Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Von Bedeutung
Dieses Feature befindet sich in der Vorschauphase.
Fabric Runtime bietet eine nahtlose Integration in das Microsoft Fabric-Ökosystem und bietet eine robuste Umgebung für Data Engineering- und Data Science-Projekte, die von Apache Spark unterstützt werden.
In diesem Artikel wird fabric Runtime 2.0 Public Preview vorgestellt, die neueste Runtime, die für Big Data-Berechnungen in Microsoft Fabric entwickelt wurde. Es hebt die wichtigsten Features und Komponenten hervor, die diese Version zu einem erheblichen Fortschritt für skalierbare Analysen und erweiterte Workloads machen.
Fabric Runtime 2.0 enthält die folgenden Komponenten und Upgrades, die entwickelt wurden, um Ihre Datenverarbeitungsfunktionen zu verbessern:
- Apache Spark 4.0
- Betriebssystem: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Skala: 2.13
- Python: 3.12
- Delta Lake: 4.0
- R: 4.5.2
Tipp
Fabric Runtime 2.0 enthält Unterstützung für das native Ausführungsmodul, das die Leistung ohne mehr Kosten erheblich verbessern kann. Sie können das systemeigene Ausführungsmodul auf Umgebungsebene aktivieren, sodass alle Aufträge und Notizbücher automatisch die erweiterten Leistungsfunktionen erben.
Aktivieren von Runtime 2.0
Sie können Runtime 2.0 entweder auf Arbeitsbereichsebene oder auf Der Umgebungselementebene aktivieren. Verwenden Sie die Arbeitsbereichseinstellung, um Runtime 2.0 als Standard für alle Spark-Workloads in Ihrem Arbeitsbereich anzuwenden. Erstellen Sie alternativ ein Umgebungsobjekt mit Runtime 2.0, das mit bestimmten Notizbüchern oder Spark-Auftragsdefinitionen verwendet werden soll, die die Arbeitsbereichstandards außer Kraft setzen.
Aktivieren von Runtime 2.0 in arbeitsbereichseinstellungen
So legen Sie Runtime 2.0 als Standard für den gesamten Arbeitsbereich fest:
Navigieren Sie zur Seite "Arbeitsbereichseinstellungen" in Ihrem Fabric-Arbeitsbereich .
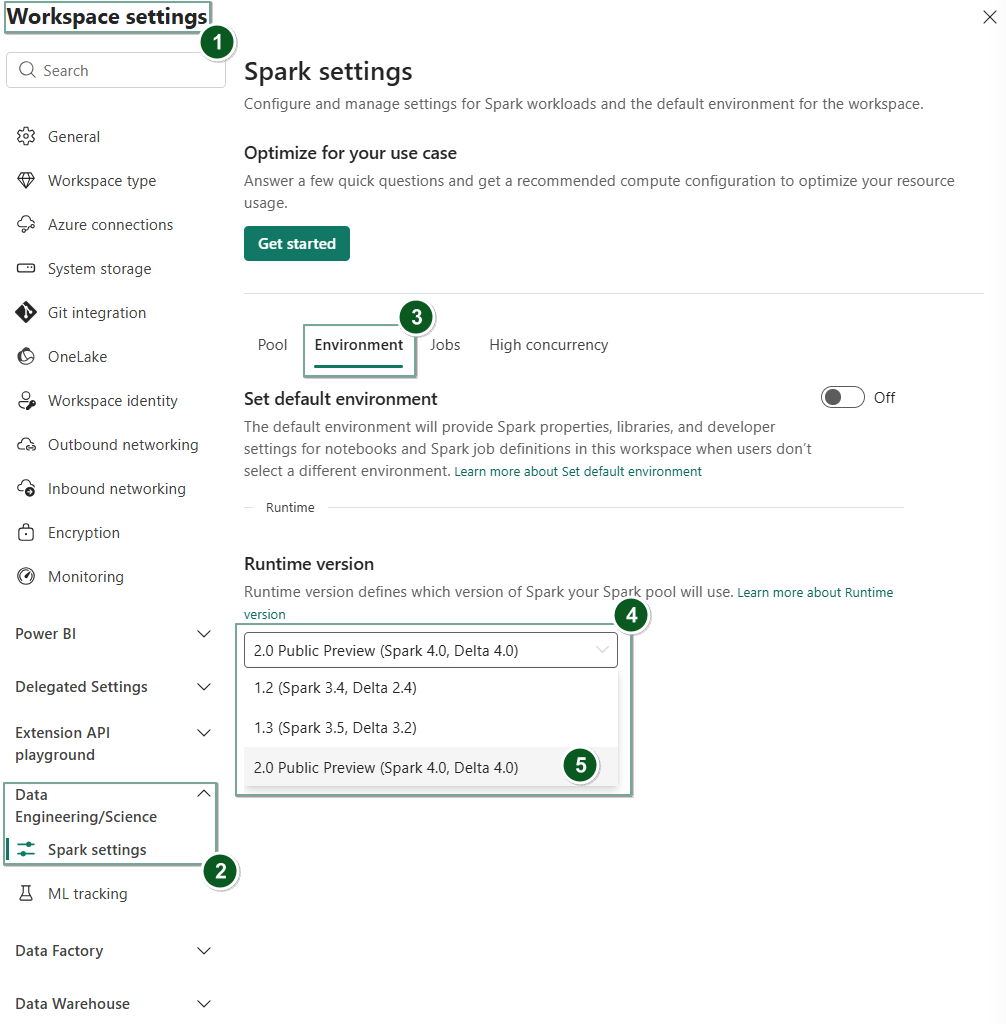
Wählen Sie die Registerkarte "Datentechnik/Wissenschaft " und dann "Spark"-Einstellungen aus.
Wählen Sie die Registerkarte Umgebung aus.
Wählen Sie unter der Dropdownliste "Laufzeitversion" die Option 2.0 Public Preview (Spark 4.0, Delta 4.0) aus, und speichern Sie Ihre Änderungen.
Runtime 2.0 wird als Standardlaufzeit für Ihren Arbeitsbereich festgelegt.

Aktivieren von Runtime 2.0 in einem Umgebungselement
So verwenden Sie Runtime 2.0 mit bestimmten Notizbüchern oder Spark-Auftragsdefinitionen:
Erstellen Sie ein neues Umgebungselement , oder öffnen Sie ein vorhandenes Element.
Wählen Sie im Dropdown-Menü Runtime die Option 2.0 Public Preview (Spark 4.0, Delta 4.0)
Saveund bestätigen SiePublishIhre Änderungen.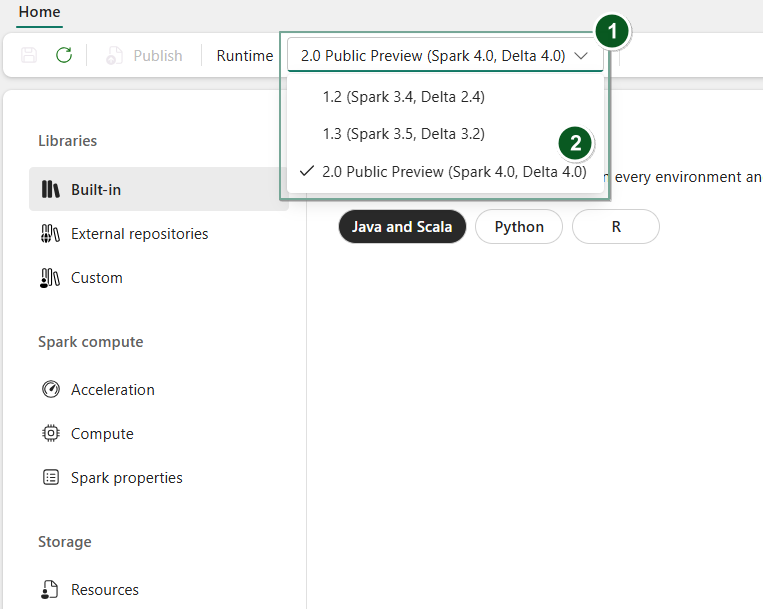
Als Nächstes können Sie dieses Environment-Element mit Ihrem
NotebookoderSpark Job Definitionverwenden.

Sie können jetzt mit den neuesten Verbesserungen und Funktionen experimentieren, die in Fabric Runtime 2.0 (Spark 4.0 und Delta Lake 4.0) eingeführt wurden.
Tipp
Der Anfängliche Spark-Sitzungsstart für Runtime 2.0 kann während der öffentlichen Vorschau einige Minuten dauern. Um Verzögerungen beim Kaltstart zu reduzieren, verwenden Sie benutzerdefinierte Livepools (Vorschau) zum Vorabwärmen von Spark-Pools oder konfigurieren Sie Ressourcenprofile, um Ressourcen im Voraus zuzuweisen.
Hinweis
Das WASB-Protokoll für Azure Storage-Konten mit allgemeinem Zweck v2 (GPv2) ist veraltet. Verwenden Sie stattdessen das neueste ABFS-Protokoll zum Lesen und Schreiben in GPv2-Speicherkonten.
Öffentliche Vorschau
Die öffentliche Vorschauphase von Fabric Runtime 2.0 bietet Ihnen Zugriff auf neue Features und APIs von Spark 4.0 und Delta Lake 4.0. Mit der Vorschau können Sie die neuesten Spark- und Delta-basierten Verbesserungen sofort verwenden sowie eine reibungslose Bereitschaft und einen reibungslosen Übergang für erweiterte und verbesserte Änderungen wie die neueren Java-, Scala- und Python-Versionen sicherstellen.
Tipp
Um aktuelle Informationen, eine ausführliche Liste der Änderungen und spezifische Versionshinweise für Fabric-Runtimes zu erhalten, sollten Sie Spark-Runtimes – Versionen und Updates lesen und abonnieren.
Wichtigste Highlights
Verbesserungen der Leistungs- und Ausführungs-Engine
Fabric Runtime 2.0 enthält das systemeigene Ausführungsmodul, das erhebliche Leistungsverbesserungen gegenüber Open-Source-Spark bietet. Die Engine verwendet die vektorisierte Verarbeitung, um Spark-Abfragen in der Lakehouse-Infrastruktur zu beschleunigen, ohne dass Codeänderungen erforderlich sind.
Wichtige Leistungsfeatures in Runtime 2.0:
- Bis zu sechs mal schneller: Benchmarks zeigen im Vergleich zu Open-Source-Spark auf TPC-DS Workloads bis zu sechs mal schnellere Leistung an.
- Vektorisierte CSV-Analyse: Das systemeigene Ausführungsmodul enthält einen vektorisierten CSV-Parser, der die CSV-Erfassung und Abfrageworkloads beschleunigt. Vektorisierte JSON-Analyse und Spark Structured Streaming-Unterstützung sind für zukünftige Updates geplant.
Informationen zum Aktivieren des nativen Ausführungsmoduls finden Sie unter natives Ausführungsmodul für Fabric Data Engineering.
Apache Spark 4.0
Apache Spark 4.0 markiert einen bedeutenden Meilenstein als die erste Version der 4.x-Serie, die den kollektiven Aufwand der lebendigen Open-Source-Community verkörpern.
In dieser Version wird Spark SQL erheblich mit leistungsstarken neuen Features erweitert, die zur Steigerung der Ausdrucksfähigkeit und Vielseitigkeit für SQL-Workloads entwickelt wurden, z. B. unterstützung von VARIANT-Datentypen, SQL benutzerdefinierte Funktionen, Sitzungsvariablen, Pipesyntax und Zeichenfolgensortierung. PySpark zeigt kontinuierliche Bemühungen um sowohl die funktionale Vielseitigkeit als auch das gesamte Entwicklererlebnis, indem es eine native Plotting-API, eine neue Python-Datenquellen-API, Unterstützung für Python UDTFs sowie einheitliches Profiling für PySpark UDFs bietet, neben zahlreichen weiteren Verbesserungen. Strukturiertes Streaming entwickelt sich mit wichtigen Ergänzungen, die eine bessere Kontrolle und einfaches Debuggen bieten, insbesondere die Einführung der Willkürlichen Zustands-API v2 für eine flexiblere Zustandsverwaltung und die Zustandsdatenquelle zum einfacheren Debuggen.
Die vollständige Liste und detaillierte Änderungen finden Sie hier: https://spark.apache.org/releases/spark-release-4-0-0.html.
Hinweis
In Spark 4.0 ist SparkR veraltet und kann in einer zukünftigen Version entfernt werden.
Delta Lake 4.0
Delta Lake 4.0 ist ein kollektives Engagement, Delta Lake über Formate hinweg interoperabel zu machen, einfacher zu arbeiten und leistungsfähiger zu sein. Delta 4.0 ist eine Meilensteinversion, die mit leistungsstarken neuen Features, Leistungsoptimierungen und grundlegenden Verbesserungen für die Zukunft offener Datenseehäuser verpackt ist.
Sie können die vollständige Liste und detaillierte Änderungen, die mit Delta Lake 3.3 und 4.0 eingeführt wurden, hier überprüfen: https://github.com/delta-io/delta/releases/tag/v3.3.0. https://github.com/delta-io/delta/releases/tag/v4.0.0.
Datenlayout und -optimierung
Runtime 2.0 unterstützt Datenlayout- und Optimierungsfeatures für Delta-Tabellen:
- Z-Sortierung: Organisieren Sie Daten in Delta-Tabellendateien nach angegebenen Spalten, um die Abfrageleistung für gefilterte Abfragen zu verbessern.
- Liquid Clustering: Ein flexibler Clustering-Ansatz, der das Datenlayout automatisch ohne manuelle Wartung optimiert.
- Paralleles Laden von Delta-Snapshots: Das native Ausführungsmodul lädt Delta-Tabellen-Snapshots parallel und reduziert dadurch die Startzeit von Abfragen bei großen Tabellen.
Von Bedeutung
Delta Lake 4.0-spezifische Features sind experimentell und funktionieren nur an Spark-Erfahrungen, z. B. Notebooks und Spark Job Definitions. Wenn Sie dieselben Delta Lake-Tabellen über mehrere Microsoft Fabric-Workloads hinweg verwenden müssen, aktivieren Sie diese Features nicht. Wenn Sie mehr darüber erfahren möchten, welche Protokollversionen und -features für alle Microsoft Fabric-Umgebungen kompatibel sind, lesen Sie die Interoperabilität des Delta Lake-Tabellenformats.
Rechenverwaltung in Runtime 2.0
Runtime 2.0 unterstützt die folgenden Rechnerverwaltungsfeatures:
- Ressourcenprofile: Konfigurieren Sie vordefinierte Ressourcenzuordnungen für Spark-Sitzungen so, dass sie den Workloadanforderungen entsprechen und Kosten steuern.
- Benutzerdefinierte Livepools (Vorschau):Erstellen Sie dedizierte, vorgewärmte Spark-Pools, die die Startzeit der Sitzung reduzieren. Benutzerdefinierte Livepools sind in der Vorschau für Runtime 2.0-Workloads verfügbar.
Einschränkungen und Hinweise
- Delta Lake 4.0-spezifische Features sind experimentell und funktionieren nur für Spark-Oberflächen, z. B. Notizbücher und Spark-Auftragsdefinitionen. Wenn Sie die gleichen Delta Lake-Tabellen für mehrere Fabric-Workloads verwenden müssen, aktivieren Sie diese Features nicht. Weitere Informationen finden Sie unter Interoperabilität des Delta Lake-Tabellenformats.
- Laufzeit 2.0 befindet sich in der öffentlichen Vorschau. Einige Features und APIs können sich vor der allgemeinen Verfügbarkeit ändern.
- Die VS Code-Erweiterung für Fabric Spark unterstützt Runtime 2.0 für die Entwicklung von Notizbüchern und Spark-Auftragsdefinitionen.
Verwandte Inhalte
- Apache Spark Runtimes in Fabric – Übersicht, Versionsverwaltung und Unterstützung für mehrere Runtimes
- Anleitung zur Migration von Spark Core
- Anleitung zur Migration von SQL, DataSets und DataFrame
- Anleitung zur Migration von strukturiertem Streaming
- Anleitung zur Migration von MLlib (Maschinelles Lernen)
- Anleitung zur Migration von PySpark (Python in Spark)
- Anleitung zur Migration von SparkR (R in Spark)