Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Auslastungstests finden die maximalen Abfragen pro Sekunde (QPS), die Ihr Databricks Apps-Agent erhalten kann, bevor die Leistung beeinträchtigt wird. Auf dieser Seite wird gezeigt, wie Sie die folgenden Aktionen ausführen:
- Stellen Sie eine simulierte Version Ihres Agents bereit, um den Infrastrukturdurchsatz von der LLM-Latenz zu isolieren.
- Führen Sie einen Rampe-zu-Sättigungslast-Test mit Locust aus.
- Analysieren Sie Ergebnisse mit einem interaktiven Dashboard.
Sie können den KI-unterstützten Weg mit einer Claude Code-Fähigkeit befolgen oder jeden Schritt manuell einrichten.
Anforderungen
- Ein Azure Databricks Arbeitsbereich mit aktivierten Databricks-Apps.
- Eine Agent-App, die für Databricks-Apps mit dem OpenAI Agents SDK, LangGraph oder einem benutzerdefinierten Framework bereitgestellt wird (oder bereit für die Bereitstellung ist). Weitere Informationen finden Sie unter Erstellen eines KI-Agenten und Bereitstellung in Databricks-Apps.
- Die Databricks CLI wurde installiert und authentifiziert. Siehe Installieren oder Aktualisieren der Databricks CLI.
- Python 3.10+ mit
uvPaket-Manager. - (Für den KI-unterstützten Pfad) Claude Code installiert.
- (Für Auslastungstests länger als ~1 Stunde) Ein Dienstprinzipal mit M2M OAuth-Anmeldeinformationen (
client_idundclient_secret). Siehe Autorisieren des Dienstprinzipalzugriffs auf Azure Databricks mit OAuth.- Bei kurzen Auslastungstests (weniger als ~1 Stunde) funktionieren die OAuth-Anmeldeinformationen Ihres vorhandenen Benutzers (U2M)
databricks auth logineinwandfrei. Verwenden Sie für längere Tests M2M OAuth mit einem Dienstprinzipal, da U2M-Token bei langen Testdurchläufen ablaufen und Fehler während des Tests verursachen können. Zum Erstellen eines Dienstprinzipals ist Administratorzugriff auf den Arbeitsbereich erforderlich.
- Bei kurzen Auslastungstests (weniger als ~1 Stunde) funktionieren die OAuth-Anmeldeinformationen Ihres vorhandenen Benutzers (U2M)
KI-unterstützte Einrichtung (empfohlen)
Wenn Sie Claude Code verwenden, automatisiert die /load-testing Fähigkeit den Workflow. Er liest Ihren Agent-Code, generiert ein Modell, erstellt Ladetestskripts und führt Sie durch die Bereitstellung.
Tipp
Sagen Sie Claude Code, dass er es für Sie tun soll:
Clone https://github.com/databricks/app-templates and run the /load-testing skill against the {your-template} template.
Oder führen Sie die folgenden Schritte aus.
Schritt 1: Klonen einer Agentvorlage
Die /load-testing Fähigkeit ist im Repository " databricks/app-templates " enthalten, sowohl als Qualifikation auf oberster Ebene agent-load-testing als auch vorab in jede einzelne Agent-Vorlage synchronisiert. Wenn Sie bereits über ein Projekt von app-templates verfügen, besitzen Sie bereits die Fähigkeit.
Klonen Sie das Repository, und wechseln Sie in das Vorlagenverzeichnis für den Agenten, den Sie einem Lasttest unterziehen möchten.
git clone https://github.com/databricks/app-templates.git
cd app-templates/{your-template}
Schritt 2: Führen Sie die Load-Testing-Funktion aus
Führen Sie in Claude Code Folgendes aus:
/load-testing
Die Fähigkeit führt Sie interaktiv durch die folgenden Schritte. Sie können die Mocking überspringen, um Ihren echten Agent zu testen, oder die Bereitstellung überspringen, wenn Ihre Apps bereits ausgeführt werden.
- Sammeln von Parametern: Fragt nach Ihrem Bereitstellungsstatus, Rechengrößen, Worker-Konfigurationen und OAuth-Anmeldeinformationen.
-
Erstellen von Ladetestskripts:
locustfile.py,run_load_test.pyunddashboard_template.py, die auf Ihr Projekt zugeschnitten sind. - Mocking your LLM: Erstellt einen speziell auf Ihr SDK (OpenAI Agents SDK, LangGraph oder benutzerdefiniert) abgestimmten Mock-Client, der echte LLM-Anrufe durch konfigurierbare Streaming-Verzögerungen ersetzt.
- Bereitstellen von Test-Apps: Führt Sie durch die Bereitstellung mehrerer App-Konfigurationen mit unterschiedlichen Berechnungsgrößen und Arbeitszahlen.
- Ausführen von Tests: Führt den Auslastungstest mit der M2M OAuth-Authentifizierung und einem Ramp-up bis zur Sättigung aus.
- Generieren von Ergebnissen: Erzeugt ein interaktives HTML-Dashboard mit QPS, Latenz und Fehlermetriken.
Manuelle Einrichtung
Führen Sie die folgenden Schritte aus, um Ladetests ohne KI-Unterstützung einzurichten und auszuführen.
Schritt 1: Simuliert die LLM-Anrufe Ihres Agents (optional)
Überspringen Sie diesen Schritt, wenn Sie durchgängige Ergebnisse wünschen, die eine echte LLM-Latenz enthalten. Um den Durchsatz der Databricks-Apps-Infrastruktur in Isolation zu messen, simulieren Sie das LLM so, dass die Latenz pro Anforderung (in der Regel 1-30 Sekunden) nicht zum Engpass wird.
Ein Mock liefert vorgefertigte Antworten mit einer konfigurierbaren Streamingverzögerung und behält dabei die vollständige Anforderungs-/Antwortpipeline (SSE Streaming, Tool Dispatch, SDK Runner) bei, wobei nur die LLM ausgetauscht wird. Dadurch wird das maximale QPS angezeigt, das die Databricks-Apps-Plattform liefern kann, und es werden die Kosten für API-Tokens des Foundation Models während der Lasttests vermieden.
Die simulierte Zeitsteuerung wird durch zwei Umgebungsvariablen gesteuert:
| Variable | Vorgabe | Description |
|---|---|---|
MOCK_CHUNK_DELAY_MS |
10 |
Verzögerung in Millisekunden zwischen gestreamten Textblöcken |
MOCK_CHUNK_COUNT |
80 |
Anzahl der Textblöcke pro Antwort |
Bei den Standardwerten dauert jede Simuliertantwort ungefähr 800 ms (10 ms x 80 Blöcke), deutlich schneller als eine echte LLM-Antwort (3-15 Sekunden). Durchsatznummern spiegeln dann die Plattform und nicht das Modell wider.
Erstellen Sie einen simulierten Client, der den echten LLM-Client ersetzt. Der Rest Des Agent-Codes bleibt unverändert, und der Ansatz hängt von Ihrem SDK ab. Informationen zu OpenAI finden Sie in der mock_openai_client.py Referenzimplementierung in databricks/app-templates. Das gleiche Muster passt sich an andere SDKs an.
OpenAI Agents SDK
Erstellen Sie eine MockAsyncOpenAI-Klasse, die chat.completions.create() mithilfe von Streaming implementiert. Es werden Teilabschnitte von Toolaufrufen sofort zurückgegeben (wobei die Entscheidung des LLM zum Aufrufen eines Tools simuliert wird) und Textantwortabschnitte mit einer konfigurierbaren Verzögerung von MOCK_CHUNK_DELAY_MS und MOCK_CHUNK_COUNT Umgebungsvariablen.
Integrieren Sie es in Ihren Agenten.
from agent_server.mock_openai_client import MockAsyncOpenAI
from agents import set_default_openai_client, set_default_openai_api
set_default_openai_client(MockAsyncOpenAI())
set_default_openai_api("chat_completions")
Der Rest Des Agent-Codes (Handler, Tools, Streaminglogik) bleibt unverändert.
LangGraph
Ersetzen Sie das ChatDatabricks Modell durch ein Mock, das vordefinierte AIMessage Objekte zurückgibt.
# Before:
# model = ChatDatabricks(endpoint="databricks-claude-sonnet-4")
# After:
from agent_server.mock_llm import MockChatModel
model = MockChatModel()
Das Mock-Objekt sollte bei der ersten Ausführung Objekte mit Funktionsaufrufen und bei nachfolgenden Ausführungen Textinhalte mit konfigurierbaren Streamingverzögerungen zurückgebenAIMessage.
Benutzerdefinierte Agents
Schließen Sie alle externen API-Aufrufe ihres Agents (LLM, Vektorsuche, Tool-APIs) mit simulierten Implementierungen um, die realistische Antwort-Shapes mit konfigurierbaren Verzögerungen zurückgeben.
Schritt 2: Einrichten von Ladetestskripts
Erstellen Sie ein load-test-scripts/ Verzeichnis in Ihrem Projekt. Das Lastentestframework besteht aus drei Skripts, die framework-unabhängig sind und mit beliebigen Databricks Apps-Agenten arbeiten.
<project-root>/
agent_server/ # Your existing agent code
load-test-scripts/ # Load testing scripts (create this)
run_load_test.py # CLI orchestrator
locustfile.py # Locust test with SSE streaming + TTFT tracking
dashboard_template.py # Interactive HTML dashboard generator
load-test-runs/ # Results (auto-created per run)
<run-name>/
dashboard.html # Interactive dashboard
test_config.json # Test parameters for reproducibility
<label>/ # Per-config Locust CSV output
Das Framework enthält die folgenden Dateien:
-
locustfile.py: Ein Locust-Auslastungstest, derPOST /invocationsAnforderungen mitstream: truesendet, analysiert SSE-Datenströme, verfolgt die Zeit bis zum ersten Token (TTFT) als benutzerdefinierte Metrik, verwendet den M2M OAuth-Tokenaustausch mit automatischer Aktualisierung und implementiert eineStepRampShape, die Benutzer vonstep_sizeaufmax_usershochfährt und hält jede Stufe fürstep_durationSekunden. -
run_load_test.py: Ein CLI-Orchestrator, der jede App-URL sequenziell mit isolierten Metriken pro Konfiguration testet. Es behandelt die Aktualisierung des OAuth-Tokens, führt eine Integritätsprüfung und ein Aufwärmen vor jedem Test aus und speichert Ergebnisse inload-test-runs/<run-name>/<label>/. -
dashboard_template.py: Generiert ein eigenständiges HTML-Dashboard mithilfe von Chart.js mit KPI-Karten, Balkendiagrammen (QPS, Latenz, TTFT nach Konfiguration), Diagrammen der QPS-Rampenentwicklung und einer vollständigen Ergebnistabelle. Kann eigenständig ausgeführt werden:uv run dashboard_template.py ../load-test-runs/<run-name>/.
Abhängigkeiten installieren
Die Lasttestscripte verwenden ihre eigenen pyproject.toml innerhalb von load-test-scripts/, um die Abhängigkeiten der Produktionsumgebung Ihres Agents nicht zu belasten. Erstellen Sie load-test-scripts/pyproject.toml:
[project]
name = "load-test-scripts"
version = "0.1.0"
requires-python = ">=3.10"
dependencies = [
"locust>=2.32,<2.40",
"urllib3<2.3",
"requests",
]
Note
Anheften von locust an <2.40. Neuere Versionen (>=2.43) haben ein bekanntes Problem (RecursionError), das lange Ladungstests unterbricht.
Installieren aus dem load-test-scripts/ Verzeichnis:
cd load-test-scripts/
uv sync
Schritt 3: Bereitstellen von Test-Apps mit unterschiedlichen Konfigurationen
Stellen Sie mehrere Databricks-Apps mit unterschiedlichen Berechnungsgrößen und Arbeitsmitarbeitern bereit, um die optimale Konfiguration für Ihre Workload zu finden.
Empfohlene Testmatrix
Die folgenden Konfigurationen befassen sich mit dem optimalen Bereich, der aus vorherigen Tests identifiziert wurde. Wenn Sie eine breitere Abdeckung benötigen, fügen Sie eine Konfiguration auf beiden Seiten hinzu (z. B medium-w1 . oder large-w12), aber die sechs unten sind in der Regel ausreichend.
| Berechnungsgröße | Arbeitskräfte | Vorgeschlagener App-Name |
|---|---|---|
| Medium | 2 | <your-app>-medium-w2 |
| Medium | 3 | <your-app>-medium-w3 |
| Medium | 4 | <your-app>-medium-w4 |
| Groß | 6 | <your-app>-large-w6 |
| Groß | 8 | <your-app>-large-w8 |
| Groß | 10 | <your-app>-large-w10 |
Konfigurieren der Computegröße
Verwenden Sie die Databricks CLI, um die Berechnungsgröße beim Erstellen oder Aktualisieren einer App festzulegen:
# Create a new app with Medium compute
databricks apps create <app-name> --compute-size MEDIUM
# Update an existing app to Large compute
databricks apps update <app-name> --compute-size LARGE
Konfigurieren der Arbeitsanzahl mit deklarativen Automatisierungspaketen
start-server (via AgentServer.run()) akzeptiert eine --workers Kennzeichnung direkt. Übergeben Sie die Anzahl der Worker im command-Array mithilfe einer DAB-Variablen.
variables:
app_name:
default: 'my-agent-medium-w2'
workers:
default: '2'
resources:
apps:
load_test_app:
name: ${var.app_name}
source_code_path: .
config:
command: ['uv', 'run', 'start-server', '--workers', '${var.workers}']
env:
- name: MOCK_CHUNK_DELAY_MS
value: '10'
- name: MOCK_CHUNK_COUNT
value: '80'
targets:
medium-w2:
default: true
variables:
app_name: 'my-agent-medium-w2'
workers: '2'
large-w8:
variables:
app_name: 'my-agent-large-w8'
workers: '8'
Bereitstellen und Überprüfen
Stellen Sie jedes Ziel mit der Databricks CLI bereit:
databricks bundle deploy --target medium-w2
databricks bundle run load_test_app --target medium-w2
Überprüfen Sie, ob Apps aktiv sind, bevor Sie Ladetests ausführen:
databricks apps get <app-name> --output json | jq '{app_status, compute_status, url}'
Note
Warten Sie, bis alle Apps den Status erreicht ACTIVE haben, bevor Sie fortfahren. Apps, die sich noch in der Startphase befinden, führen zu irreführenden Ergebnissen.
Schritt 4: Ausführen von Auslastungstests
Authentifizierung einrichten
Wählen Sie Ihre Authentifizierung abhängig davon, wie lange sie laufen soll.
-
Kurze Tests (weniger als ~1 Stunde):Verwenden Sie Ihre vorhandenen Benutzeranmeldeinformationen von
databricks auth login. Kein zusätzlicher Setup erforderlich. - Lange Tests (mehr als ~1 Stunde, z. B. über Nachtläufe): Verwenden Sie M2M OAuth mit einem Dienstprinzipal. U2M-Token verfallen und unterbrechen Ihren Test während der Ausführung. Zum Erstellen eines Dienstprinzipals ist der Administratorzugriff auf den Arbeitsbereich erforderlich.
Exportieren Sie für M2M OAuth die Anmeldeinformationen für den Dienstprinzipal, bevor Sie Tests ausführen.
export DATABRICKS_HOST=https://your-workspace.cloud.databricks.com
export DATABRICKS_CLIENT_ID=<your-client-id>
export DATABRICKS_CLIENT_SECRET=<your-client-secret>
Parameterreferenz
| Parameter | Erforderlich | Vorgabe | Description |
|---|---|---|---|
--app-url |
Yes | — | App-URL(n) zum Testen (wiederholbar) |
--client-id |
Für lange Tests |
DATABRICKS_CLIENT_ID Env |
Dienst-Principal-Client-ID (M2M OAuth) |
--client-secret |
Für lange Tests |
DATABRICKS_CLIENT_SECRET Env |
Geheimer Clientschlüssel des Dienstprinzipals (M2M OAuth) |
--label |
No | Automatisch von URL abgeleitet | Menschenlesbare Beschriftung je App (wiederholbar) |
--compute-size |
No | Automatisch erkannt oder medium |
Berechne Größen-Tag pro App: medium, large (wiederholbar) |
--max-users |
No | 300 |
Maximale Anzahl gleichzeitig simulierter Benutzer |
--step-size |
No | 20 |
Benutzer, die pro Rampenschritt hinzugefügt wurden |
--step-duration |
No | 30 |
Sekunden pro Rampenschritt |
--spawn-rate |
No | 20 |
Benutzer-Spawnrate (Benutzer/Sek.) |
--run-name |
No | <timestamp> |
Name für diese Ausführung – Ergebnisse werden in load-test-runs/<run-name>/ gespeichert |
--dashboard |
No | Aus | Generieren eines interaktiven HTML-Dashboards nach Abschluss der Tests |
Beispielbefehle
Schneller Einzel-App-Test (kurze Ausführung – verwendet Ihre databricks auth login Sitzung):
cd load-test-scripts/
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--dashboard --run-name quick-test
Vollständige Matrix für die empfohlenen 6 Konfigurationen (langer Betrieb – Weitergabe von M2M-Anmeldeinformationen). Übergebe --compute-size Flags in der gleichen Reihenfolge wie --app-url:
uv run run_load_test.py \
--app-url https://my-app-medium-w2.aws.databricksapps.com \
--app-url https://my-app-medium-w3.aws.databricksapps.com \
--app-url https://my-app-medium-w4.aws.databricksapps.com \
--app-url https://my-app-large-w6.aws.databricksapps.com \
--app-url https://my-app-large-w8.aws.databricksapps.com \
--app-url https://my-app-large-w10.aws.databricksapps.com \
--compute-size medium --compute-size medium --compute-size medium \
--compute-size large --compute-size large --compute-size large \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--dashboard --run-name overnight-sweep
Mehrere Läufe für statistische Konsistenz:
for RUN in r1 r2 r3 r4 r5; do
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--max-users 1000 --step-size 20 --step-duration 10 \
--run-name my_test_${RUN} --dashboard || break
done
Was während eines Laufs geschieht
-
Integritätsprüfung: Überprüft, ob die App korrekt streamt (empfängt
[DONE]). - Warmup: Sendet sequenzielle Anforderungen, um die App aufzuwärmen.
-
Ramp-to-Saturation: Erhöht alle
step_durationSekunden die Anzahl der gleichzeitigen Benutzer. - Sättigungserkennung: Wenn QPS-Plateaus trotz des Hinzufügens weiterer Benutzer auf die Durchsatzgrenze stoßen.
Geschätzte Dauer
Jede App, die getestet wird, wird über eine eigene Rampe ausgeführt, sodass die Gesamtlaufzeit mit der Anzahl der Konfigurationen in Ihrer Matrix skaliert wird. Verwenden Sie die folgende Formel, um das Ausführungsfenster einzuplanen.
Dauer pro App: (max_users / step_size) * step_duration Sekunden.
Standardmäßig (--max-users 300 --step-size 20 --step-duration 30):
- 15 Schritte x 30 Sekunden = ca. 7,5 Minuten pro App
- Für die empfohlene sechsteilige Konfigurationsmatrix: ca. 45 Minuten pro Durchlauf
Schritt 5: Anzeigen und Interpretieren von Ergebnissen
Öffnen Sie das Dashboard:
open load-test-runs/<run-name>/dashboard.html(Optional) Generieren Sie das Dashboard aus vorhandenen Daten, z. B. nach dem Aktualisieren der Vorlage:
cd load-test-scripts/ uv run dashboard_template.py ../load-test-runs/<run-name>/
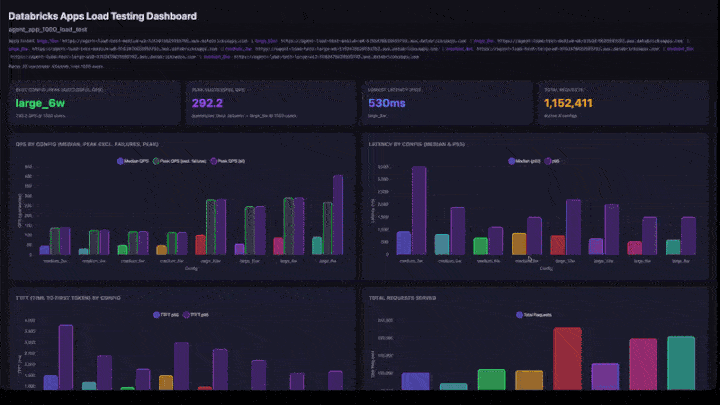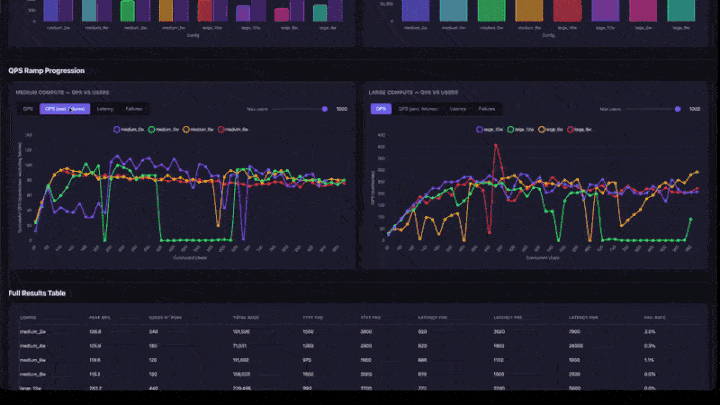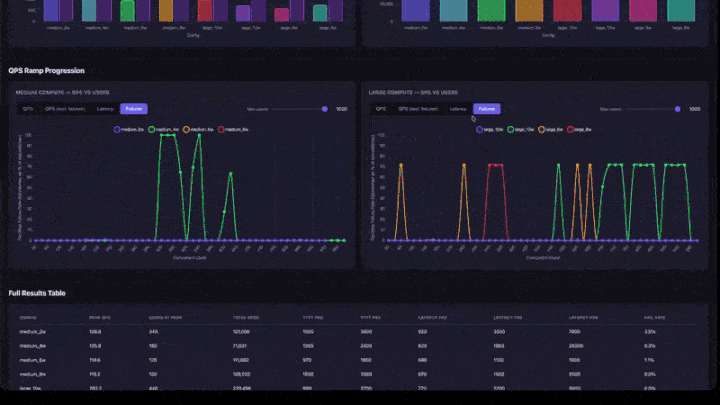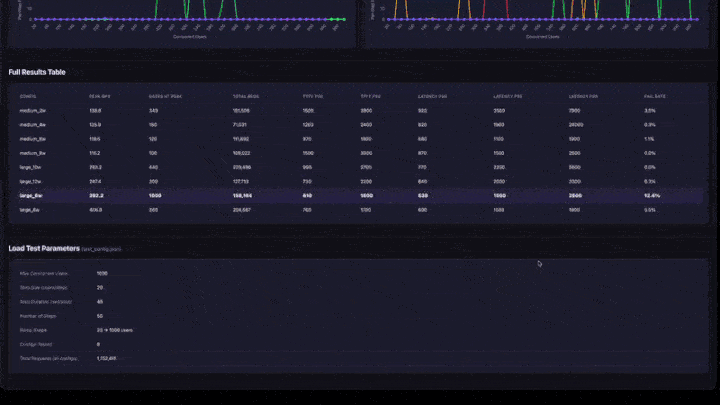
Abschnitte des Dashboards
Das interaktive Dashboard umfasst:
- KPI-Karten: Beste Konfiguration (nach höchstem erfolgreichen QPS), Gesamthöchstwert der QPS, niedrigste Latenz und insgesamt bearbeitete Anfragen.
- QPS nach Konfiguration: gruppiertes Balkendiagramm mit medianen QPS, Spitzen-QPS ohne Fehler und Spitzen-QPS nebeneinander für jede Konfiguration.
- Latenz nach Config: gruppierte Balken mit p50- und p95-Latenz.
- TTFT by Config: Zeit bis zum ersten Token (p50 und p95).
- Gesamtanzahl der bereitgestellten Anforderungen: Anforderungsanzahl pro Konfiguration.
- Verlauf der QPS-Rampe: Liniendiagramme mit Tabs für QPS, QPS (ausgenommen Fehler), Latenz und Fehler. Enthält einen Schieberegler für maximale Benutzer, um auf niedrigere Parallelitätsbereiche zu fokussieren. Diagramme werden nach Berechnungsgröße (mittel und groß nebeneinander) gruppiert.
- Vollständige Ergebnistabelle: alle Konfigurationen mit Spitzen-QPS, Benutzern zu Spitzenzeiten, Latenz-Quantils und Fehlerrate.
- Testparameter: Konfigurationszusammenfassung zur Reproduzierbarkeit.
So interpretiert man Ergebnisse
- Spitzen-QPS: Der maximale QPS-Wert, der bei jedem Rampenschritt erreicht wurde. Dies ist die Durchsatzgrenze für diese Konfiguration.
- Benutzer am Spitzenwert: Die Anzahl der gleichzeitigen Benutzer, wenn Spitzen-QPS erreicht wurde. Durch das Hinzufügen weiterer Benutzer über diesen Punkt hinaus wird der Durchsatz nicht erhöht.
- Fehlerrate: sollte 0% oder sehr niedrig sein. Eine hohe Fehlerrate bedeutet, dass die App auf dieser Parallelitätsebene überladen ist.
- QPS-Rampendiagramm: Suchen Sie nach der Stelle, an der die Linie flach wird. Das ist der Sättigungspunkt: Durch das Hinzufügen weiterer Benutzer wird der Durchsatz nicht erhöht.
Problembehandlung
| Problem | Lösung |
|---|---|
| Das Authentifizierungstoken ist mitten im Test abgelaufen | Für Tests, die länger als ~1 Stunde sind, wechseln Sie von U2M zu M2M OAuth, indem Sie übergeben --client-id und --client-secret |
| Integritätsprüfung schlägt fehl | Überprüfen Sie, ob die App AKTIV ist: databricks apps get <name> --output json |
| 0 QPS oder keine Ergebnisse | Überprüfen Sie load-test-runs/<run-name>/<label>/locust_output.log auf Fehler |
| Niedrige QPS trotz hoher Benutzeranzahl | Die App ist gesättigt. Versuchen Sie es mit mehr Mitarbeitern oder einer größeren Berechnung. |
| Hohe Fehlerrate | Die App wird überladen. Verringern oder erhöhen Sie --max-users Arbeitskräfte/Rechenleistung. |
| Das Dashboard zeigt keine Rampendaten an. | Überprüfen, ob results_stats_history.csv in jedem Ergebnisunterverzeichnis vorhanden ist |
Nächste Schritte
- Testen Sie mit echten LLM-Aufrufen: Überspringen Sie den Simulierten Schritt, und stellen Sie Ihren tatsächlichen Agent bereit, um die End-to-End-Latenz einschließlich der LLM-Reaktionszeit zu messen.
- Optimieren sie die Anzahl der Mitarbeiter: Verwenden Sie die Testmatrixergebnisse, um die optimale Arbeitsanzahl für Ihre Berechnungsgröße zu ermitteln.
- Lernprogramm: Bewerten und Verbessern einer GenAI-Anwendung zur Messung von Genauigkeit, Relevanz und Sicherheit neben dem Durchsatz.