Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tip
Microsoft Fabric Data Warehouse ist ein relationales Enterprise-Warehouse auf einem Data Lake-Fundament mit zukunftsfähiger Architektur, integrierter KI und neuen Features. Wenn Sie mit Data Warehouse noch nicht vertraut sind, beginnen Sie mit Fabric Data Warehouse. Vorhandene dedizierte SQL-Pool-Workloads können auf Fabric aktualisieren, um neue Funktionen in den Bereichen Data Science, Echtzeitanalyse und Berichterstellung zu nutzen.
In dieser Schnellstartanleitung erstellen Sie einen Workloadklassifizierer zum Zuweisen von Abfragen zu einer Workloadgruppe. Der Klassifizierer weist Anforderungen vom ELTLogin-SQL-Benutzer der Workloadgruppe DataLoads zu. Befolgen Sie den Schnellstart: Konfigurieren der Workloadisolation, um die Workloadgruppe DataLoads zu erstellen. In diesem Tutorial wird ein Workloadklassifizierer mit der Option „WLM_LABEL“ erstellt, um die korrekte weitere Klassifizierung von Anforderungen zu unterstützen. Der Klassifizierer weist diesen Anforderungen ebenfalls die HIGHWichtigkeit der Arbeitslast zu.
Wenn Sie über kein Azure-Abonnement verfügen, können Sie ein kostenloses Azure-Konto erstellen, bevor Sie beginnen.
Melden Sie sich auf dem Azure-Portal an.
Melden Sie sich beim Azure-Portal an.
Hinweis
Das Erstellen einer Instanz des dedizierten SQL-Pools in Azure Synapse Analytics kann zu einem neuen kostenpflichtigen Dienst führen. Weitere Informationen finden Sie unter Azure Synapse Analytics – Preise.
Voraussetzungen
In dieser Schnellstartanleitung wird vorausgesetzt, dass Sie bereits über eine Instanz des dedizierten SQL-Pools und über CONTROL DATABASE-Berechtigungen verfügen. Verwenden Sie die Anleitung unter Erstellen und Verbinden – Portal, um bei Bedarf einen dedizierten SQL-Pool namens mySampleDataWarehouse zu erstellen.
Die Workloadgruppe DataLoads ist vorhanden. Informationen zum Erstellen der Workloadgruppe finden Sie im Tutorial Schnellstart: Konfigurieren der Workloadisolation.
Wichtig
Der dedizierte SQL-Pool muss online sein, damit die Workloadverwaltung konfiguriert werden kann.
Erstellen einer Anmeldung für „ELTLogin“
Erstellen Sie eine SQL Server-Authentifizierungsanmeldung in der master-Datenbank, indem Sie CREATE LOGIN für ELTLogin verwenden.
IF NOT EXISTS (SELECT * FROM sys.sql_logins WHERE name = 'ELTLogin')
BEGIN
CREATE LOGIN [ELTLogin] WITH PASSWORD='<strongpassword>'
END
;
Erstellen eines Benutzers und Zuweisen von Berechtigungen
Nach der Erstellung der Anmeldung muss ein Benutzer in der Datenbank erstellt werden. Verwenden Sie CREATE USER, um das ELTRole-Objekt für den SQL-Benutzer in mySampleDataWarehouse zu erstellen. Im Rahmen dieses Tutorials wird die Klassifizierung getestet. Gewähren Sie ELTLogin daher Berechtigungen für mySampleDataWarehouse.
IF NOT EXISTS (SELECT * FROM sys.database_principals WHERE name = 'ELTLogin')
BEGIN
CREATE USER [ELTLogin] FOR LOGIN [ELTLogin]
GRANT CONTROL ON DATABASE::mySampleDataWarehouse TO ELTLogin
END
;
Konfigurieren der Workloadklassifizierung
Mithilfe der Klassifizierung können Sie Anforderungen, die auf verschiedenen Regeln basieren, an eine Workloadgruppe weiterleiten. Im Schnellstart: Konfigurieren der Workloadisolation Tutorial haben wir die Workloadgruppe DataLoads erstellt. Nun erstellen Sie einen Workloadklassifizierer, um Abfragen an die Workloadgruppe DataLoads weiterzuleiten.
Navigieren Sie zur Seite des dedizierten SQL-Pools mySampleDataWarehouse.
Wählen Sie Workloadverwaltung aus.
Wählen Sie
Einstellungen & Klassifizierer rechts neben derWorkloadgruppe aus. 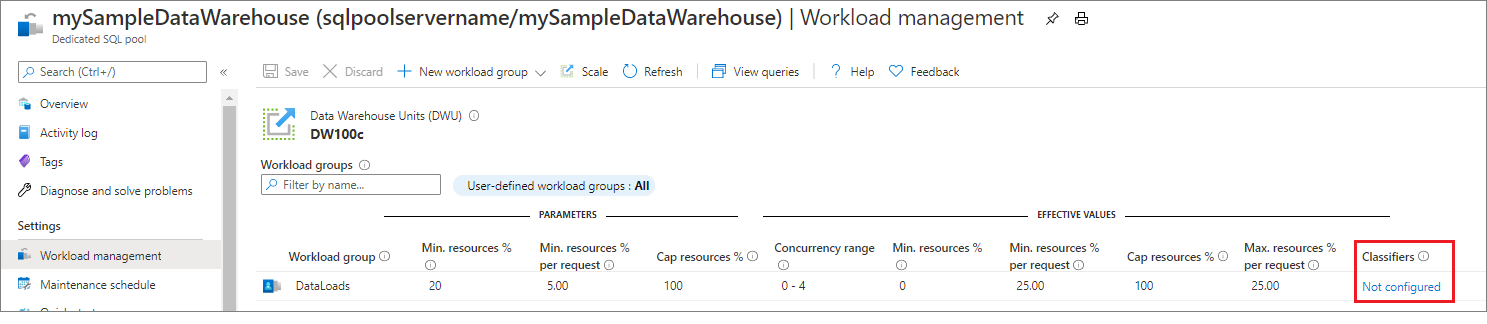
Wählen Sie in der Spalte „Klassifizierer“ die Option Nicht konfiguriert aus.
Wählen Sie + Klassifizierer hinzufügen aus.
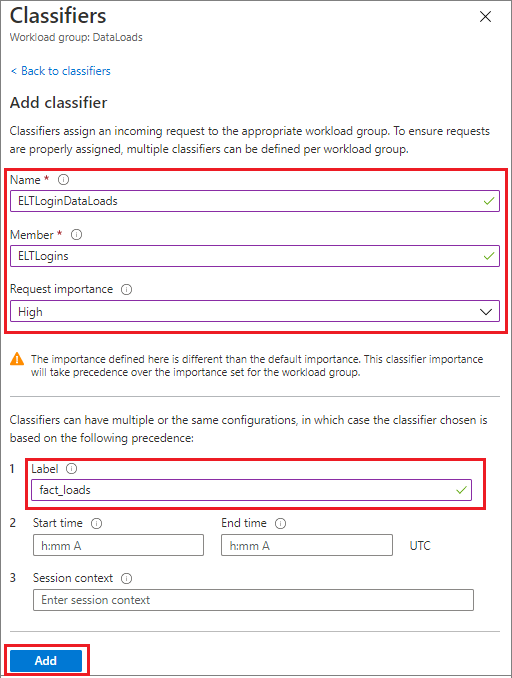
Geben Sie
ELTLoginDataLoadsfür Name ein.Geben Sie
ELTLoginfür Mitglied ein.Wählen Sie unter Anforderungsrelevanz die Option
Highaus. Optional, normale Relevanz ist voreingestellt.Geben Sie
fact_loadsfür Label ein.Wählen Sie Hinzufügen.
Wählen Sie Speichern aus.
Überprüfen und Testen der Klassifizierung
Überprüfen Sie in der Katalogsicht sys.workload_management_workload_classifiers, ob der Klassifizierer ELTLoginDataLoads vorhanden ist.
SELECT * FROM sys.workload_management_workload_classifiers WHERE name = 'ELTLoginDataLoads'
Überprüfen Sie in der Katalogansicht sys.workload_management_workload_classifier_details die Details zum Klassifizierer.
SELECT c.[name], c.group_name, c.importance, cd.classifier_type, cd.classifier_value
FROM sys.workload_management_workload_classifiers c
JOIN sys.workload_management_workload_classifier_details cd
ON cd.classifier_id = c.classifier_id
WHERE c.name = 'ELTLoginDataLoads'
Führen Sie die folgenden Anweisungen aus, um die Klassifizierung zu testen. Stellen Sie sicher, dass Sie als ELTLogin verbunden sind und Label in der Abfrage verwendet wird.
CREATE TABLE factstaging (ColA int)
INSERT INTO factstaging VALUES(0)
INSERT INTO factstaging VALUES(1)
INSERT INTO factstaging VALUES(2)
GO
CREATE TABLE testclassifierfact WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT * FROM factstaging
OPTION (LABEL='fact_loads')
Überprüfen Sie mit dem ELTLoginDataLoads Workload-Klassifizierer die CREATE TABLE-Anweisung, die der DataLoads-Workloadgruppe zugeordnet ist.
SELECT TOP 1 request_id, classifier_name, group_name, resource_allocation_percentage, submit_time, [status], [label], command
FROM sys.dm_pdw_exec_requests
WHERE [label] = 'fact_loads'
ORDER BY submit_time DESC
Bereinigen von Ressourcen
So löschen Sie den in diesem Tutorial erstellten Workloadklassifizierer ELTLoginDataLoads:
Klicken Sie rechts neben der Workloadgruppe
DataLoadsauf 1 Klassifizierung.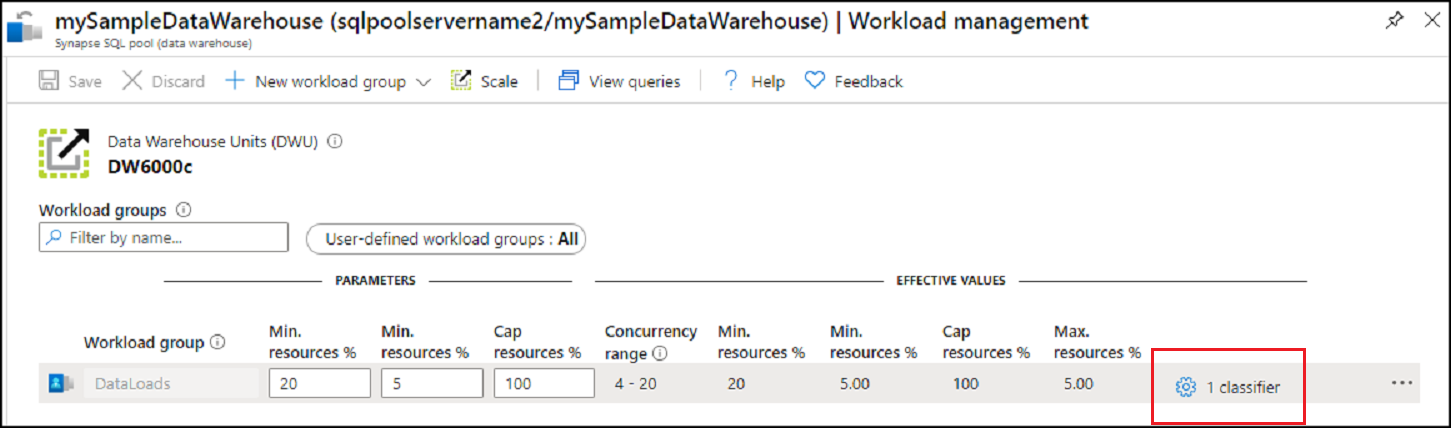
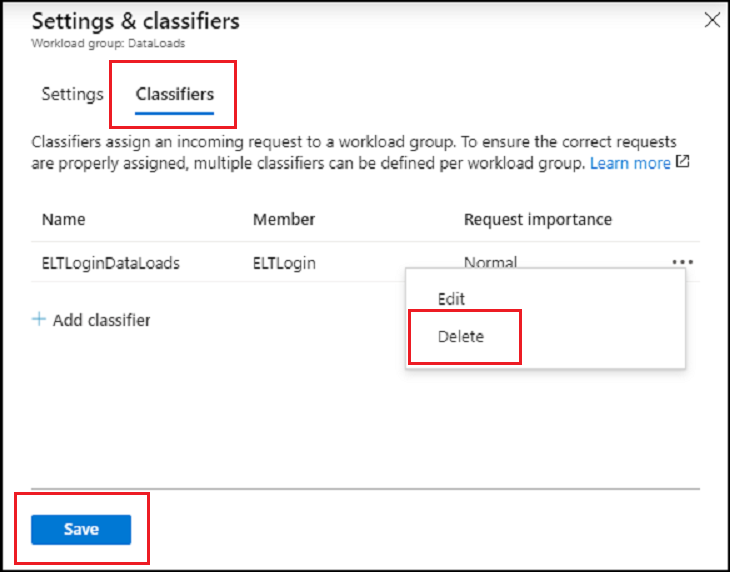
Klicken Sie auf Klassifizierer.
Klicken Sie auf das
...rechts von dem Workload-KlassifiziererELTLoginDataLoads.Klicken Sie auf Löschen.
Klicken Sie auf Speichern.
Ihnen werden Gebühren für Data Warehouse-Einheiten und die in Ihrem dedizierten SQL-Pool gespeicherten Daten in Rechnung gestellt. Diese Compute- und Speicherressourcen werden separat in Rechnung gestellt.
- Falls Sie die Daten im Speicher belassen möchten, können Sie Computeressourcen anhalten, wenn Sie den dedizierten SQL-Pool nicht verwenden. Wenn Sie die Rechenleistung anhalten, werden Ihnen nur die Speichergebühren in Rechnung gestellt. Wenn Sie bereit sind, mit den Daten zu arbeiten, nehmen Sie die Computing-Ressourcen wieder auf.
- Wenn künftig keine Gebühren mehr anfallen sollen, können Sie den dedizierten SQL-Pool löschen.
Führen Sie die folgenden Schritte aus, um Ressourcen zu bereinigen.
Melden Sie sich beim Azure-Portal an, und wählen Sie Ihren dedizierten SQL-Pool aus.

Wählen Sie zum Anhalten von Computeressourcen die Schaltfläche Anhalten. Wenn der dedizierte SQL-Pool angehalten ist, wird die Schaltfläche Starten angezeigt. Um den Rechenprozess fortzusetzen, wählen Sie die Option Starten.
Wenn Sie den dedizierten SQL-Pool entfernen möchten, damit keine Gebühren für Compute- oder Speicherressourcen anfallen, wählen Sie Löschen aus.
Nächste Schritte
Überwachen Sie Ihre Arbeitsauslastung anhand der Überwachungsmetriken im Azure-Portal. Ausführliche Informationen finden Sie unter Verwalten und Überwachen des Workload-Managements.