Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tip
Microsoft Fabric Data Warehouse ist ein relationales Enterprise-Warehouse auf einem Data Lake-Fundament mit zukunftsfähiger Architektur, integrierter KI und neuen Features. Wenn Sie mit Data Warehouse noch nicht vertraut sind, beginnen Sie mit Fabric Data Warehouse. Vorhandene dedizierte SQL-Pool-Workloads können auf Fabric aktualisieren, um neue Funktionen in den Bereichen Data Science, Echtzeitanalyse und Berichterstellung zu nutzen.
Dieses Spickzettel enthält hilfreiche Tipps und bewährte Methoden zum Erstellen dedizierter SQL-Poollösungen (früher SQL DW).
Die folgende Grafik zeigt den Prozess des Entwerfens eines Data Warehouse mit dediziertem SQL-Pool (ehemals SQL DW):
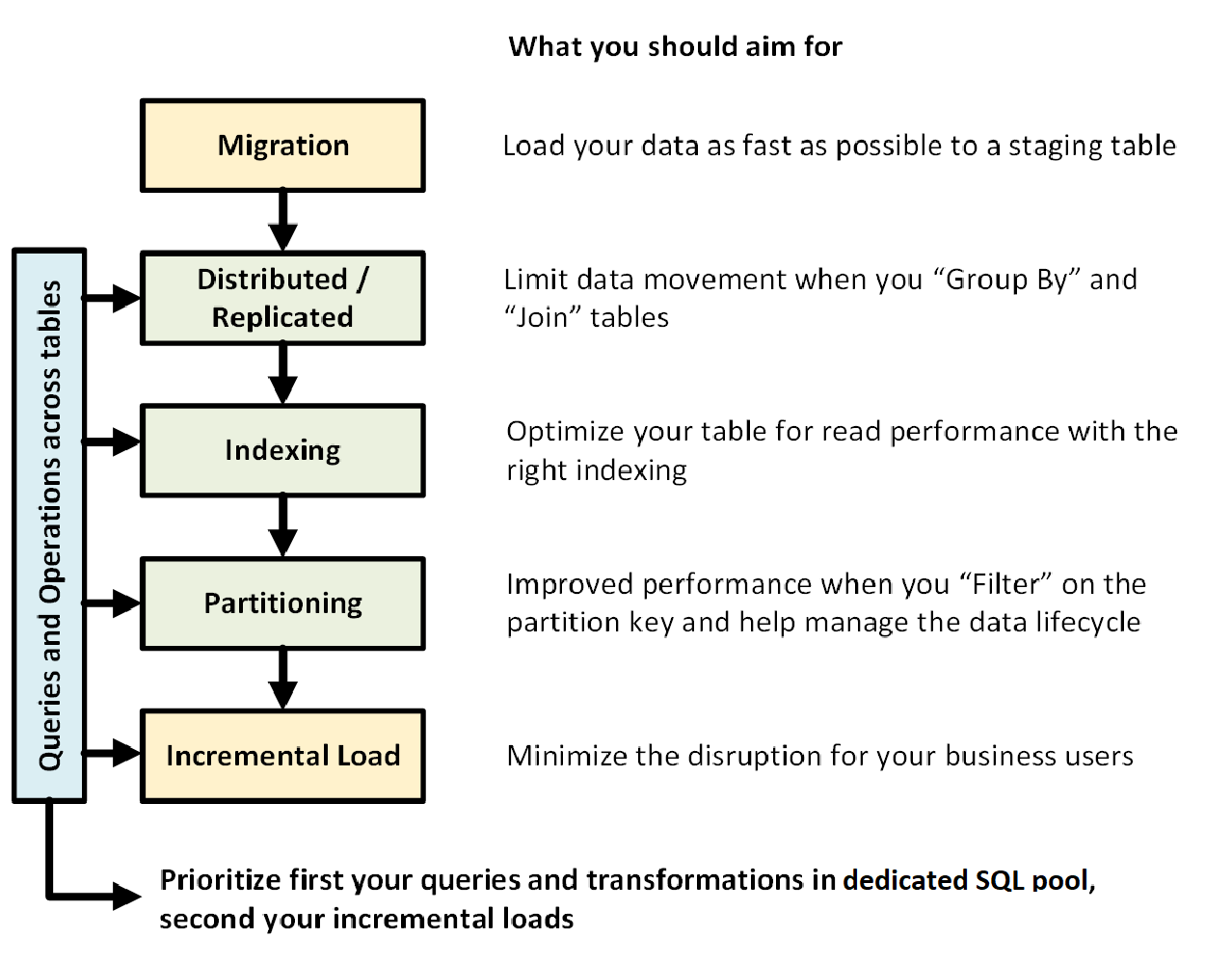
Abfragen und Vorgänge über Tabellen hinweg
Wenn Sie im Voraus wissen, welche primären Vorgänge und Abfragen in Ihrem Data Warehouse ausgeführt werden sollen, können Sie Ihre Data Warehouse-Architektur für diese Vorgänge priorisieren. Diese Abfragen und Vorgänge können Folgendes umfassen:
- Fügen Sie eine oder zwei Faktentabellen mit Dimensionstabellen hinzu, filtern Sie die kombinierte Tabelle, und fügen Sie dann die Ergebnisse an einen Data Mart an.
- Führen Sie große oder kleine Updates an Ihren Vertriebsdaten durch.
- Nur Daten an Ihre Tabellen anfügen.
Wenn Sie die Arten von Vorgängen im Voraus kennen, können Sie den Entwurf Ihrer Tabellen optimieren.
Datenmigration
Laden Sie zunächst Ihre Daten in Azure Data Lake Storage oder Azure Blob Storage. Verwenden Sie als Nächstes die COPY-Anweisung , um Ihre Daten in Stagingtabellen zu laden. Verwenden Sie die folgende Konfiguration:
| Entwurf | Empfehlung |
|---|---|
| Verteilung | Roundrobin |
| Indizierung | Heap |
| Partitionierung | Nichts |
| Ressourcenklasse | largerc oder xlargerc |
Erfahren Sie mehr über die Datenmigration, das Laden von Daten und den Prozess "Extract", "Load" und "Transformieren" (ELT).
Verteilte oder replizierte Tabellen
Verwenden Sie je nach Tabelleneigenschaften die folgenden Strategien:
| Typ | Ideal geeignet für... | Achten Sie darauf, ob... |
|---|---|---|
| Repliziert | * Kleine Dimensionstabellen in einem Sternschema mit weniger als 2 GB Speicher nach komprimierung (~5x-Komprimierung) | * Viele Schreibvorgänge werden auf der Tabelle durchgeführt (z. B. Einfügen, Upsert, Löschen, Aktualisieren) * Sie ändern die Bereitstellung von Data Warehouse Units (DWU) häufig. * Sie verwenden nur 2-3 Spalten, ihre Tabelle enthält jedoch viele Spalten. * Sie indizieren eine replizierte Tabelle |
| RoundRobin (Standard) | * Temporäre/Zwischentabelle * Keine offensichtliche Verknüpfungsschlüssel- oder gute Kandidatenspalte |
* Aufgrund der Verschiebung von Daten ist die Leistung langsam. |
| Hash | * Faktentabellen * Große Dimensionstabellen |
* Der Verteilungsschlüssel kann nicht aktualisiert werden. |
Tipps:
- Beginnen Sie mit Round Robin, aber streben Sie nach einer Hashverteilungsstrategie, um eine massiv parallele Architektur zu nutzen.
- Stellen Sie sicher, dass allgemeine Hashschlüssel dasselbe Datenformat aufweisen.
- Verteilen Sie nicht im Varchar-Format.
- Dimensionstabellen mit einem gemeinsamen Hashschlüssel für eine Faktentabelle mit häufigen Verknüpfungsvorgängen können hashdistribuiert werden.
- Verwenden Sie sys.dm_pdw_nodes_db_partition_stats, um die Daten auf eventuelle Schieflagen zu analysieren.
- Verwenden Sie sys.dm_pdw_request_steps, um Datenbewegungen hinter Abfragen zu analysieren, die Zeitüberwachung zu überwachen und Shufflevorgänge zu kontrollieren. Dies ist hilfreich, um Ihre Verteilungsstrategie zu überprüfen.
Erfahren Sie mehr über replizierte Tabellen und verteilte Tabellen.
Indexieren Sie Ihre Tabelle
Die Indizierung ist hilfreich, um Tabellen schnell zu lesen. Es gibt eine einzigartige Reihe von Technologien, die Sie basierend auf Ihren Anforderungen verwenden können:
| Typ | Ideal geeignet für... | Achten Sie darauf, ob... |
|---|---|---|
| Heap | * Staging/temporäre Tabelle * Kleine Tabellen mit kleinen Suchen |
* Alle Nachschlagevorgänge scannen die vollständige Tabelle |
| Gruppierter Index | * Tabellen mit bis zu 100 Millionen Zeilen * Große Tabellen (mehr als 100 Millionen Zeilen) mit nur 1-2 Spalten, die stark verwendet werden |
* Wird in einer replizierten Tabelle verwendet * Sie haben komplexe Abfragen, die mehrere Join- und Group By-Vorgänge umfassen * Sie nehmen Aktualisierungen für die indizierten Spalten vor: Sie benötigen Arbeitsspeicher. |
| Clustered columnstore index (CCI) (Standard) | * Große Tabellen (mehr als 100 Millionen Zeilen) | * Wird in einer replizierten Tabelle verwendet * Sie machen massive Aktualisierungsvorgänge auf Ihrer Tabelle * Sie überteilen Ihre Tabelle: Zeilengruppen erstrecken sich nicht über verschiedene Verteilungsknoten und Partitionen |
Tipps:
- Oben in einem gruppierten Index möchten Sie möglicherweise einen nicht gruppierten Index zu einer Spalte hinzufügen, die stark zum Filtern verwendet wird.
- Achten Sie darauf, wie Sie den Speicher in einer Tabelle mit CCI verwalten. Wenn Sie Daten laden, soll der Benutzer (oder die Abfrage) von einer großen Ressourcenklasse profitieren. Vermeiden Sie das Kürzen und Erstellen vieler kleiner komprimierter Zeilengruppen.
- In Gen2 werden CCI-Tabellen lokal auf den Computeknoten zwischengespeichert, um die Leistung zu maximieren.
- Bei CCI kann es aufgrund einer schlechten Komprimierung Ihrer Zeilengruppen zu langsamerer Leistung kommen. Falls dies der Fall ist, erstellen Sie Ihre CCI neu, oder organisieren Sie sie neu. Sie möchten mindestens 100.000 Zeilen pro komprimierten Zeilengruppen. Das Ideal ist 1 Million Zeilen in einer Zeilengruppe.
- Basierend auf der inkrementellen Ladehäufigkeit und -größe möchten Sie automatisieren, wenn Sie Ihre Indizes neu organisieren oder neu erstellen. Frühjahrsputz ist immer hilfreich.
- Seien Sie strategisch, wenn Sie eine Zeilengruppe kürzen möchten. Wie groß sind die offenen Zeilengruppen? Wie viele Daten erwarten Sie in den kommenden Tagen?
Weitere Informationen zu Indizes.
Partitionierung
Sie können Ihre Tabelle partitionieren, wenn Sie über eine große Faktentabelle verfügen (mehr als 1 Milliarden Zeilen). In 99 Prozent der Fälle sollte der Partitionsschlüssel auf dem Datum basieren.
Mit Stagingtabellen, die ELT erfordern, können Sie von der Partitionierung profitieren. Es erleichtert die Verwaltung des Datenlebenszyklus. Achten Sie darauf, Ihre Fakten- oder Stagingtabelle nicht übermäßig zu partitionieren, insbesondere bei einem gruppierten Columnstore-Index.
Erfahren Sie mehr über Partitionen.
Inkrementelle Last
Wenn Sie Ihre Daten inkrementell laden möchten, stellen Sie zunächst sicher, dass Sie größere Ressourcenklassen zum Laden Ihrer Daten zuordnen. Dies ist besonders wichtig beim Laden in Tabellen mit gruppierten Spaltenspeicherindizes. Weitere Informationen finden Sie unter Ressourcenklassen .
Wir empfehlen die Verwendung von PolyBase und ADF V2 zum Automatisieren Ihrer ELT-Pipelines in Ihrem Data Warehouse.
Für eine große Anzahl von Aktualisierungen in Ihren historischen Daten sollten Sie eine CTAS verwenden, um die Daten zu schreiben, die Sie in einer Tabelle beibehalten möchten, anstatt INSERT, UPDATE und DELETE zu verwenden.
Verwalten von Statistiken
Es ist wichtig, Statistiken zu aktualisieren, da erhebliche Änderungen an Ihren Daten vorgenommen werden. Sehen Sie sich die Aktualisierungsstatistik an, um festzustellen, ob erhebliche Änderungen aufgetreten sind. Aktualisierte Statistiken optimieren Ihre Abfragepläne. Wenn Sie feststellen, dass es zu lange dauert, um alle Ihre Statistiken beizubehalten, sollten Sie selektiver sein, welche Spalten Statistiken enthalten.
Sie können auch die Häufigkeit der Updates definieren. Sie können beispielsweise Datumsspalten aktualisieren, bei denen neue Werte täglich hinzugefügt werden können. Sie profitieren am meisten davon, indem Sie Statistiken zu Spalten haben, die an Verknüpfungen beteiligt sind, Spalten, die in der WHERE-Klausel verwendet werden, und Spalten, die in GROUP BY gefunden wurden.
Erfahren Sie mehr über Statistiken.
Ressourcenklasse
Ressourcengruppen dienen dazu, Abfragen Speicher zuzuteilen. Wenn Sie mehr Arbeitsspeicher benötigen, um die Abfrage- oder Ladegeschwindigkeit zu verbessern, sollten Sie höhere Ressourcenklassen zuordnen. Auf der anderen Seite wirkt sich die Verwendung größerer Ressourcengruppen auf die Parallelität aus. Sie sollten dies berücksichtigen, bevor Sie alle Benutzer in eine große Ressourcenklasse verschieben.
Wenn Sie feststellen, dass Abfragen zu lange dauern, überprüfen Sie, ob Ihre Benutzer keine großen Ressourcenklassen nutzen. Große Ressourcenklassen verbrauchen viele Parallelitätsslots. Sie können dazu führen, dass andere Abfragen in die Warteschlange gestellt werden.
Schließlich erhält jede Ressourcenklasse bei Verwendung von Gen2 des dedizierten SQL-Pools (ehemals SQL DW) 2,5 Mal mehr Arbeitsspeicher als Gen1.
Erfahren Sie mehr darüber, wie Sie mit Ressourcenklassen und Parallelität arbeiten.
Senken Sie Ihre Kosten
Ein wichtiges Feature von Azure Synapse ist die Möglichkeit, Rechenressourcen zu verwalten. Sie können ihren dedizierten SQL-Pool (früher SQL DW) anhalten, wenn Sie ihn nicht verwenden, wodurch die Abrechnung von Computeressourcen beendet wird. Sie können Ressourcen skalieren, um Ihre Leistungsanforderungen zu erfüllen. Verwenden Sie zum Anhalten das portal Azure oder PowerShell. Verwenden Sie zum Skalieren das portal Azure, PowerShell, T-SQL oder eine REST-API.
Automatische Skalierung jetzt zum gewünschten Zeitpunkt mit Azure Functions:

Optimieren Sie Ihre Architektur für die Leistung
Es wird empfohlen, sql-Datenbank und Azure Analysis Services in einer Hub-and-Spoke-Architektur zu berücksichtigen. Diese Lösung kann die Isolierung von Arbeitslasten zwischen verschiedenen Benutzergruppen bereitstellen und gleichzeitig erweiterte Sicherheitsfeatures aus SQL-Datenbank und Azure Analysis Services verwenden. Dies ist auch eine Möglichkeit, ihren Benutzern eine unbegrenzte Parallelität zu bieten.
Erfahren Sie mehr über typische Architekturen, die den dedizierten SQL-Pool (früher SQL DW) in Azure Synapse Analytics nutzen.
Stellen Sie Ihre Spokes in SQL-Datenbanken aus einem dedizierten SQL-Pool (ehemals SQL DW) bereit.