Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die asynchrone Statusnachverfolgung reduziert die Latenz für strukturierte Streaming-Pipelines, indem Abfragen den Fortschritt des Prüfpunkts asynchron aktualisieren und Daten in jedem Mikrobatch verarbeiten können.
Während der Abfrageverarbeitung werden bei Structured Streaming Offsets beibehalten und verwaltet, um den Abfragefortschritt in offsetLog und commitLog in jedem Mikrobatch zu messen. Ohne asynchrone Statusnachverfolgung wirken sich Offsetverwaltungsvorgänge direkt auf die Verarbeitungslatenz aus, da die Datenverarbeitung erst fortgesetzt werden kann, wenn sie abgeschlossen sind.
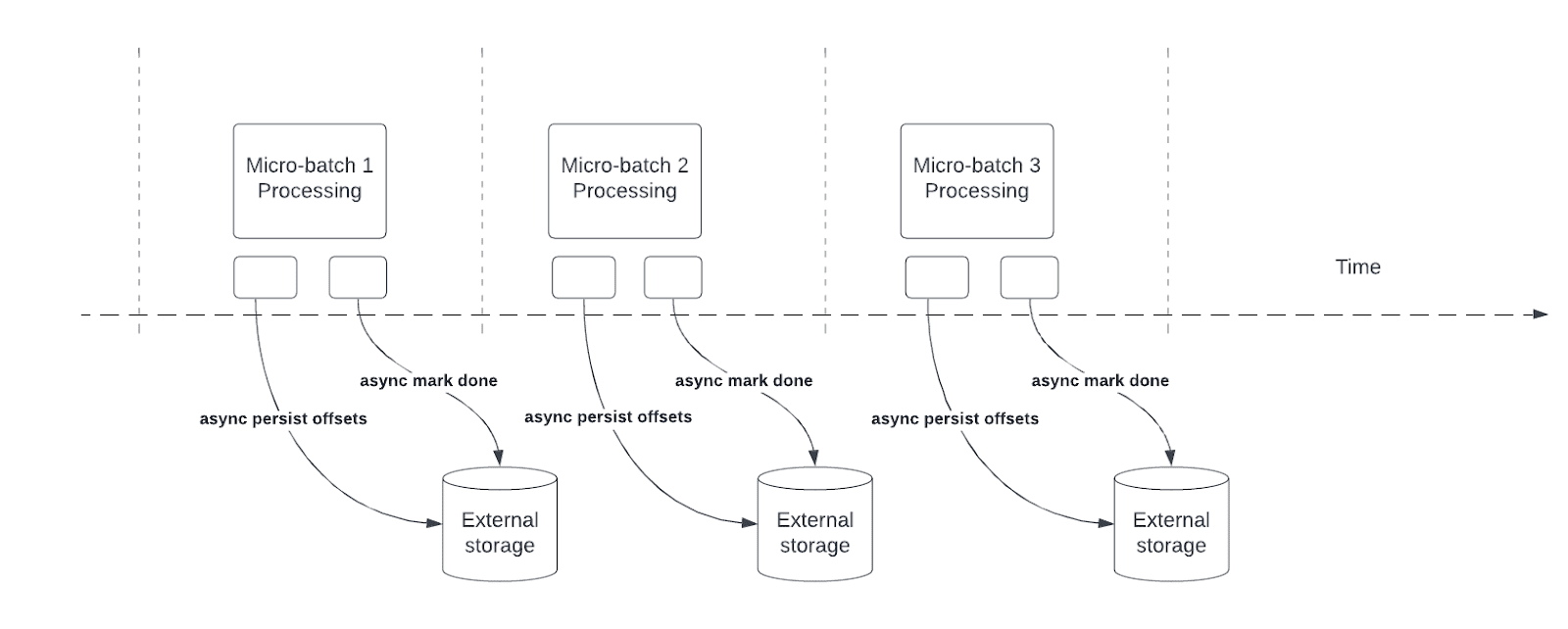
Hinweis
Die asynchrone Statusnachverfolgung ist nicht mit Trigger.once oder Trigger.availableNow Triggern kompatibel. Wenn diese Option aktiviert ist, schlagen strukturierte Streaming-Abfragen mit Trigger.once oder Trigger.availableNow fehl.
Konfigurationsoptionen
| Option | Standard | Description |
|---|---|---|
asyncProgressTrackingEnabled |
false |
Gibt an, ob die asynchrone Statusnachverfolgung aktiviert werden soll. |
asyncProgressTrackingCheckpointIntervalMs |
1000 |
Das Intervall in Millisekunden zwischen Schreibvorgängen für Offsets und Abschluss-Commits. |
Asynchrone Statusverfolgung aktivieren
Um die asynchrone Statusnachverfolgung zu aktivieren, legen Sie asyncProgressTrackingEnabled auf folgendes fest:true
Python
stream = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
)
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
)
Scala
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
Verbesserung des Durchsatzes durch Prüfpunkthäufigkeit
Die Standardprüfpunkthäufigkeit von 1000 Millisekunden weist für die meisten Abfragen einen guten Durchsatz auf. Wenn Offsetverwaltungsvorgänge schneller auftreten als die asynchrone Statusnachverfolgung sie verarbeiten kann, wird ein Backlog von Offsetverwaltungsvorgängen erstellt. Um zu verhindern, dass der Backlog weiter wächst, kann die asynchrone Fortschrittsnachverfolgung die Datenverarbeitung blockieren oder verlangsamen und die erwarteten Latenzvorteile möglicherweise erodieren.
In diesem Szenario empfiehlt Databricks, das Prüfpunktintervall zu erhöhen:
Python
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
)
Scala
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
Hinweis
Die Fehlerwiederherstellungszeit erhöht sich mit der Zeit des Prüfpunktintervalls. Im Falle eines Ausfalls muss eine Pipeline alle Daten seit dem vorherigen erfolgreichen Prüfpunkt erneut verarbeiten. Bevor Sie diese Änderung in der Produktion vornehmen, sollten Sie den Kompromiss zwischen geringerer Latenz während der normalen Verarbeitung im Vergleich zur Wiederherstellungszeit im Falle eines Ausfalls berücksichtigen.
Deaktivieren der asynchronen Statusnachverfolgung
Wenn die asynchrone Statusnachverfolgung aktiviert ist, garantiert der Datenstrom nicht den Prüfpunktstatus für jeden Batch. Sie müssen den Fortschritt sichern, bevor Sie diese Funktion deaktivieren können.
Führen Sie zum Deaktivieren die folgenden Schritte aus:
Verarbeiten Sie mindestens zwei Mikrobatches, wobei
asyncProgressTrackingEnabledauftruegesetzt undasyncProgressTrackingCheckpointIntervalMsauf0gesetzt ist.Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start()Beenden Sie die Abfrage:
Python
query.stop()Scala
query.stop()Deaktivieren Sie die asynchrone Statusnachverfolgung, und starten Sie die Abfrage neu:
Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start()
Wenn Sie die asynchrone Statusnachverfolgung deaktivieren, ohne die vorstehenden Schritte auszuführen, tritt möglicherweise der folgende Fehler auf:
java.lang.IllegalStateException: batch x doesn't exist
In den Treiberprotokollen wird möglicherweise der folgende Fehler angezeigt:
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
Einschränkungen
- Bei Kafka-Senken unterstützt die asynchrone Fortschrittsverfolgung nur zustandslose Pipelines.
- Die asynchrone Statusnachverfolgung garantiert nicht eine genau einmalige End-to-End-Verarbeitung, da Offsetbereiche einer Charge bei Fehlern geändert werden können. Einige Senken, wie z. B. Kafka, bieten nie genau einmal Garantien.