Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Microsoft Fabric Data Engineering- und Data Science-Erfahrungen arbeiten auf einer vollständig verwalteten Spark Compute-Plattform. Standardmäßig verwenden alle Spark-Aufträge in einem Arbeitsbereich dieselben Pool- und Ressourceneinstellungen, aber unterschiedliche Workloads weisen häufig unterschiedliche Anforderungen auf. Eine einfache Datentransformation benötigt nicht den gleichen Treiberspeicher wie ein groß angelegter Machine Learning-Job.
Mithilfe von Fabric-Umgebungen können Sie die Spark-Computekonfiguration pro Workload anpassen, sodass jedes Notizbuch oder jede Spark-Auftragsdefinition mit der richtigen Laufzeitversion, einem Pool und einer Treiber-/Ausführungsgröße ausgeführt werden kann, ohne die arbeitsbereichweiten Standardwerte zu ändern.
Konfigurieren von Rechner-Einstellungen auf der Arbeitsbereichsebene
Arbeitsbereichsadministratoren steuern, ob Umgebungselemente die Standardberechnungskonfiguration des Arbeitsbereichs überschreiben können. Durch die Deaktivierung der Anpassung auf Elementebene wird eine konsistente Ressourcennutzung im gesamten Arbeitsbereich sichergestellt. Durch die Aktivierung erhalten Mitglieder und Mitwirkende die Flexibilität, die Berechnung für einzelne Workloads zu optimieren.
Wechseln Sie in Ihrem Browser zum Fabric-Arbeitsbereich im Fabric-Portal.
Wählen Sie Arbeitsbereichseinstellungen aus.
Wählen Sie "Data Engineering/Science" und dann "Spark"-Einstellungen aus.
Wählen Sie die Registerkarte "Pool " aus.
Aktivieren Sie den Umschalter Anpassen der Berechnungskonfigurationen für Artikel auf Ein.
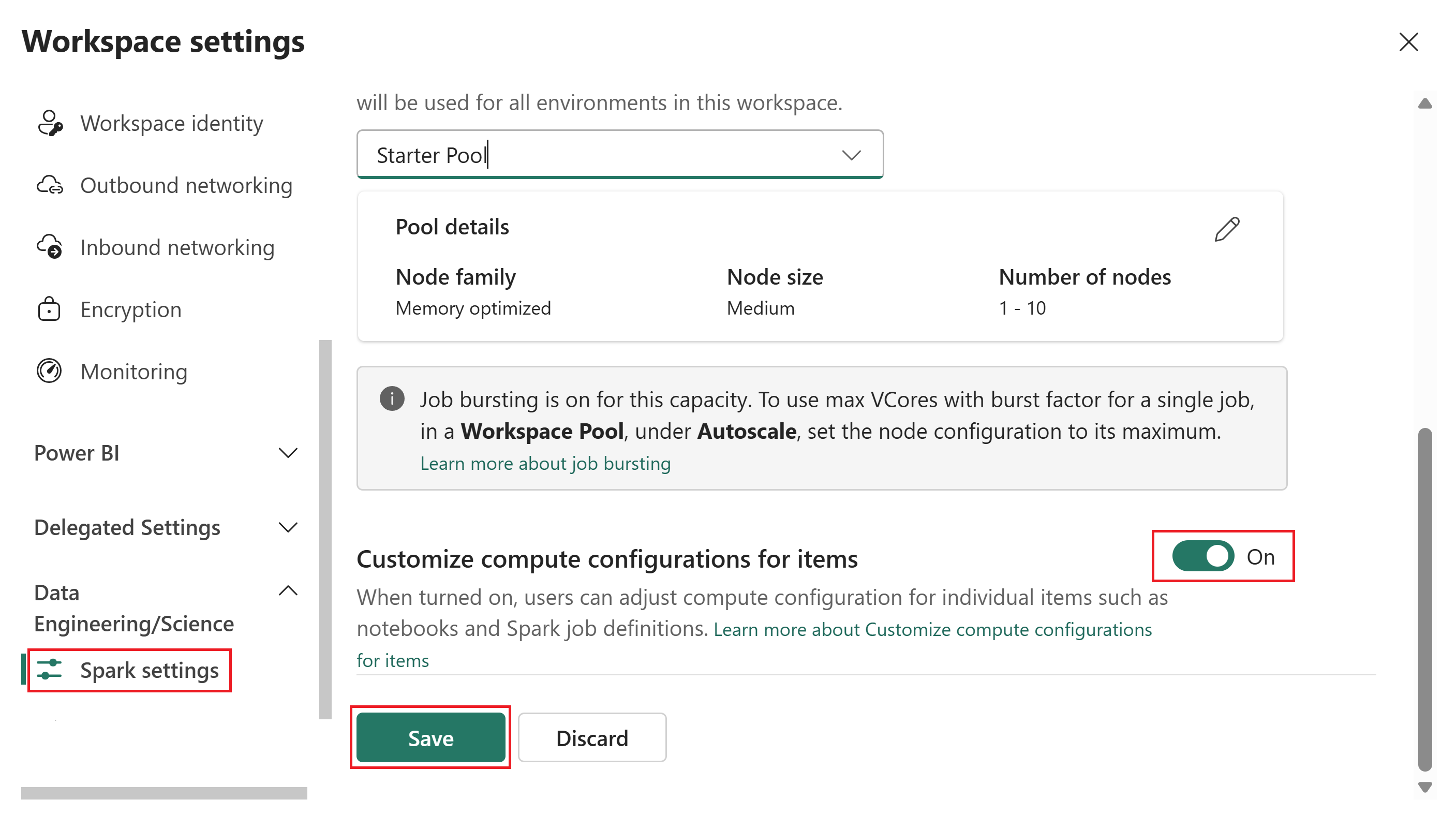
Wenn diese Umschaltfläche aktiviert ist, können Mitglieder und Mitwirkende Computekonfigurationen auf Sitzungsebene in einer Fabric-Umgebung ändern. Wenn sie deaktiviert ist, wird der Compute-Abschnitt in Umgebungselementen deaktiviert, und alle Spark-Aufträge verwenden den Standardpool des Arbeitsbereichs.
Wählen Sie Speichern aus.

Konfigurieren der Berechnung in einer Umgebung
Nachdem ein Arbeitsbereichsadministrator die Anpassung auf Elementebene aktiviert hat, können Sie Computeeinstellungen innerhalb eines Umgebungselements konfigurieren. Dazu gehört die Auswahl einer Spark-Laufzeit, das Auswählen eines Pools sowie das Optimieren von Treiber- und Executorressourcen.
Auswählen einer Spark-Laufzeit
Öffnen Sie das Umgebungselement.
Wählen Sie auf der Registerkarte " Start " das Dropdownmenü "Runtime " und dann eine Laufzeitversion aus.
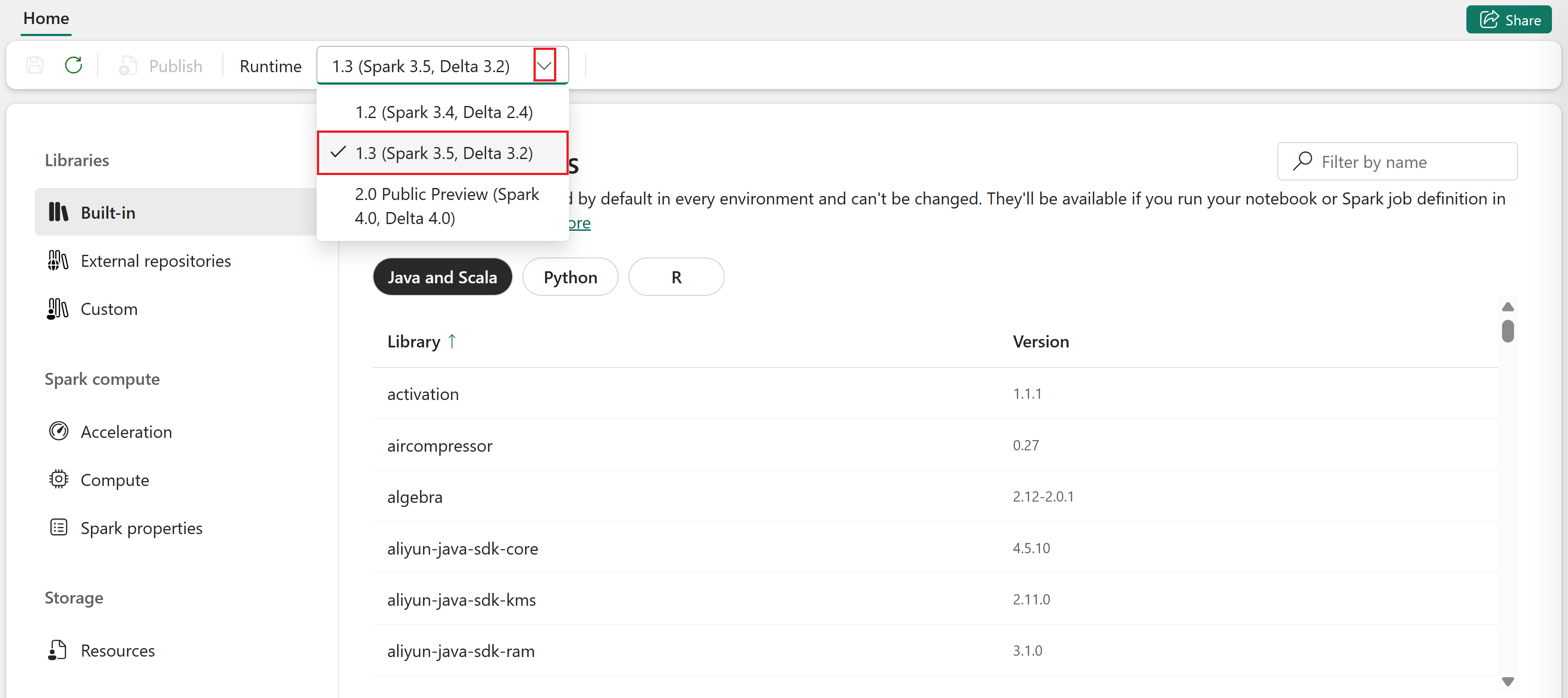

Jede Spark-Runtime verfügt über eigene Standardeinstellungen und vorinstallierte Pakete.
Von Bedeutung
- Laufzeitänderungen werden erst wirksam, wenn Sie die Umgebung speichern und veröffentlichen.
- Wenn vorhandene Bibliotheken oder Computeeinstellungen nicht mit der ausgewählten Laufzeit kompatibel sind, schlägt die Veröffentlichung fehl. Entfernen oder aktualisieren Sie die inkompatiblen Einstellungen, und veröffentlichen Sie dann erneut.
- Schrittweise Veröffentlichungsanweisungen finden Sie unter Speichern und Veröffentlichen von Änderungen.
Wählen Sie einen Pool und optimieren Sie die Recheneigenschaften
Öffnen Sie die Umgebung, und wechseln Sie zum Abschnitt "Compute" .
Wählen Sie unter "Umgebungspool" den Startpool oder einen benutzerdefinierten Pool aus, der von Ihrem Arbeitsbereichsadministrator erstellt wurde.
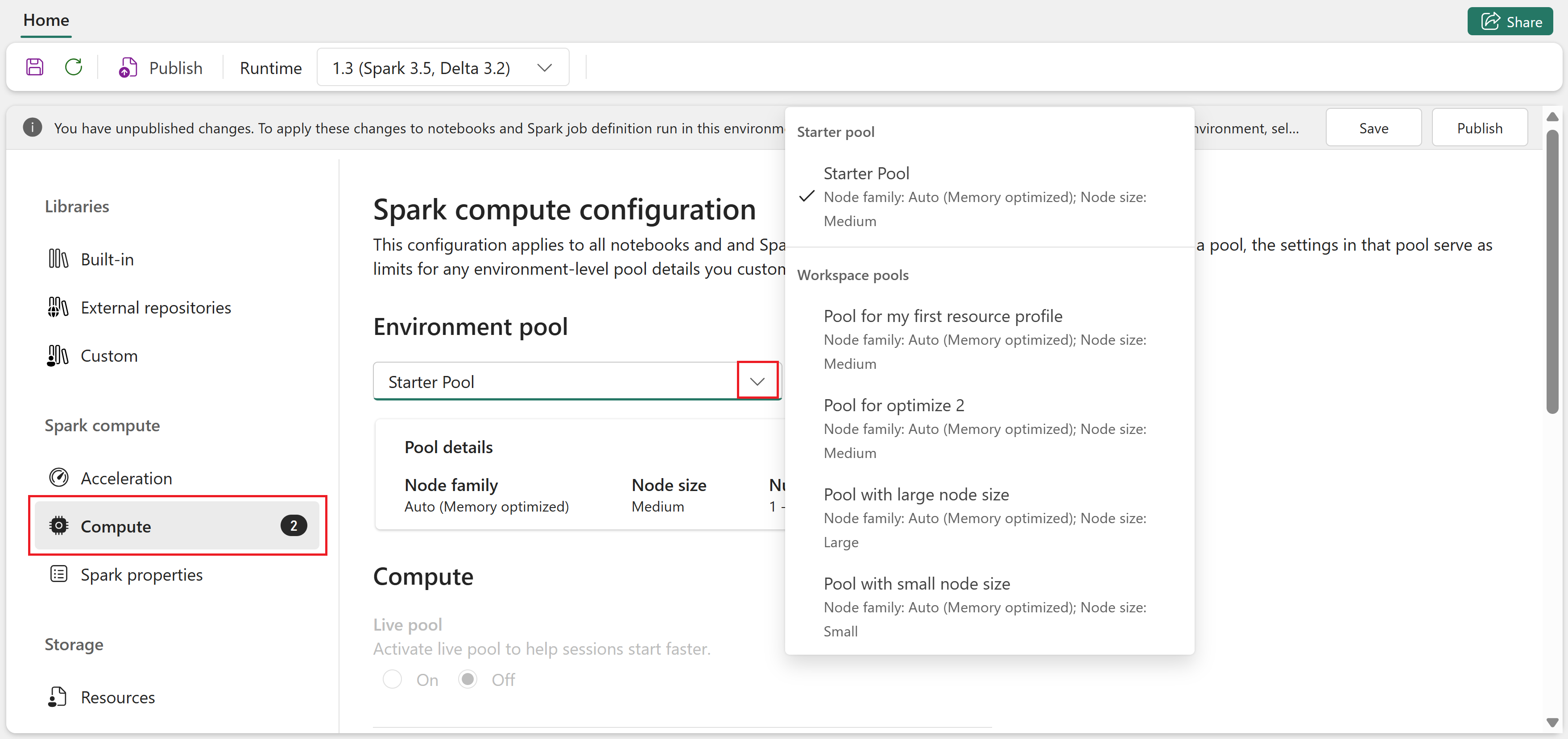
Verwenden Sie die Dropdown-Menüs auf der Seite "Compute", um Spark-Eigenschaften auf Sitzungsebene für den ausgewählten Pool zu konfigurieren. Verfügbare Werte hängen von der Knotengröße des Pools ab.

Die Eigenschaften umfassen:
- Spark-Treiberkerne – Anzahl der Kerne, die dem Spark-Treiber zugeordnet sind.
- Spark-Treiberspeicher – Dem Spark-Treiber zugeordneter Arbeitsspeicher.
- Spark executor cores – Anzahl der Kerne, die jedem Executor zugeordnet sind.
- Spark executor memory – Menge des Arbeitsspeichers, der jedem Executor zugeordnet ist.


Ausführliche Informationen zu verfügbaren Poolgrößen und Ressourcengrenzwerten finden Sie unter Spark compute in Fabric.
Hinweis
Spark-Eigenschaften, die über spark.conf.set Steuerelementparameter auf Anwendungsebene festgelegt wurden und nicht mit den hier beschriebenen Umgebungsberechnungseinstellungen zusammenhängen.