Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Event Hubs generiert große Mengen an Streamingdaten, die Sie häufig zur Analyse speichern müssen. In diesem Lernprogramm erfahren Sie, wie Sie diese Daten im Parkettformat erfassen – ein spaltenbasiertes Speicherformat, das für Analyseworkloads optimiert ist – mithilfe von Azure Stream Analytics ohne Schreiben von Code.
Verwenden Sie den Stream Analytics No-Code-Editor, um einen Auftrag zu erstellen, der Daten aus Event Hubs direkt an Azure Data Lake Storage Gen2 streamt. Fragen Sie dann die erfassten Parkettdateien mithilfe von Azure Synapse Analytics mit Spark und serverlosem SQL ab.
In diesem Tutorial lernen Sie Folgendes:
- Bereitstellen eines Ereignis-Generators, der Beispielereignisse an einen Event Hub sendet
- Erstellen eines Stream Analytics-Auftrags mithilfe des No-Code-Editors
- Überprüfen von Eingabedaten und Schema
- Konfigurieren Sie Azure Data Lake Storage Gen2, um Daten aus dem Event Hub zu erfassen.
- Ausführen des Stream Analytics-Auftrags
- Verwenden Sie Azure Synapse Analytics, um die Parquet-Dateien abzufragen.
Voraussetzungen
Bevor Sie beginnen, stellen Sie sicher, dass Sie die folgenden Schritte ausführen:
- Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen.
-
Stellen Sie die Ereignis-Generator-App „TollApp“ in Azure bereit. Legen Sie den
intervalParameter auf 1 fest, und verwenden Sie für diesen Schritt eine neue Ressourcengruppe. - Erstellen Sie einen Azure Synapse Analytics-Arbeitsbereich mit einem Data Lake Storage Gen2-Konto.
Verwenden Sie einen codefreien Editor, um einen Stream Analytics-Auftrag zu erstellen.
Suchen Sie die Ressourcengruppe, in der Sie den TollApp-Ereignisgenerator bereitgestellt haben.
Wähen Sie den Azure Event Hubs-Namespace aus. Möglicherweise möchten Sie sie auf einer separaten Registerkarte oder in einem Fenster öffnen.

Wählen Sie auf der Namespaceseite "Event Hubs" unter "Entitäten" im linken Menü die Option "Event Hubs" aus.
Wählen Sie die
entrystream-Instanz aus.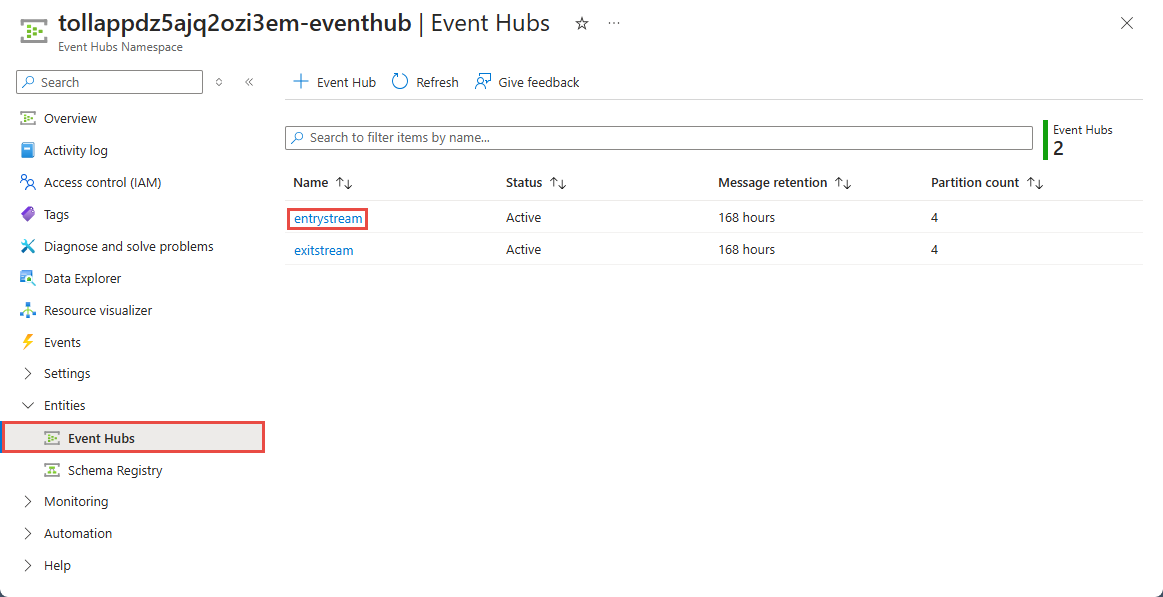
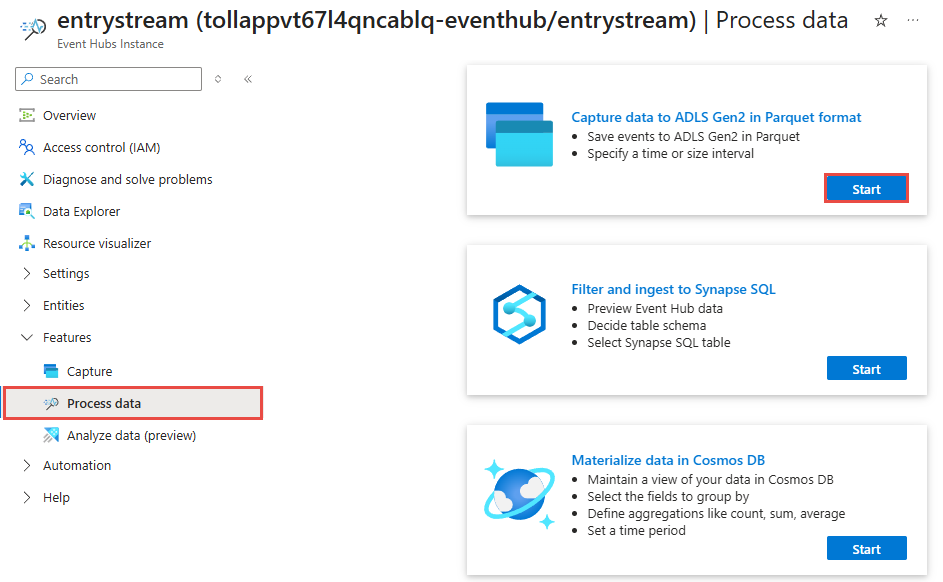
Wählen Sie auf der Seite "Event Hubs-Instanz" im Abschnitt "Features" des linken Menüs "Prozessdaten" aus.
Wählen Sie auf der Kachel Daten im Parquet-Format in ADLS Gen2 erfassen die Option Start aus.
Benennen Sie Ihren Auftrag
parquetcapture, und wählen Sie Erstellen aus.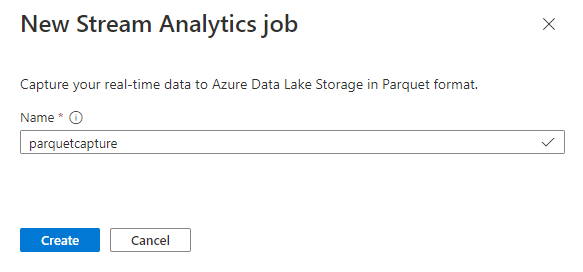
Führen Sie auf der Event Hub-Konfigurationsseite die folgenden Schritte aus:
Wählen Sie für Consumergruppe die Option Vorhandene verwenden aus.
Vergewissern Sie sich, dass die
$DefaultConsumergruppe ausgewählt ist.Vergewissern Sie sich, dass die Serialisierung auf „JSON“ festgelegt ist.
Vergewissern Sie sich, dass Authentifizierungsmethode auf Verbindungszeichenfolge festgelegt ist. Um das Tutorial einfach zu halten, verwenden Sie die Authentifizierung über die Verbindungszeichenfolge. In Produktionsszenarien empfehlen wir die Verwendung von Azure Managed Identity für eine bessere Sicherheit und eine einfachere Verwaltung. Weitere Informationen finden Sie unter Verwenden von verwalteten Identitäten für den Zugriff auf Event Hubs aus einem Azure Stream Analytics-Auftrag.
Vergewissern Sie sich, dass der Name des freigegebenen Zugriffsschlüssels für den Event Hub auf RootManageSharedAccessKey festgelegt ist.
Wählen Sie unten im Fenster die Option Verbinden aus.

Innerhalb weniger Sekunden werden Beispieleingabedaten und das Schema angezeigt. Sie können Felder löschen, Felder umbenennen oder den Datentyp ändern.
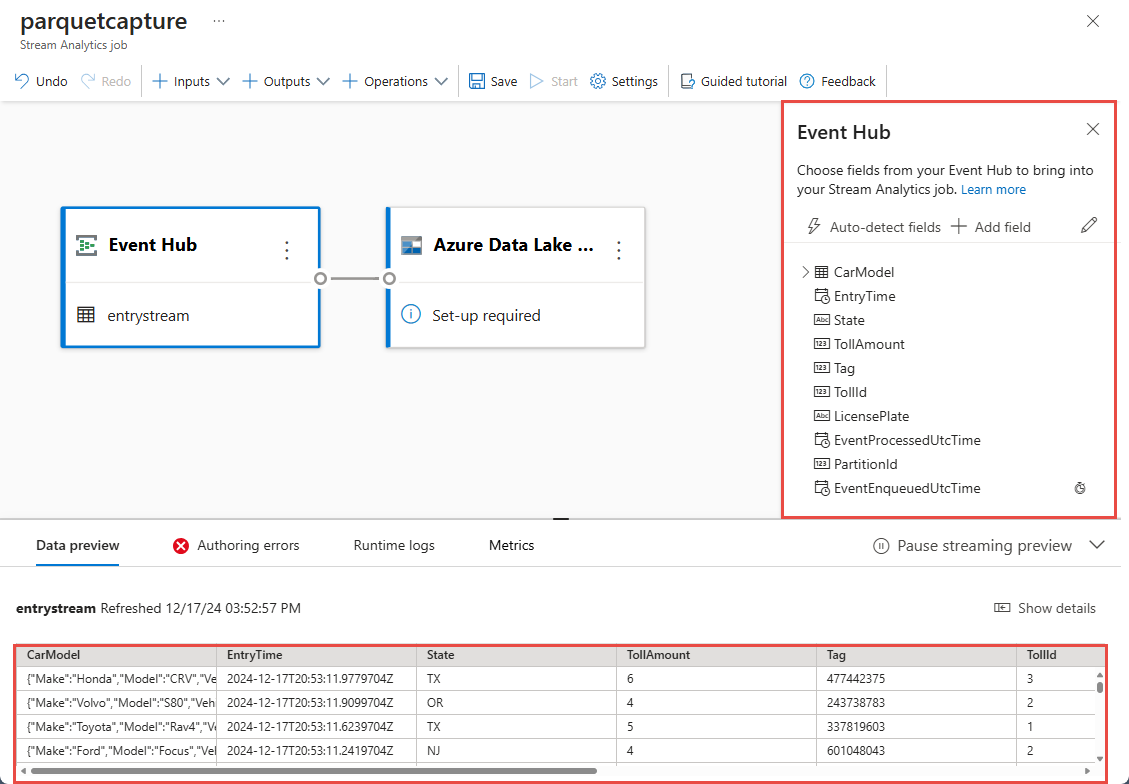
Wählen Sie die Kachel Azure Data Lake Storage Gen2 auf Ihrer Leinwand aus, und konfigurieren Sie sie, indem Sie bestimmte Details angeben.
Abonnement, in dem Sich Ihr Azure Data Lake Gen2-Konto befindet
Der Name des Speicherkontos sollte mit dem Azure Data Lake Storage Gen2-Konto übereinstimmen, das in Verbindung mit Ihrem Azure Synapse Analytics-Arbeitsbereich verwendet wurde, wie im Abschnitt "Voraussetzungen" beschrieben.
Container, in dem die Parquet-Dateien gespeichert werden.
Geben Sie für den Delta-Tabellenpfad einen Namen für die Tabelle an.
Datum- und Uhrzeitmuster als Standard
yyyy-MM-ddundHH.Wählen Sie Verbinden aus.

Wählen Sie im oberen Menüband Speichern aus, um Ihren Auftrag zu speichern, und wählen Sie dann Start aus, um Ihren Auftrag auszuführen. Nachdem der Auftrag gestartet wurde, wählen Sie "X" in der rechten Ecke aus, um die Stream Analytics-Auftragsseite zu schließen.

Es wird eine Liste aller Stream Analytics-Aufträge angezeigt, die mit dem No-Code-Editor erstellt wurden. Innerhalb von zwei Minuten wechselt Ihr Auftrag in den Zustand "Wird ausgeführt". Wählen Sie auf der Seite die Schaltfläche "Aktualisieren" aus, um die Statusänderung von "Erstellt" -> "Startend" -> "Wird ausgeführt" anzuzeigen.










Ausgabe anzeigen in Ihrem Azure Data Lake Storage Gen2 Konto
Suchen Sie das Azure Data Lake Storage Gen2-Konto, das Sie im vorherigen Schritt verwendet haben.
Wählen Sie "Container" unter dem Abschnitt " Datenspeicher " im linken Menü aus.
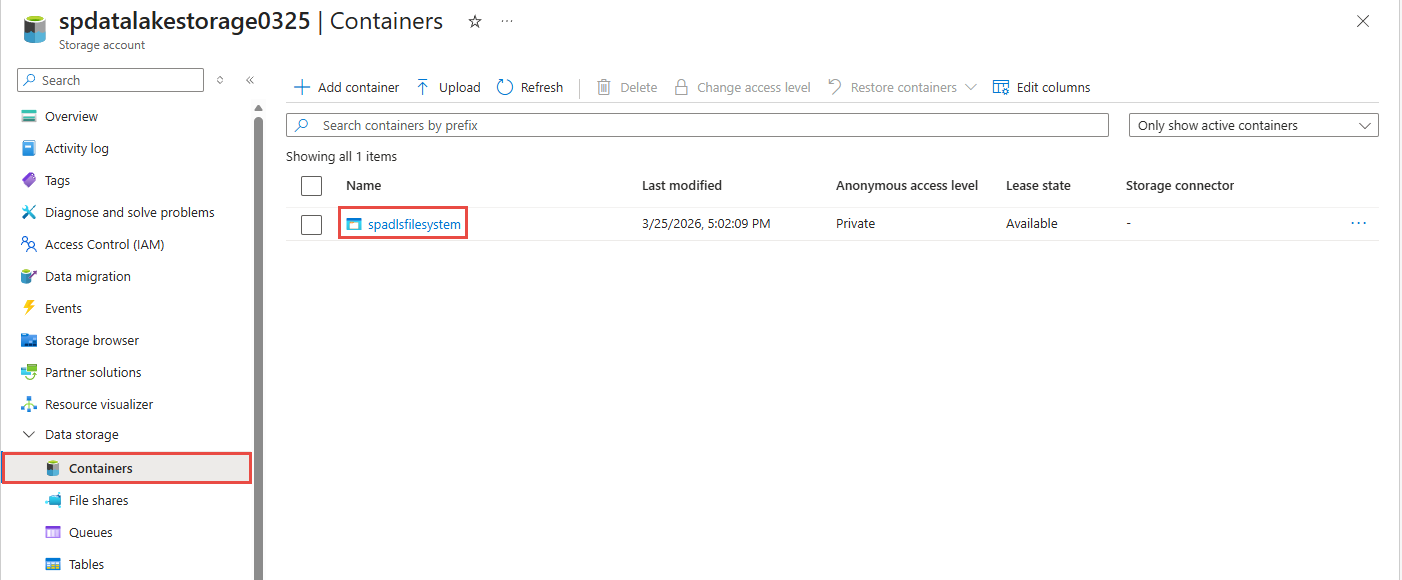
Wählen Sie den Container aus, den Sie im vorherigen Schritt verwendet haben. Sie sehen Parkettdateien, die in dem Ordner erstellt wurden, den Sie zuvor angegeben haben.
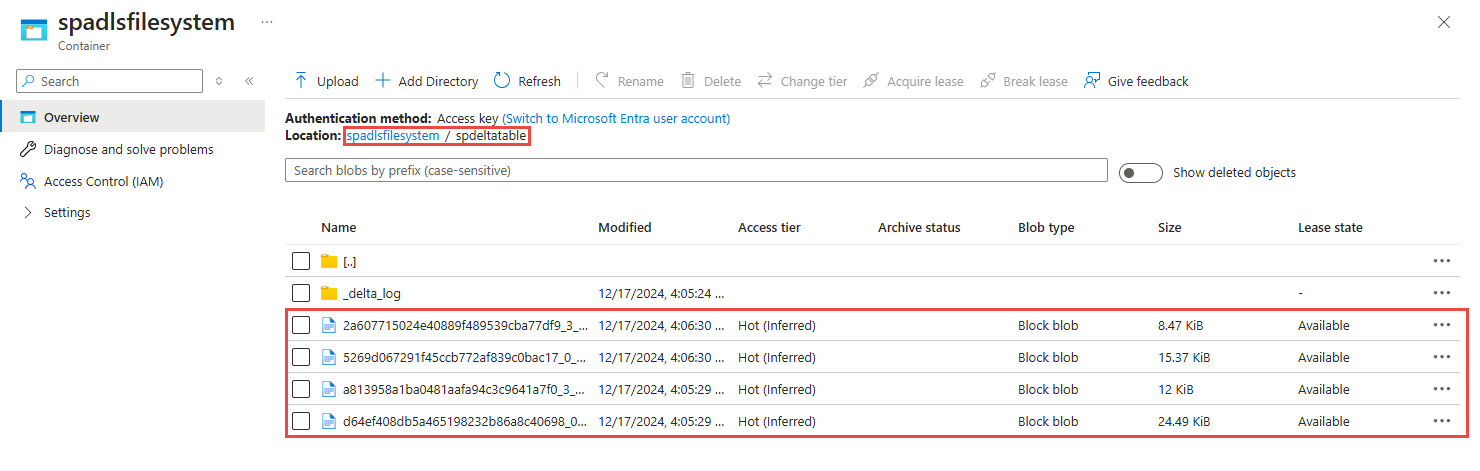


Abfrage von erfassten Daten im Parquet-Format mit Azure Synapse Analytics
Abfragen mit Azure Synapse Spark
Suchen Sie Ihren Azure Synapse Analytics-Arbeitsbereich, und öffnen Sie Synapse Studio.
Erstellen Sie einen serverlosen Apache Spark-Pool in Ihrem Arbeitsbereich, wenn noch nicht vorhanden ist.
Wählen Sie die Kachel "Synapse Studio öffnen" im Abschnitt " Erste Schritte " aus, um synapse Studio in einer neuen Registerkarte oder einem neuen Fenster zu starten.
Navigieren Sie in Synapse Studio zum Hub Entwickeln, und erstellen Sie ein neues Notebook.
Erstellen Sie eine neue Codezelle, und fügen Sie den folgenden Code in diese Zelle ein. Ersetzen Sie container - und Adlsname durch den Namen des Containers und des Azure Data Lake Storage Gen2-Kontos, das im vorherigen Schritt verwendet wird.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()Wählen Sie unter Anfügen an auf der Symbolleiste Ihren Spark-Pool aus der Dropdownliste aus.
Wählen Sie "Alle ausführen" aus, um die Ergebnisse anzuzeigen.


Abfragen mit Azure Synapse SQL (serverlos)
Erstellen Sie im Hub Entwickeln ein neues SQL-Skript.
Fügen Sie das folgende Skript ein, und führen Sie es mithilfe des integrierten serverlosen SQL Endpunkts aus. Ersetzen Sie container - und Adlsname durch den Namen des Containers und des Azure Data Lake Storage Gen2-Kontos, das im vorherigen Schritt verwendet wird.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*.parquet', FORMAT='PARQUET' ) AS [result]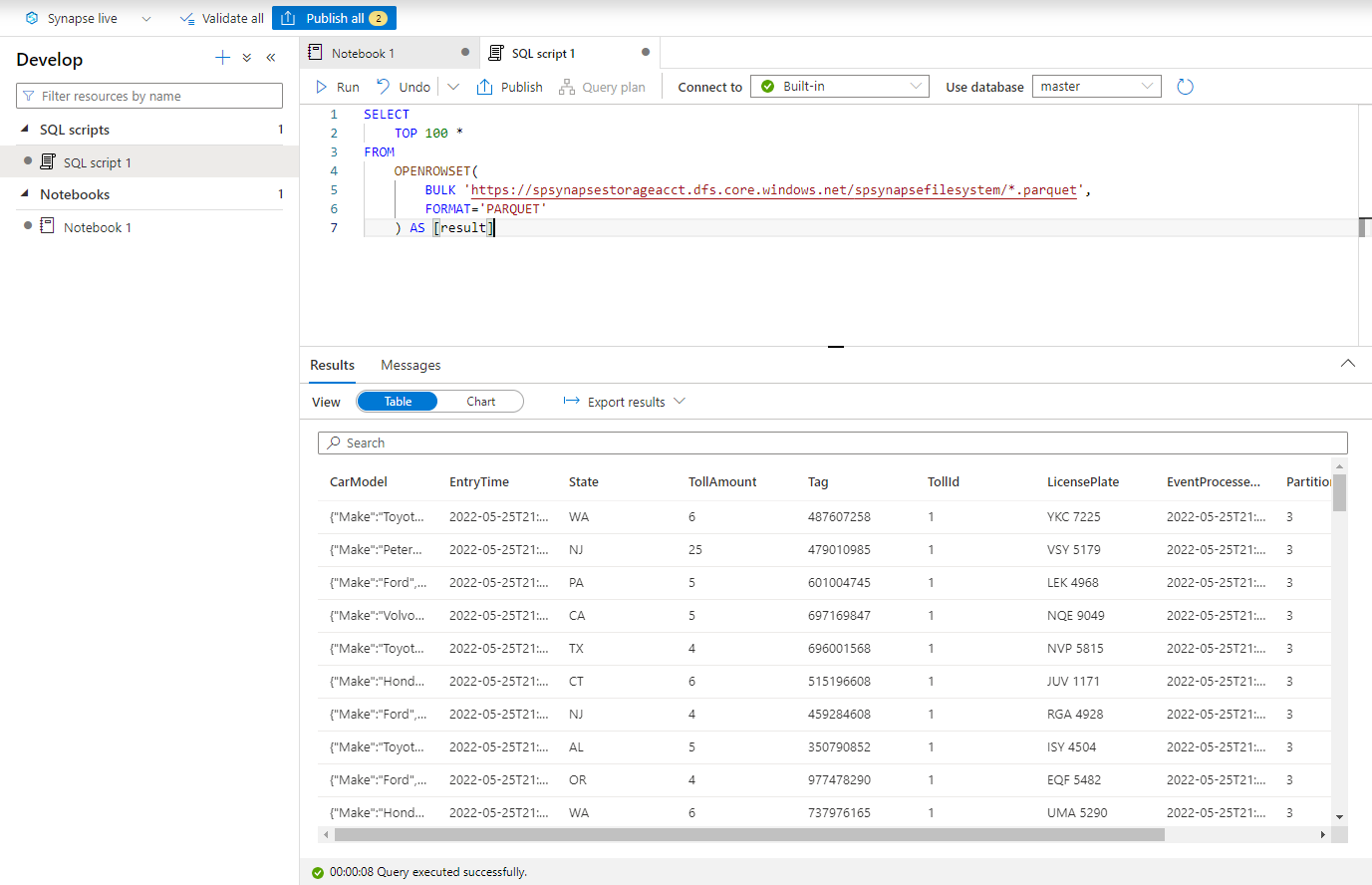

Bereinigen von Ressourcen
- Suchen Sie Ihre Event Hubs-Instanz, und sehen Sie sich die Liste der Stream Analytics-Aufträge im Abschnitt "Prozessdaten " an. Beenden Sie alle laufenden Aufträge.
- Wechseln Sie zur Ressourcengruppe, die Sie beim Bereitstellen des TollApp-Ereignisgenerators verwendet haben.
- Wählen Sie die Option Ressourcengruppe löschen. Geben Sie zum Bestätigen des Löschvorgangs den Namen der Ressourcengruppe ein.
Nächste Schritte
In diesem Lernprogramm haben Sie gelernt, wie Sie einen Stream Analytics-Auftrag erstellen, indem Sie den No-Code-Editor verwenden, um Event Hubs-Datenströme im Parquet-Format zu erfassen. Anschließend haben Sie Azure Synapse Analytics verwendet, um die Parkettdateien mithilfe von Synapse Spark und Synapse SQL abzufragen.