Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: ✅ SQL-Analyseendpunkt und Warehouse in Microsoft Fabric
Benutzerdefinierte SQL-Pools bieten Administratoren mehr Kontrolle darüber, wie Ressourcen für die Verarbeitung von Anforderungen zugeordnet werden. In dieser Schnellstartanleitung konfigurieren Sie benutzerdefinierte SQL-Pools und beobachten die Klassifiziererwerte mithilfe der Fabric-REST-API.
Arbeitsbereichsadministratoren können den Anwendungsnamen (oder Programmnamen) aus der Verbindungszeichenfolge verwenden, um Anforderungen an verschiedene Computepools weiterzuleiten. Arbeitsbereichsadministratoren können auch den Prozentsatz der Ressourcen steuern, auf die jeder SQL-Pool zugreifen kann, unter Berücksichtigung der dynamischen Skalierungsgrenze der Arbeitsbereichskapazität.
Die Fabric-REST-API definiert einen einheitlichen Endpunkt für Vorgänge.
Voraussetzungen
- Zugriff auf ein Lagerelement in einem Arbeitsbereich. Sie sollten der Administratorrolle angehören.
Erhalten der aktuellen Konfiguration
Verwenden Sie die folgende API, um die aktuelle Konfiguration abzurufen.
Fabric-Notizbuch (Beispiel)
Sie können den folgenden Python-Beispielcode in einem Fabric Spark-Notizbuch ausführen.
- Der Code sendet eine
GETAnforderung an die benutzerdefinierte SQL-Poolkonfigurations-API und gibt die benutzerdefinierte SQL-Poolkonfiguration für den Arbeitsbereich zurück. - Das
workspace_idFeld verwendet dasmssparkutils.runtime.context, um die GUID des Arbeitsbereichs zu erhalten, in dem das Notizbuch ausgeführt wird. Um einen benutzerdefinierten SQL-Pool in einem anderen Arbeitsbereich zu konfigurieren, aktualisieren Sie dieworkspace_idGUID des Arbeitsbereichs, in dem Sie die benutzerdefinierten SQL-Pools konfigurieren möchten.
import requests
import json
from notebookutils import mssparkutils
# This will get the workspace_id where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspaceId = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspaceId}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='get', url=url, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print(json.dumps(response.json(), indent=4))
else:
print(response.text)
Konfigurieren von benutzerdefinierten SQL-Pools
Im folgenden Python-Beispiel werden benutzerdefinierte SQL-Pools aktiviert und konfiguriert. Sie können diesen Python-Code in einem Fabric Spark-Notizbuch ausführen.
- Die Konfiguration benutzerdefinierter SQL-Pools ist nur aktiv, wenn
customSQLPoolsEnableddas Attribut auf "true" festgelegt ist. Sie können eine Nutzlast in dercustomSQLPoolsObjektdefinition definieren, aber wenn Sie "customSQLPoolsEnabled " nicht auf "true" festlegen, wird die Nutzlast ignoriert und die autonome Workloadverwaltung verwendet. - Der Code konfiguriert zwei benutzerdefinierte SQL-Pools
ContosoSQLPoolundAdhocPool.- Die
ContosoSQLPoolOption ist so festgelegt, dass 70% der verfügbaren Ressourcen empfangen werden. Der Klassifizierer "Anwendungsname" hat den Wert vonMyContosoApp. - Alle SQL-Abfragen, die aus einer Verbindungszeichenfolge stammen, die den
MyContosoAppAnwendungsnamen angibt, werden in denContosoSQLPoolbenutzerdefinierten SQL-Pool klassifiziert und haben Zugriff auf 70% der Gesamtknoten der platzfähigen Kapazität. - Alle SQL-Abfragen, die nicht im Anwendungsnamen der Verbindungszeichenfolge enthalten
MyContosoAppsind, werden an denAdhocbenutzerdefinierten SQL-Pool gesendet, der als Standardpool definiert ist. Diese Anfragen erhalten Zugriff auf 30% der Gesamtknoten der burstfähigen Kapazität.
- Die
- Alle benutzerdefinierten SQL-Poolkonfigurationen müssen über einen SQL-Standardpool verfügen, der durch Festlegen des
isDefaultAttributs auf "true" identifiziert wird. - Die Summe aller
maxResourcePercentageWerte muss kleiner oder gleich 100%sein. - Das
workspace_idFeld verwendet dasmssparkutils.runtime.context, um die GUID des Arbeitsbereichs zu erhalten, in dem das Notizbuch ausgeführt wird. Um einen benutzerdefinierten SQL-Pool in einem anderen Arbeitsbereich zu konfigurieren, aktualisieren Sie dieworkspace_idGUID des Arbeitsbereichs, in dem Sie die benutzerdefinierten SQL-Pools konfigurieren möchten.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": True,
"customSQLPools": [
{
"name": "ContosoSQLPool",
"isDefault": False,
"maxResourcePercentage": 70,
"optimizeForReads": False,
"classifier": {
"type": "Application Name",
"value": [
"MyContosoApp"
]
}
},
{
"name": "AdhocPool",
"isDefault": True,
"maxResourcePercentage": 30,
"optimizeForReads": True
}
]
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools configured successfully.")
else:
print(response.text)
Tipp
Verwenden Sie die folgenden hilfreichen Klassifizierungswerte für den Anwendungsnamen (regex) für den Datenverkehr von Fabric:
- Verwenden Sie
^Data Integration-to[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89abAB][0-9a-fA-F]{3}-[0-9a-fA-F]{12}$, um Abfragen aus Fabric-Pipelines zu klassifizieren. - Verwenden Sie
^(PowerBIPremium-DirectQuery|Mashup Engine(?: \(PowerBIPremium-Import\))?)zum Klassifizieren von Abfragen aus Power BI . - Verwenden Sie den SQL-Abfrage-Editor des Fabric-Portals, um Abfragen zu klassifizieren.
Festlegen des Anwendungsnamens in SQL Server Management Studio (SSMS)
Der Klassifizierer für benutzerdefinierte SQL-Pools verwendet den Anwendungsnamen oder den Programmnamenparameter allgemeiner Verbindungszeichenfolgen.
Geben Sie in SQL Server Management Studio (SSMS) den Servernamen für das Lager an und stellen Sie die Authentifizierung bereit. Microsoft Entra MFA wird empfohlen.
Wählen Sie die Schaltfläche "Erweitert " aus.
Ändern Sie auf der Seite "Erweiterte Eigenschaften " unter "Kontext" den Wert des Anwendungsnamens in
MyContosoApp.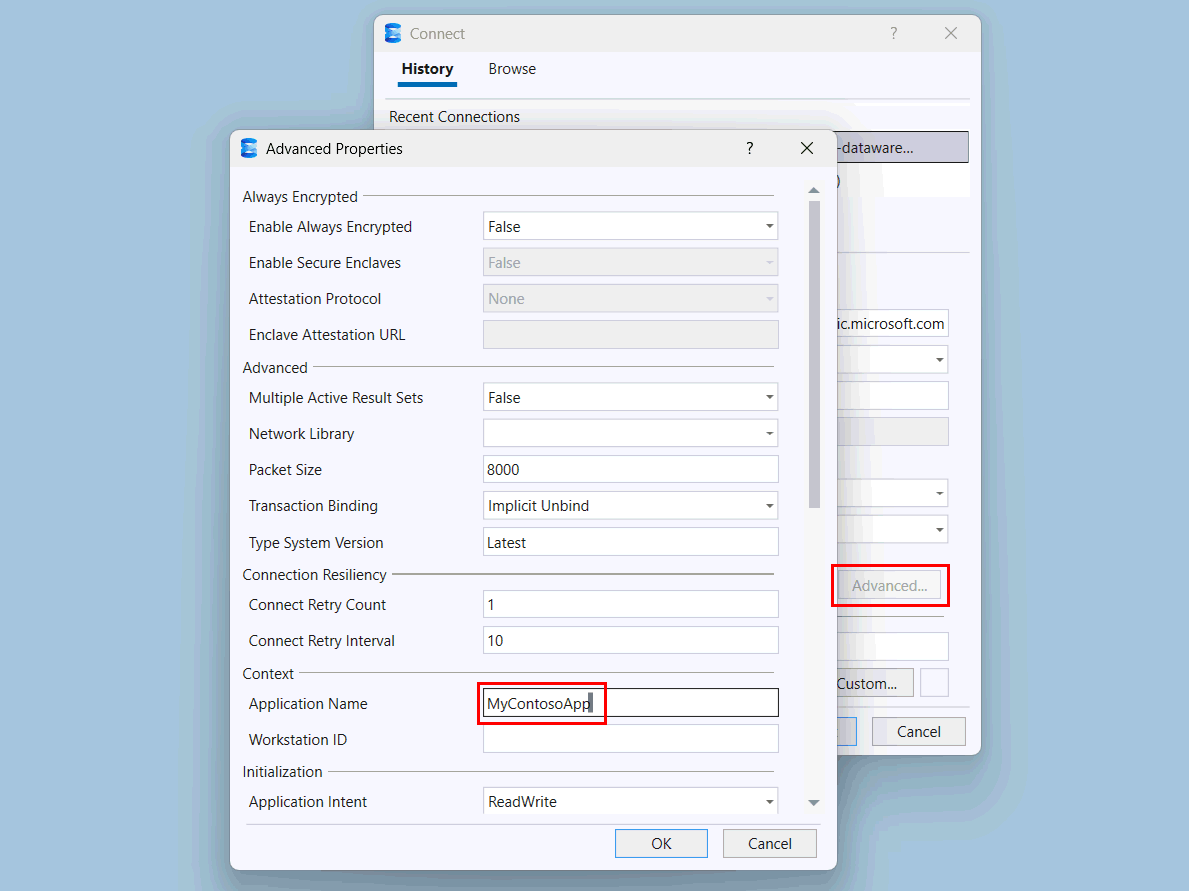
Wählen Sie OK aus.
Wählen Sie Verbinden aus.
Um einige Beispielaktivitäten zu generieren, verwenden Sie diese Verbindung in SSMS, um eine einfache Abfrage in Ihrem Lager auszuführen, z. B.:
SELECT * FROM dbo.DimDate;

Einblicke in Abfragen des benutzerdefinierten SQL-Pools beobachten
Überprüfen Sie die
sys.dm_exec_sessionsdynamische Verwaltungsansicht, um zu sehen, dassMyContosoAppals der Anwendungsname erkannt wird, der von SSMS an das SQL-Modul übergeben wird.SELECT session_id, program_name FROM sys.dm_exec_sessions WHERE program_name = 'MyContosoApp';Beispiel:
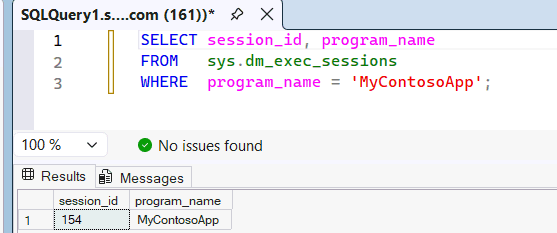
Da der
program_nameAnwendungsname imMyContosoAppbenutzerdefinierten SQL-Pool übereinstimmt, verwendet diese Abfrage die Ressourcen in diesem Pool. Um zu beweisen, welchen benutzerdefinierten SQL-Pool die Abfrage verwendet hat, können Sie die queryinsights.exec_requests_history Systemansicht abfragen. Warten Sie 10 bis 15 Minuten, bis Abfrageerkenntnisse aufgefüllt werden, und führen Sie dann die folgende Abfrage aus.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE program_name = 'MyContosoApp';Sie können den Pool einer Abfrage auch anhand ihrer Anweisungs-ID identifizieren. Führen Sie im SQL-Abfrage-Editor des Fabric-Portals eine Abfrage für Ihren Warehouse- oder SQL-Analyseendpunkt aus.
SELECT * FROM dbo.DimDate;Wählen Sie die Registerkarte "Nachrichten" aus, und notieren Sie die Statement-ID für die Abfrageausführung. Im SQL-Abfrage-Editor ist das
program_nameDMS_user, das Sie zuvor so konfiguriert haben, dass es den benutzerdefinierten SQL-PoolMyContosoAppverwendet.Warten Sie 10-15 Minuten, bis die Abfrageergebnisse verfügbar sind.
Rufen Sie die
sql_pool_nameund andere Informationen ab, um zu überprüfen, ob der richtige benutzerdefinierte SQL-Pool verwendet wurde.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE distributed_statement_id = '<Statement ID>';
Wiederherstellen der Konfiguration von benutzerdefinierten SQL-Pools
Um den Arbeitsbereich in den ursprünglichen Zustand zurückzugeben, ändern Sie die customSQLPoolsEnabled Eigenschaft in False. Wenn Sie die Konfiguration benutzerdefinierter SQL-Pools beibehalten möchten, müssen Sie jeden Poolnamen wie in der customSQLPools Liste übergeben.
In diesem Beispiel-Python-Code werden benutzerdefinierte SQL-Pools deaktiviert und auf die autonome Workloadverwaltungskonfiguration von SELECT und nicht-SELECT-Pools zurückgesetzt. Eine PATCH Anforderung wird aufgerufen, wobei die Eigenschaft customSQLPoolsEnabled auf False gesetzt ist.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": False,
"customSQLPools": []
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools successfully disabled.")
else:
print(response.text)