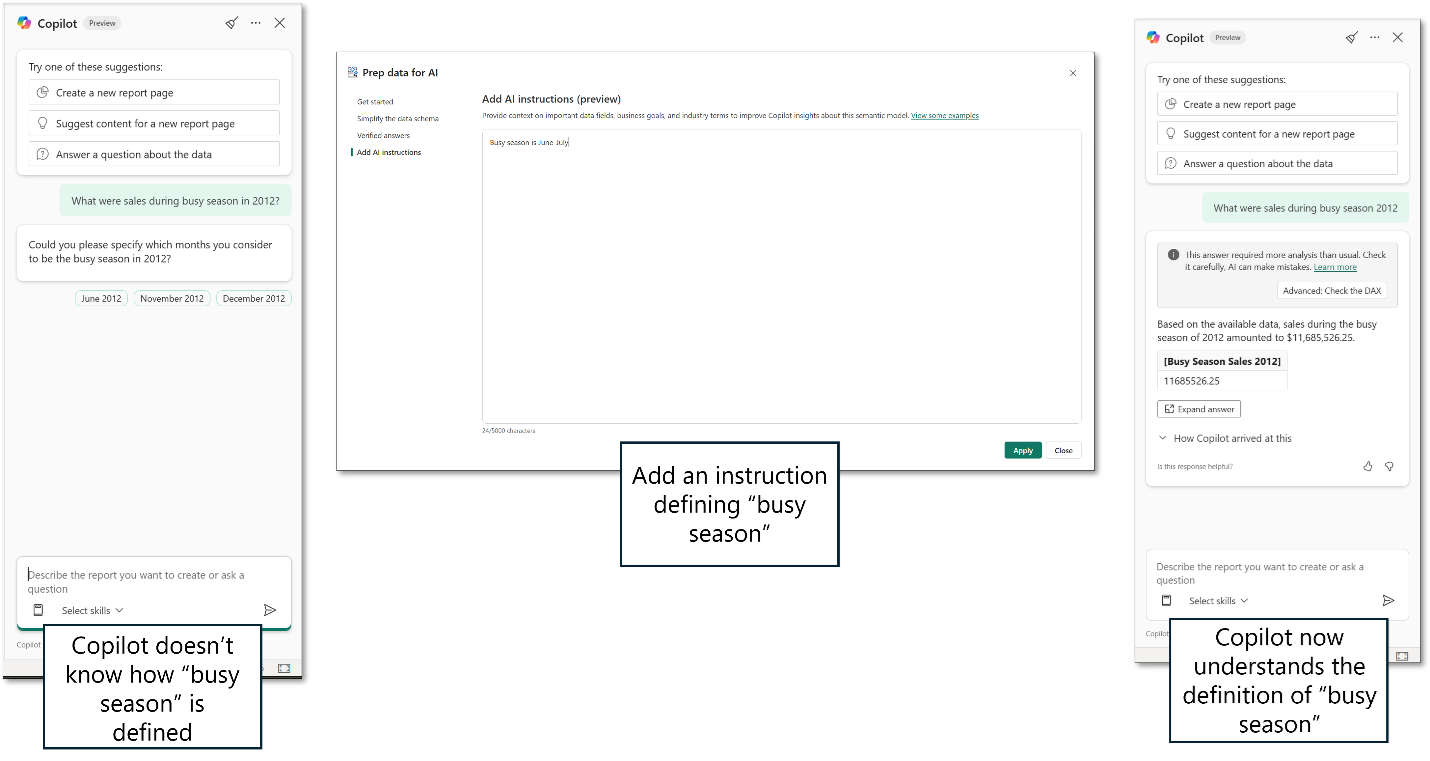
Das folgende Beispiel zeigt, wie Sie KI-Anweisungen verwenden können, um mehr Kontext für Copilot bereitzustellen. Der Benutzer fragt nach Verkäufen während der Hochsaison 2012. Die Hochsaison ist ein gut definierter, häufig verwendeter Ausdruck in diesem Unternehmen. Das Semantikmodell weist jedoch keinen Hinweis auf diesen Begriff an. Der Modellautor legt eine Anweisung fest, die die Hauptsaison als Juni bis August definiert.
Wenn der Benutzer nun die Frage zu Verkauf während der Hochsaison stellt, versteht Copilot diesen definierten Begriff und kann die Antwort liefern.
Fügen Sie Tabellen- und Spaltenbeschreibungen hinzu.
Beschreibungen stellen zusätzliche Metadaten bereit, die Copilot verwenden können, um Ihr Modell zu verstehen.
Obwohl Beschreibungen derzeit nur einige Copilot Verhaltensweisen beeinflussen, spielen sie in zukünftigen Funktionen eine größere Rolle. Durch das Hinzufügen dieser Elemente können Sie nun eine starke Grundlage für den langfristigen Erfolg mit Interaktionen in natürlicher Sprache in Power BI schaffen.



Kann ich anstelle des Modells Tools für einen Bericht erstellen?
Heute sind Tools und Konfigurationsfeatures nur für das Modell verfügbar. Das Konfigurieren verschiedener Berichte, die auf demselben Modell erstellt wurden, wird noch nicht unterstützt. Das Schema, überprüfte Antworten, Anweisungen und Beschreibungen werden für das semantische Modell, aber nicht für den Bericht festgelegt.
Welche Funktionen sind betroffen, wenn ich meine Daten für Copilot vorbereiten?
Beachten Sie hierzu die folgende Tabelle:
| Capability | KI-Datenschemas | Überprüfte Antworten | KI-Anweisungen | Descriptions |
|---|---|---|---|---|
| Abrufen einer Zusammenfassung meines Berichts | No | No | Yes | No |
| Stellen Sie eine Frage zu den Visualisierungen meines Berichts | No | Yes | Yes | No |
| Stellen Sie eine Frage zu meinem semantischen Modell | Yes | Yes | Yes | No |
| Erstellen einer Berichtsseite | No | No | Yes | No |
| Search | No | Yes | No | Yes |
| DAX-Abfrage | No | No | Yes | Yes |
Wissen, welches Feature verwendet werden soll
Ich versuche, Copilot dazu zu bringen, das richtige Feld auszuwählen. Welches Feature sollte ich verwenden?
Definieren Sie Ihr KI-Datenschema.
Entfernen Sie alle Tabellen, Spalten oder Felder, die für die Anforderungen Ihrer Benutzer irrelevant sind. Diese Aktion hilft Copilot den Fokus auf die relevantesten Teile Ihres Modells zu legen und sicherzustellen, dass sie die richtigen Felder auswählt, wenn sie auf Abfragen antwortet.
Verwenden Sie überprüfte Antworten für visuelle Elemente in Berichten.
Wenn Copilot ein visuelles Element in Ihrem Bericht verwenden kann, um eine Antwort auf eine Frage abzuleiten, erstellen Sie eine überprüfte Antwort. Mit dieser Vorgehensweise können Sie sicherstellen, dass Copilot konsistent das richtige visuelle Element zurückgibt, wenn Benutzer Fragen mit bestimmten Triggerausdrücken stellen.
Passen Sie Anweisungen für bestimmte Felder an.
Nachdem Sie das Schema festgelegt und überprüfte Antworten festgelegt haben, können Sie KI-Anweisungen verwenden, um Copilot beim Auswählen bestimmter Felder zu führen. Wir empfehlen, Anweisungen für die Feinabstimmung und für erweiterte Szenarien zu verwenden, nachdem andere vorbereitete Daten für KI-Features festgelegt wurden. Mithilfe dieser Schrittfolge können Sie sicherstellen, dass Copilot die genauesten und kontextrelevanten Ergebnisse an Benutzer zurückgibt, die von der Struktur Ihres Modells und ihren definierten Anweisungen geleitet werden.
Ich versuche, Copilot dazu zu bringen, den Begriff zu verstehen, den ich verwende. Welches Feature sollte ich verwenden?
Wenn Copilot Schwierigkeiten hat, einen Begriff korrekt zu interpretieren, der immer auf dasselbe einzige richtige Element verweist, auf das in Ihrem Modell verwiesen wird, können Sie einen alternativen Namen durch KI-Anweisungen angeben.
Wenn Ihr Team beispielsweise die Personen, die Ihre Produkte verkaufen, als "Closer" bezeichnet, sollten Sie in Ihren KI-Anweisungen darauf hinweisen. Legen Sie fest, dass Verkäufer auch als Näherer bezeichnet werden.
Ich versuche, Copilot dazu zu bringen, Bedingungen oder Gruppierungen zu verstehen. Welches Feature sollte ich verwenden?
Wenn Ihr Team bestimmte Begriffe verwendet, die nicht exakt mit Tabellen oder Feldern in Ihrem Modell übereinstimmen, können Sie KI-Anweisungen verwenden, um verschiedene Elemente mit bestimmten Bedingungen oder Gruppierungen zu klären.
Beispielsweise kann ein Vertriebsteam jeden, der mehr als 100% seiner Ziele verkauft, in einem bestimmten Monat als High-Performer klassifizieren. Sie sollten die folgenden Anweisungen für Copilot bereitstellen.
Ein Spitzenleister ist ein Verkäufer, der 100 % oder mehr seines monatlichen Ziels erreicht.
Wenn ein Benutzer nun fragt: "Wer waren die High performer im letzten Monat?" Copilot weiß genau, was high performer in Ihrem Team und Ihrer Organisation bedeutet.
In einem anderen Beispiel kann eine Organisation Jahreszeiten klassifizieren. Ihr Team ruft möglicherweise Januar bis Mai langsame Saison an. Juni bis September kann die Saison überlastet sein. Oktober bis Dezember kann eine Standardsaison sein.
In KI-Anweisungen können Sie die folgenden Definitionen festlegen:
- Langsame Saison bedeutet Januar bis Mai.
- Gebuchte Saison bedeutet Juni bis September.
- Die Standardsaison bedeutet Oktober bis Dezember.
Copilot versteht, welchen Zeitrahmen der Benutzer mit busy season meint, wenn ein Benutzer nun fragt: "Was waren die Gesamtumsätze für die Hochsaison im letzten Jahr?"
Ich versuche, Copilot dazu zu bringen, die richtige Antwort auf die am häufigsten gestellten Fragen zu liefern. Welches Feature sollte ich verwenden?
Verbraucher Ihres Berichts und Ihrer Daten stellen wahrscheinlich häufiger Fragen. Sie können dieses Vorkommen beheben, indem Sie überprüfte Antworten auf Ihr Modell anwenden. Wenden Sie eine überprüfte Antwort an, indem Sie visuelle Elemente auswählen und Trigger-Phrasen festlegen. Wenn ein Benutzer nach dem Thema fragt, gibt Copilot Informationen mithilfe des zugewiesenen visuellen Elements zurück.
Beispielsweise könnten Verbraucher des Berichts und Modells häufig fragen: "Welches Produkt hatte letzte Woche die höchsten Verkäufe?" Sie können eine überprüfte Antwort festlegen, um Copilot zu verstehen, wo sie die richtigen Informationen finden kann. Diese Methode hilft Autoren und Verbrauchern zu vertrauen, dass die Antwort richtig ist.
Ich versuche, Copilot dazu zu bringen, je nach Domains oder Benutzergruppen unterschiedliche Antworten zu geben. Welches Feature sollte ich verwenden?
Die heute vorhandenen Funktionen sind auf den breiten Verbrauch beschränkt. Sie können derzeit kein Glossar basierend auf verschiedenen Gruppen erstellen oder einen Begriff auf zwei verschiedene Arten definieren. Beispielsweise können Ingenieure die Nutzung als Anzahl der Klicks definieren, während Produktmanager die Nutzung als zahlende Kunden in einem bestimmten Monat definieren könnten. Sie können derzeit keine unterschiedlichen Definitionen im selben Modell geben.
Warum sagt Copilot, dass es in meinem semantischen Modell kein Feld sehen kann, obwohl es Teil des KI-Schemas ist?
In Szenarien, in denen Ihr Semantikmodellschema zu groß ist, damit Copilot eine Antwort rendern können, wird das Schema des Modells reduziert, damit Copilot das Schema verstehen und eine Antwort generieren können. Sie können feststellen, wann dies geschieht, indem Sie die Copilot Diagnose herunterladen und in den Warnungen nach "AgentSchemaReduced" suchen.
Vorbereiten von Daten für KI
Ich erhalte eine Fehlermeldung, die besagt: "Copilot wird derzeit mit dem Datenmodell synchronisiert." Was bedeutet dies?
Damit Copilot die beste Leistung erzielen können, ist es wichtig, dass sie die zugrunde liegenden Daten im Semantikmodell versteht. Der Copilot in Power BI versucht, die zugrunde liegenden Daten zu verstehen, indem er das semantische Modell indiziert, um gezielt nach relevanten Werten zum Abgleich zu suchen. Dieser Prozess ermöglicht es Copilot, Fragen basierend auf der Eingabeaufforderung des Benutzers effektiv zu beantworten.
Betrachten Sie ein Dataset im Zusammenhang mit Hawaii Tourismus. Um Fragen wie "Wie wirkte sich das Wetter auf Touristenbesuche auf Maui aus?" zu beantworten, muss Copilot verstehen, dass Maui ein Instanzwert im semantischen Modell in der Spalte Islandname der Tabelle Island ist.
Damit Copilot diese Instanzwerte effektiv durchsuchen kann, wird das semantische Modell indiziert, wenn Power BI Q&A aktiviert ist. Es wird neu indiziert, wenn Power BI Änderungen am Modell erkennt.
Modellindizierungshäufigkeit
Die Indizierung erfolgt für alle Modelle, für die die Q&A-Einstellung aktiviert ist.
Note
Die Q&A-Einstellung ist standardmäßig für Import- und Direct Lake-Modelle aktiviert. Weitere Details zu dieser Einstellung finden Sie in der Q&A-Einstellungsdokumentation.
Erneute Indizierung tritt auf, wenn eine der folgenden Aktionen ausgeführt wird:
- Für Importmodelle :
- Das Modell wurde veröffentlicht oder an den Dienst erneut veröffentlicht.
- Das Modell wurde über manuelle oder geplante Aktualisierung aktualisiert, und Copilot und Q&A wurden innerhalb der letzten 14 Tage verwendet.
- Für DirectQuery - und Direct Lake-Modelle :
- Das Modell wurde veröffentlicht oder erneut an den Dienst veröffentlicht.
- Der Index ist älter als 24 Stunden, und Copilot sowie F&A wurden innerhalb der letzten 14 Tage verwendet.
Die folgende Meldung in Copilot gibt an, dass sich das Modell derzeit im Indizierungsprozess befindet. Die Nachricht sollte sich nach Abschluss der Indizierung automatisch auflösen.

Note
Dieser Fehler bedeutet nicht, dass Copilot benutzern nicht zur Verfügung steht. Diese Meldung gibt an, dass alle neuen Instanzwerte, die im Modell hinzugefügt oder geändert wurden, möglicherweise nicht in Copilot-Antworten angezeigt werden, bis die Indizierungsaktivität abgeschlossen ist.
Indizierungsmethode
Textspalten im semantischen Modell sind die einzigen Spalten, die indiziert sind. Spalten, die im KI-Schema über das Feature "Daten für KI vorbereiten" ausgeblendet werden, werden nicht indiziert.
Bis zu fünf Millionen Instanzenwerte werden mit Spalten indiziert. Die kleinste Kardinalität wird zuerst indiziert. bestimmt die Kardinalität der Spalte für Importmodelle und bestimmt die Kardinalität der Spalte für DirectQuery-Modelle. Bei DirectQuery-Quellen verwendet die Funktion die Funktion für zugrunde liegende Datenquellen, die sie unterstützen, um ungefähre Spaltenkardinalitäten effizient zu ermitteln.
Um die Überladung des zugrunde liegenden Systems für DirectQuery-Modelle mit einem Zustrom von Abfragen aufgrund der Indizierung weiter zu verhindern, werden die Ergebnisse zwischengespeichert. Die Statistiken werden alle sieben Tage neu komputiert. Wenn während des Indizierungsprozesses die obere Grenze von fünf Millionen Instanzen beim Indizieren der nächsten Spalte überschritten würde, wird die Indizierung der Spalte vollständig übersprungen.
Wenn die Indizierungsgrenze erreicht ist, gibt Copilot weiterhin Antworten basierend auf dem erstellten Index, der nicht alle Instanzwerte enthält. Benutzern wird die folgende Warnung angezeigt, wenn das fragliche Semantikmodell auf den Indizierungsgrenzwert trifft.

Bekannte Einschränkungen
- Die Indizierung hat eine obergrenze von fünf Millionen Instanzenwerten oder 1.000 Modellentitäten (Tabellen/Spalten) für große semantische Modelle.
- Textwerte von 100 oder mehr Zeichen werden nicht indiziert.
- DirectQuery-Modelle indizieren nur Spalten für Datenquellen, die unterstützt werden.
- Die Indizierung für DirectQuery- und Direct Lake-Modelle erfolgt einmal während eines 24-Stunden-Zeitraums, es sei denn, das Modell wird erneut veröffentlicht.
- Wenn die zugrunde liegende Semantikmodellaktualisierung fehlschlägt, ist der Datenindex möglicherweise veraltet, bis die nächste erfolgreiche Semantikmodellaktualisierung ausgeführt wird.
- Die erste Datenindexgenerierung für das semantische Modell kann um 15 Minuten verzögert werden, damit Back-End-Aktivitäten den Index generieren können.