Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Datenflüsse sind sowohl in Azure Data Factory Pipelines als auch in Azure Synapse Analytics Pipelines verfügbar. Dieser Artikel gilt für Datenflusszuordnungen. Wenn Sie mit Transformationen noch nicht fertig sind, lesen Sie den einführungsartikel Transformieren von Daten mithilfe von Zuordnungsdatenflüssen.
Tipp
Informationen zur entsprechenden Transformation (Zusammenführen von Abfragen) in Dataflow Gen2 finden Sie in einer Anleitung zu Dataflow Gen2 zum Zuordnen von Datenflussbenutzern.
Mithilfe der Join-Transformation können Sie Daten aus zwei Quellen oder Streams in einem Zuordnungsdatenfluss miteinander kombinieren. Der Ausgabedatenstrom enthält alle Spalten aus beiden Quellen, die basierend auf einer Verknüpfungsbedingung übereinstimmen.
Join-Typen
Mapping-Datenflüsse unterstützen derzeit fünf verschiedene Jointypen.
Innerer Join
Bei einem inneren Join werden nur Zeilen ausgegeben, die übereinstimmende Werte in beiden Tabellen enthalten.
Linker äußerer Join
Bei einem linken äußeren Join werden alle Zeilen aus dem linken Stream sowie übereinstimmende Datensätze aus dem rechten Stream zurückgegeben. Ist für eine Zeile aus dem linken Stream keine Übereinstimmung vorhanden, werden die Ausgabespalten aus dem rechten Stream auf NULL festgelegt. Die Ausgabe umfasst die von einem inneren Join zurückgegebenen Zeilen sowie die nicht übereinstimmenden Zeilen aus dem linken Datenstrom.
Hinweis
Aufgrund eventueller kartesischer Produkte in den Joinbedingungen können gelegentlich Fehler bei der von Datenflüssen verwendeten Spark-Engine auftreten. Wenn dies geschieht, können Sie zu einem benutzerdefinierten Kreuzprodukt wechseln und die Joinbedingung manuell eingeben. Dies kann zu einer langsameren Leistung in Ihren Datenflüssen führen, da das Ausführungsmodul möglicherweise alle Zeilen von beiden Seiten der Beziehung berechnen und dann Zeilen filtern muss.
Rechter äußerer Join
Bei einem rechten äußeren Join werden alle Zeilen aus dem rechten Stream sowie übereinstimmende Datensätze aus dem linken Stream zurückgegeben. Ist für eine Zeile aus dem rechten Stream keine Übereinstimmung vorhanden, werden die Ausgabespalten aus dem linken Stream auf NULL festgelegt. Die Ausgabe umfasst die von einem inneren Join zurückgegebenen Zeilen sowie die nicht übereinstimmenden Zeilen aus dem rechten Datenstrom.
Vollständiger äußerer Join
Bei einem vollständigen äußeren Join werden alle Spalten und Zeilen von beiden Seiten ausgegeben, wobei für nicht übereinstimmende Spalten NULL-Werte verwendet werden.
Benutzerdefiniertes Kreuzprodukt
Bei Cross Join wird das Kreuzprodukt der beiden Streams basierend auf einer Bedingung ausgeführt. Geben Sie bei Verwendung einer anderen Bedingung als Gleichheit einen benutzerdefinierten Ausdruck als Kreuzverbindungskriterium an. Der Ausgabedatenstrom ist alle Zeilen, die der Verknüpfungsbedingung entsprechen.
Dieser Jointyp kann für Ungleichheitsverknüpfungen und OR-Bedingungen verwendet werden.
Wenn Sie explizit ein vollständiges kartesisches Produkt erzeugen möchten, verwenden Sie in jedem der beiden unabhängigen Datenströme vor der Verknüpfung die Transformation für abgeleitete Spalten, um einen synthetischen Schlüssel zum Abgleichen zu erstellen. Erstellen Sie z. B. mit der Transformation für abgeleitete Spalten eine neue Spalte in jedem Datenstrom mit dem Namen SyntheticKey und legen Sie ihn auf 1 fest. Verwenden Sie dann a.SyntheticKey == b.SyntheticKey als benutzerdefinierten Joinausdruck.
Hinweis
Achten Sie darauf, dass Sie mindestens eine Spalte von jeder Seite der linken und rechten Beziehung in ein benutzerdefiniertes Kreuzprodukt einbeziehen. Die Ausführung von Kreuzprodukten mit statischen Werten anstelle von Spalten von jeder Seite führt zu vollständigen Überprüfungen des gesamten Datasets, sodass der Datenfluss mit geringer Leistung ausgeführt wird.
Fuzzy-Join
Sie können die Verknüpfung auf der Grundlage einer unscharfen Verknüpfungslogik anstelle eines exakten Abgleichs der Spaltenwerte vornehmen, indem Sie das Kontrollkästchen „Unscharfen Abgleich verwenden“ aktivieren.
- Textteile kombinieren: Verwenden Sie diese Option, um Übereinstimmungen zu finden, indem Sie Leerzeichen zwischen Wörtern entfernen. Zum Beispiel stimmt Data Factory mit DataFactory überein, wenn diese Option aktiviert ist.
- Spalte für die Ähnlichkeitsbewertung: Sie können optional wählen, ob Sie die Ähnlichkeitsbewertung für jede Zeile in einer Spalte speichern möchten, indem Sie hier einen neuen Spaltennamen eingeben, um diesen Wert zu speichern.
- Ähnlichkeitsschwellenwert: Wählen Sie einen Wert zwischen 60 und 100 als prozentuale Übereinstimmung zwischen den Werten in den von Ihnen ausgewählten Spalten.

Hinweis
Fuzzy-Übereinstimmung funktioniert derzeit nur mit Spalten vom Typ Zeichenfolge und mit inneren, linken äußeren und vollständigen äußeren Join-Typen. Sie müssen die Broadcast-Optimierung deaktivieren, wenn Sie Fuzzy-Matching-Joins verwenden.
Konfiguration
- Wählen Sie in der Dropdownliste Rechter Stream den Datenstrom für die Verknüpfung aus.
- Wählen Sie den gewünschten Jointyp aus.
- Wählen Sie die Schlüsselspalten aus, auf denen der Abgleich für Ihre Verknüpfungsbedingung basieren soll. Standardmäßig sucht der Datenfluss nach Übereinstimmung mit einer Spalte in jedem Datenstrom. Wenn der Vergleich auf einem berechneten Wert basieren soll, zeigen Sie mit dem Mauszeiger auf die Dropdownliste für die Spalte, und wählen Sie Berechnete Spalte aus.
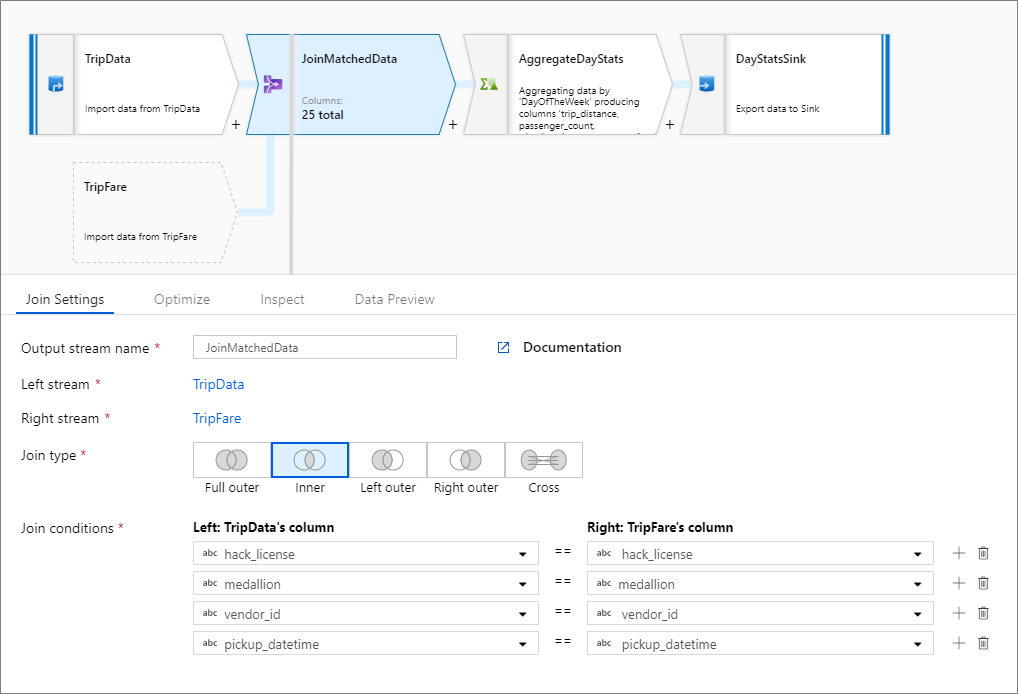
Nicht-Gleichheitsverknüpfungen
Wenn Sie in Ihren Joinbedingungen einen bedingten Operator wie „ungleich“ „(!=)“ oder „größer als“ (>) verwenden möchten, ändern Sie die Dropdownliste des Operators zwischen den beiden Spalten. Bei Nicht-Gleichheitsverknüpfungen muss mindestens einer der beiden Datenströme mithilfe der Übertragungsoption Fixed (Fest) auf der Registerkarte Optimieren übertragen werden.

Optimieren der Leistung beim Verknüpfen
Im Gegensatz zu „Merge Join“ in Tools wie SSIS ist die Join-Transformation kein obligatorischer Vorgang vom Typ „Merge Join“. Die Join-Schlüssel müssen nicht sortiert werden. Der Join-Vorgang erfolgt basierend auf dem optimalen Join-Vorgang in Spark (Broadcast- oder Map-Side-Join).
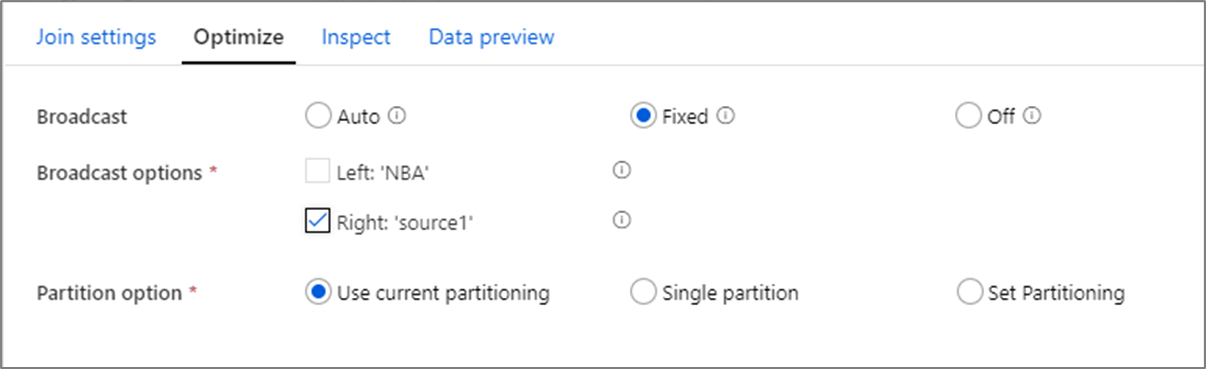
Wenn bei Join, Lookup- und Exists-Transformationen der Arbeitsspeicher des Workerknotens groß genug für einen oder beide Datenströme ist, können Sie die Leistung optimieren, indem Sie die Übertragung aktivieren. Standardmäßig entscheidet die Spark-Engine automatisch, ob eine Seite übertragen werden soll oder nicht. Klicken Sie auf Fest, um die zu übertragende Seite manuell auszuwählen.
Es wird nicht empfohlen, die Übertragung über die Option Off (Aus) zu deaktivieren, es sei denn, für Ihre Joins treten Timeoutfehler auf.
Selbstverknüpfung
Wenn Sie einen Datenstrom mit sich selbst verknüpfen möchten, müssen Sie einen vorhandenen Stream per Auswahltransformation mit einem Alias versehen. Erstellen Sie einen neuen Branch, indem Sie neben einer Transformation auf das Pluszeichen klicken und Neuer Branch auswählen. Fügen Sie eine Auswahltransformation hinzu, um den ursprünglichen Stream mit einem Alias zu versehen. Fügen Sie eine Join-Transformation hinzu. Wählen Sie dabei den ursprünglichen Stream als Linker Stream und die Auswahltransformation als Rechter Stream aus.
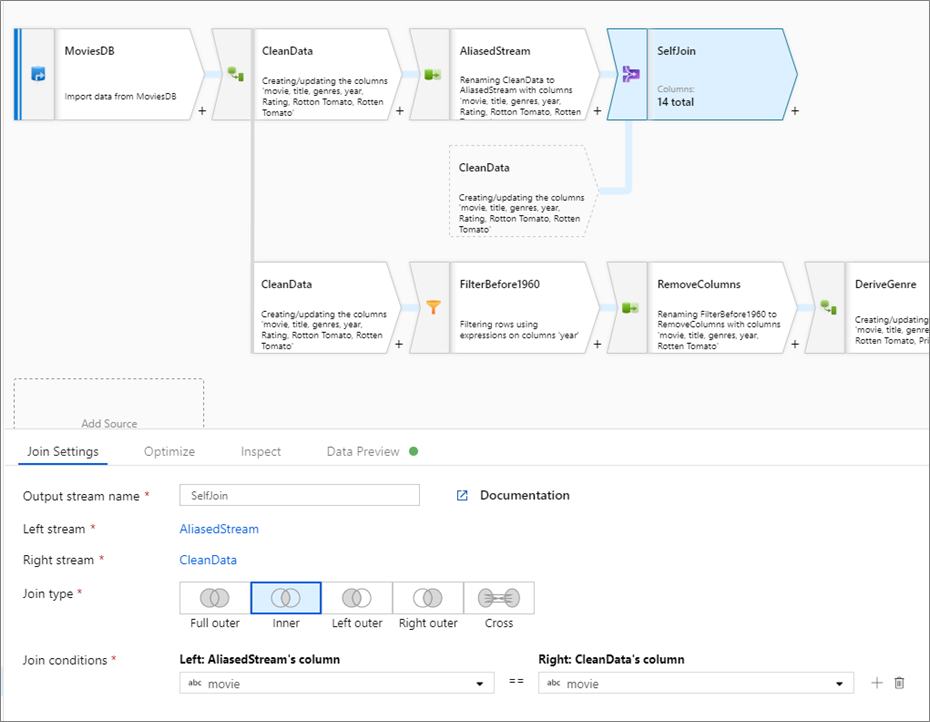
Testen der Join-Bedingungen
Verwenden Sie einen kleinen Satz bekannter Daten, wenn Sie die Join-Transformationen mit Datenvorschau im Debugmodus testen. Beim Sampling von Zeilen aus einem großen Dataset können Sie nicht vorhersagen, welche Zeilen und Schlüssel zum Testen gelesen werden. Das Ergebnis ist nicht deterministisch, was bedeutet, dass Ihre Verknüpfungsbedingungen möglicherweise keine Übereinstimmungen zurückgeben.
Datenflussskript
Syntax
<leftStream>, <rightStream>
join(
<conditionalExpression>,
joinType: { 'inner'> | 'outer' | 'left_outer' | 'right_outer' | 'cross' }
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <joinTransformationName>
Beispiel für einen inneren Join
Dieses Beispiel ist eine Join-Transformation mit dem Namen JoinMatchedData, die den linken Datenstrom TripData und den rechten Datenstrom TripFare verarbeitet. Die Verknüpfungsbedingung ist der Ausdruck hack_license == { hack_license} && TripData@medallion == TripFare@medallion && vendor_id == { vendor_id} && pickup_datetime == { pickup_datetime}, der „true“ zurückgibt, wenn die Spalten hack_license, medallion, vendor_id und pickup_datetime in den beiden Streams übereinstimmen. Der Jointyp (joinType) lautet 'inner'. Da Broadcasting nur im linken Stream aktiviert wird, hat broadcast den Wert 'left'.
In der Benutzeroberfläche sieht diese Transformation wie folgt aus:
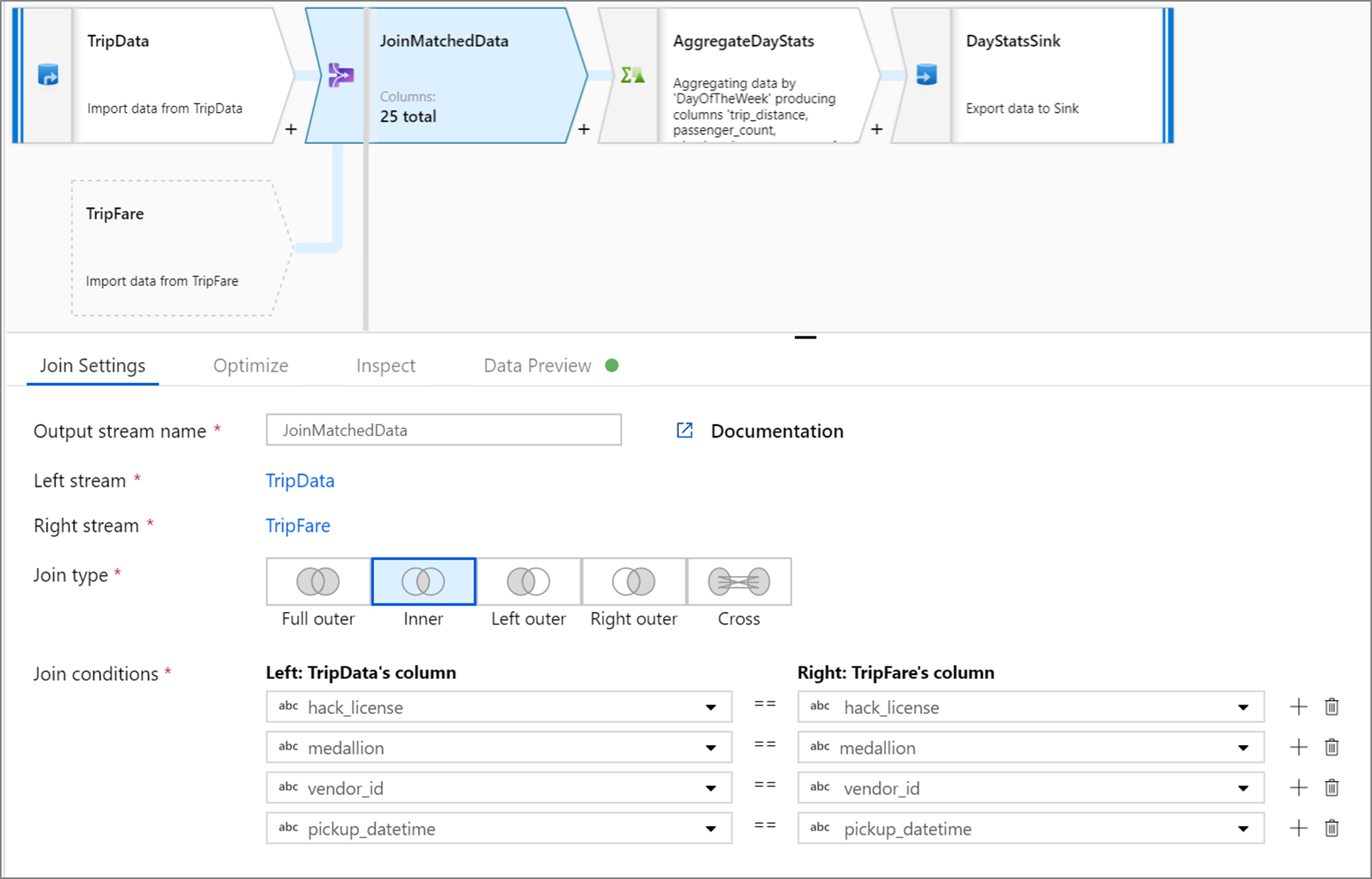
Das Datenflussskript für diese Transformation befindet sich in diesem Codeausschnitt:
TripData, TripFare
join(
hack_license == { hack_license}
&& TripData@medallion == TripFare@medallion
&& vendor_id == { vendor_id}
&& pickup_datetime == { pickup_datetime},
joinType:'inner',
broadcast: 'left'
)~> JoinMatchedData
Beispiel für ein benutzerdefiniertes Kreuzprodukt
Dieses Beispiel ist eine Verknüpfungstransformation namens JoiningColumns, die den linken Strom LeftStream und den rechten Strom RightStream übernimmt. Diese Transformation übernimmt zwei Streams und verknüpft alle Zeilen, in denen die Spalte leftstreamcolumn größer als die Spalte rightstreamcolumn ist. Der Jointyp (joinType) lautet cross. Die Übertragung ist nicht aktiviert broadcast hat den Wert 'none'.
In der Benutzeroberfläche sieht diese Transformation wie folgt aus:
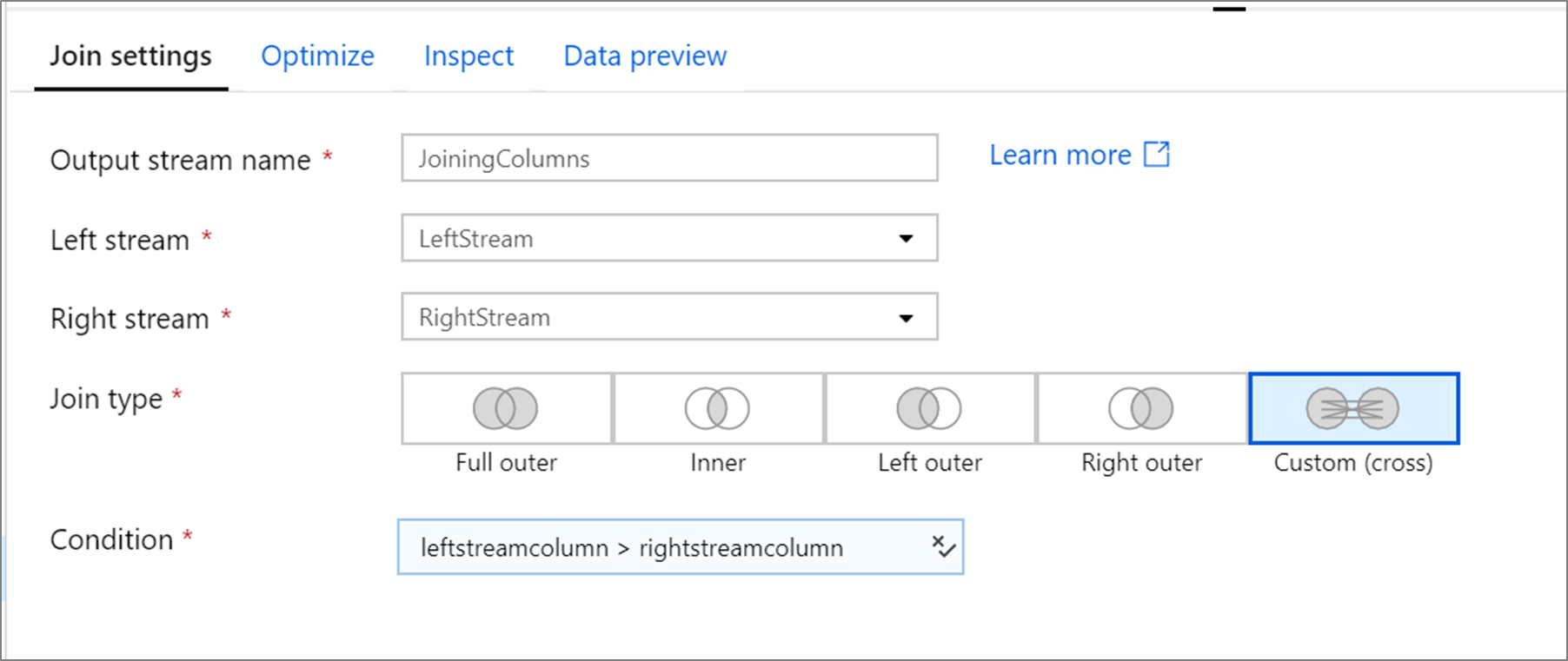
Das Datenflussskript für diese Transformation befindet sich im Codeausschnitt:
LeftStream, RightStream
join(
leftstreamcolumn > rightstreamcolumn,
joinType:'cross',
broadcast: 'none'
)~> JoiningColumns
Zugehöriger Inhalt
Erstellen Sie nach dem Verknüpfen von Daten eine abgeleitete Spalte, und senken Sie Ihre Daten in einen Zieldatenspeicher.