Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Zurzeit wird folgendes angezeigt:![]() Foundry (klassische) Portalversion - Wechseln zur Version für das neue Foundry-Portal
Foundry (klassische) Portalversion - Wechseln zur Version für das neue Foundry-Portal
In diesem Artikel erfahren Sie, wie Sie das Foundry-Portal verwenden, um ein Foundry-Modell in einer Foundry-Ressource für Rückschlüsse bereitzustellen. Gießereimodelle umfassen Modelle wie Azure OpenAI-Modelle, Meta Llama-Modelle und vieles mehr. Nachdem Sie ein Foundry-Modell bereitgestellt haben, können Sie mit dem Modell im Foundry Playground interagieren und es über Code verwenden.
In diesem Artikel wird ein Foundry-Modell von Partnern und Communitys Llama-3.2-90B-Vision-Instruct zur Veranschaulichung verwendet. Modelle von Partnern und Community erfordern, dass Sie Azure Marketplace vor der Bereitstellung abonnieren. Andererseits unterliegen von Azure angebotene Foundry-Modelle, wie z. B. Azure OpenAI in Foundry Models, nicht dieser Anforderung. Weitere Informationen zu Foundry-Modellen, einschließlich der Regionen, in denen sie für die Bereitstellung verfügbar sind, finden Sie unter Foundry Models, die von Azure und Foundry Models von Partnern und Community verkauft werden.
Voraussetzungen
Um diesen Artikel abzuschließen, benötigen Sie Folgendes:
Ein Azure-Abonnement mit einer gültigen Zahlungsmethode. Wenn Sie nicht über ein Azure-Abonnement verfügen, erstellen Sie zunächst ein paid Azure Konto. Wenn Sie GitHub Models verwenden, können Sie upgrade auf Foundry Models und ein Azure-Abonnement im Prozess erstellen.
Die Rolle " Cognitive Services-Mitwirkender" oder gleichwertige Berechtigungen für die Foundry-Ressource zum Erstellen und Verwalten von Bereitstellungen. Weitere Informationen finden Sie unter Azure RBAC-Rollen.
Ein Microsoft Foundry-Projekt. Diese Art von Projekt wird unter einer Foundry-Ressource verwaltet.
Foundry Models von Partnern und der Community benötigen Zugriff auf Azure Marketplace, um Abonnements zu erstellen. Stellen Sie sicher, dass Sie über die erforderlichen Berechtigungen zum Abonnieren von Modellangeboten verfügen. Von Azure verkaufte Foundry-Modelle haben diese Anforderung nicht.
Bereitstellen eines Modells
Stellen Sie ein Modell bereit, indem Sie die folgenden Schritte im Foundry-Portal ausführen:
-
Melden Sie sich bei Microsoft Foundry an. Stellen Sie sicher, dass der Umschalter "Neue Gießerei " deaktiviert ist. Diese Schritte beziehen sich auf Foundry (klassisch).

Wechseln Sie zum Abschnitt "Modellkatalog " im Foundry-Portal.
Wählen Sie ein Modell aus, und überprüfen Sie dessen Details auf der Modellkarte. In diesem Artikel wird zur Veranschaulichung verwendet
Llama-3.2-90B-Vision-Instruct.Wählen Sie "Dieses Modell verwenden" aus.
Für Foundry Models von Partnern und Community müssen Sie Azure Marketplace abonnieren. Diese Anforderung gilt z. B. für
Llama-3.2-90B-Vision-Instruct. Lesen Sie die Nutzungsbedingungen, und wählen Sie "Zustimmen" aus, und gehen Sie fort, um die Bedingungen zu akzeptieren.Hinweis
Für Foundry Models, die von Azure verkauft werden, z. B. das Azure OpenAI-Modell
gpt-4o-mini, abonnieren Sie Azure Marketplace nicht.Konfigurieren Sie die Bereitstellungseinstellungen:
- Standardmäßig verwendet die Bereitstellung den Modellnamen. Sie können diesen Namen vor der Bereitstellung ändern.
- Während der Ableitung wird der Bereitstellungsname im
modelParameter verwendet, um Anforderungen an diese bestimmte Bereitstellung weiterzuleiten.
Tipp
Jedes Modell unterstützt unterschiedliche Bereitstellungstypen und stellt unterschiedliche Datenhaltungs- oder Durchsatzgarantien bereit. Weitere Informationen finden Sie unter Bereitstellungstypen . In diesem Beispiel unterstützt das Modell den Global Standard-Bereitstellungstyp.
Das Foundry-Portal wählt automatisch die dem Projekt zugeordnete Foundry-Ressource als verbundene KI-Ressource aus. Wählen Sie "Anpassen" aus, um die Verbindung bei Bedarf zu ändern. Wenn Sie die Bereitstellung unter dem Serverless-API-Bereitstellungstyp durchführen, muss sich das Projekt und die Ressource in einer der unterstützten Bereitstellungsregionen für das Modell befinden.
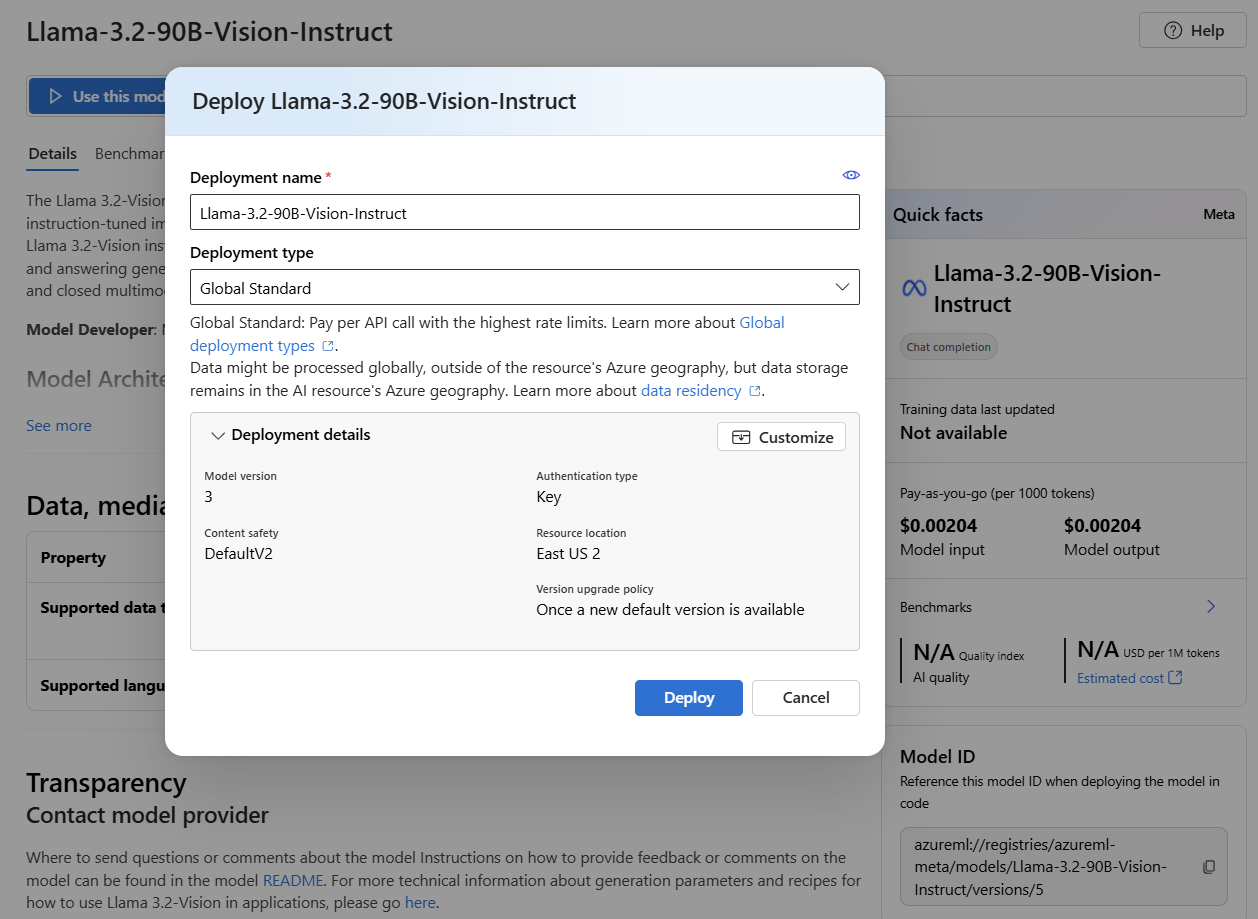
Wählen Sie "Bereitstellen" aus. Die Bereitstellungsdetailseite des Modells wird geöffnet, während die Bereitstellung erstellt wird.
Nach Abschluss der Bereitstellung ist das Modell einsatzbereit. Sie können auch die Foundry Playgrounds verwenden, um das Modell interaktiv zu testen.

Verwalten von Modellen
Sie können die vorhandenen Modellbereitstellungen in der Ressource mithilfe des Foundry-Portals verwalten.
Wechseln Sie zum Abschnitt "Modelle + Endpunkte " im Foundry-Portal.
Das Portal gruppiert und zeigt Modellbereitstellungen pro Ressource an. Wählen Sie die Bereitstellung des Llama-3.2-90B-Vision-Instruct-Modells aus dem Abschnitt für Ihre Foundry-Ressource aus. Diese Aktion öffnet die Bereitstellungsseite des Modells.


Testen Sie die Bereitstellung auf dem Spielplatz
Mithilfe des Playgrounds können Sie mit dem neuen Modell im Foundry-Portal interagieren. Der Playground ist eine webbasierte Schnittstelle, über die Sie in Echtzeit mit dem Modell interagieren können. Verwenden Sie den Playground, um das Modell mit unterschiedlichen Eingabeaufforderungen zu testen und die Antworten des Modells anzuzeigen.
Wählen Sie auf der Bereitstellungsseite des Modells " Im Playground öffnen" aus. Diese Aktion öffnet den Chat-Playground mit dem Namen Ihrer bereits ausgewählten Bereitstellung.

Geben Sie Ihre Eingabeaufforderung ein und sehen Sie sich die Ergebnisse an.
Verwenden Sie "Code anzeigen" , um Details zum programmgesteuerten Zugriff auf die Modellbereitstellung anzuzeigen.

Verwenden Sie das Modell mit Code
Informationen zum Ausführen von Rückschlüssen auf das bereitgestellte Modell finden Sie in den folgenden Beispielen:
Informationen zum Verwenden der Responses-API mit foundry Models, die von Azure verkauft werden, wie z. B. Microsoft AI-, DeepSeek- und Grok-Modelle, finden Sie unter Wie können Sie Textantworten mit Microsoft Foundry Models generieren.
Informationen zur Verwendung der Antwort-API mit OpenAI-Modellen finden Sie unter "Erste Schritte mit der Antwort-API".
Informationen zur Verwendung der Chatabschluss-API mit Modellen, die von Partnern verkauft werden, z. B. das in diesem Artikel bereitgestellte Llama-Modell, finden Sie unter Modellunterstützung für Chatabschlusse.
Regionale Verfügbarkeits- und Kontingentbeschränkungen eines Modells
Bei Foundry Models variiert das Standardkontingent je nach Modell und Region. Bestimmte Modelle sind möglicherweise nur in einigen Regionen verfügbar. Weitere Informationen zu Verfügbarkeits- und Kontingentbeschränkungen finden Sie unter Azure OpenAI in Microsoft Foundry Models Kontingente und Grenzwerte und Microsoft Foundry Models Kontingente und Grenzwerte.
Kontingent für die Bereitstellung und Ausführung von Inferenz für ein Modell
Für Foundry-Modelle verbrauchen das Bereitstellen und Ausführen von Inferenzkontingenz das von Azure Ihrem Abonnement zugewiesene Kontingent. Dies erfolgt auf regionaler und modellbezogener Basis in Einheiten von Tokens pro Minute (TPM). Wenn Sie sich für Foundry registrieren, erhalten Sie das Standardkontingent für die meisten verfügbaren Modelle. Anschließend weisen Sie jeder Bereitstellung TPM zu, während Sie sie erstellen, wodurch das verfügbare Kontingent für dieses Modell reduziert wird. Sie können weiterhin Bereitstellungen erstellen und ihnen TPMs zuweisen, bis Sie Ihr Kontingentlimit erreicht haben.
Wenn Sie ihr Kontingentlimit erreichen, können Sie nur neue Bereitstellungen dieses Modells erstellen, wenn Sie:
- Fordern Sie mehr Kontingent an, indem Sie ein Formular zur Erhöhung des Kontingents übermitteln.
- Passen Sie das zugewiesene Kontingent für andere Modellbereitstellungen im Foundry-Portal an, um Token für neue Bereitstellungen freizugeben.
Weitere Informationen zum Kontingent finden Sie unter Microsoft Foundry Models quotas and limits and Manage Azure OpenAI-Kontingent.
Problembehandlung
| Angelegenheit | Auflösung |
|---|---|
| Kontingent überschritten | Mehr Kontingent anfordern oder TPM aus vorhandenen Bereitstellungen neu zuordnen. |
| Region nicht unterstützt | Überprüfen Sie regionale Verfügbarkeit und stellen Sie in einer unterstützten Region bereit. |
| Marketplace-Abonnementfehler | Vergewissern Sie sich, dass Sie über die Berechtigungen verfügen, um Azure-Marketplace-Angebote zu abonnieren. |
| Der Bereitstellungsstatus zeigt fehlgeschlagen an. | Vergewissern Sie sich, dass das Modell in Ihrer ausgewählten Region verfügbar ist und dass Sie über ein ausreichendes Kontingent verfügen. |