Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Datenflüsse sind sowohl in Azure Data Factory Pipelines als auch in Azure Synapse Analytics Pipelines verfügbar. Dieser Artikel gilt für Datenflusszuordnungen. Wenn Sie mit Transformationen noch nicht fertig sind, lesen Sie den einführungsartikel Transformieren von Daten mithilfe von Zuordnungsdatenflüssen.
Tipp
Die entsprechende Transformation (benutzerdefinierte Funktionen) in Dataflow Gen2 finden Sie in einer Anleitung zu Dataflow Gen2 zum Zuordnen von Datenflussbenutzern.
Verwenden Sie die Flowlet-Transformation, um ein zuvor erstelltes Mapping-Datenfluss-Flowlet auszuführen. Eine Übersicht über Flowlets finden Sie unter Flowlets im Zuordnungsdatenfluss | Microsoft-Dokumentation
Hinweis
Die Flowlettransformation in Azure Data Factory- und Synapse Analytics-Pipelines befindet sich derzeit in der öffentlichen Vorschau.
Konfiguration
Die Flowlettransformation enthält die folgenden Konfigurationseinstellungen:

Flowlet
Wählen Sie das Flowlet aus, das ausgeführt werden soll. Sobald das Flowlet ausgewählt ist, können Sie ggf. Eingabespalten auf der Registerkarte „Zuordnung“ zuordnen.
Zuordnung
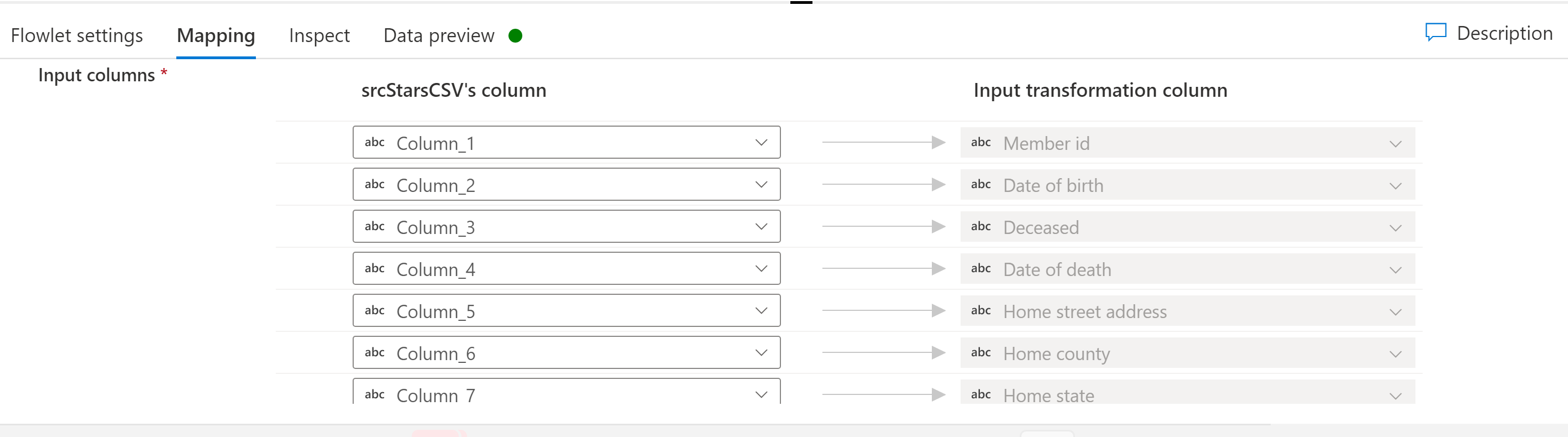
Wenn das ausgewählte Flowlet Eingabespalten enthält, können Sie Spalten aus dem Eingabestream den erwarteten Eingabespalten im Flowlet zuordnen. Diese Zuordnung der Spalten des Zuordnungsdatenflusses zum Flowlet ermöglicht es, dass Flowlets als wiederverwendbare Ausschnitte der Logik des Zuordnungsdatenflusses für potenziell viele Zuordnungsdatenflüsse genutzt werden können.
Datenflussskript
Syntax
<incomingStream>
<transformation> ~> <transformationName>
<outputStream>
Beispiel
source1 derive(Test = "test") ~> DerivedColumn1
DerivedColumn1 output() ~> output1