Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Verwenden Sie die folgenden Strategien, um die Leistung von Transformationen bei der Zuordnung von Datenflüssen in Azure Data Factory- und Azure Synapse Analytics-Pipelines zu optimieren.
Optimieren von Verknüpfungen, Existenzprüfungen und Nachschlagen
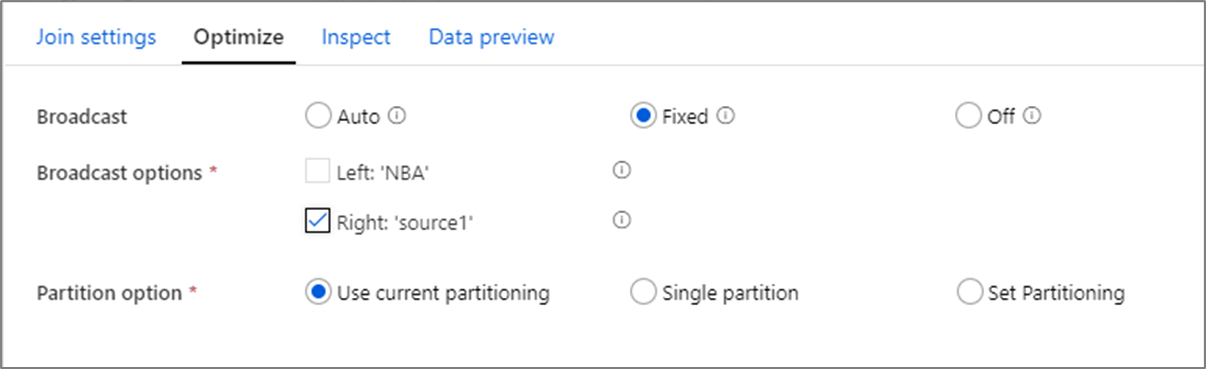
Rundfunk
Bei Verknüpfungen, Nachschlagevorgängen und existierenden Transformationen können Sie die Leistung optimieren, indem Sie Broadcasting aktivieren, wenn ein oder beide Datenströme klein genug sind, um in den Arbeitsspeicher des Arbeitsknotens zu passen. Die Übertragung erfolgt, wenn Sie kleine Datenframes an alle Knoten im Cluster senden. Dadurch kann das Spark-Modul eine Verknüpfung durchführen, ohne die Daten im großen Datenstrom erneut zu überführen. Standardmäßig entscheidet das Spark-Modul automatisch, ob eine Seite einer Verknüpfung übertragen werden soll. Wenn Sie mit Ihren eingehenden Daten vertraut sind und wissen, dass ein Datenstrom kleiner als der andere ist, können Sie "Feste Übertragung" auswählen. Spark zwingt zur Übertragung des ausgewählten Datenstroms.
Wenn die Größe der übertragenen Daten für den Spark-Knoten zu groß ist, kann es zu einem Fehler wegen unzureichenden Arbeitsspeichers kommen. Verwenden Sie speicheroptimierte Cluster, um Speicherfehler zu vermeiden. Wenn Sie Broadcast-Zeitüberschreitungen während der Datenflussausführung erleben, können Sie die Broadcast-Optimierung deaktivieren. Dies führt jedoch zu langsamer arbeitenden Datenflüssen.
Wenn Sie mit Datenquellen arbeiten, die länger benötigen können, um abgefragt zu werden, wie etwa große Datenbankabfragen, empfiehlt es sich, Broadcast bei Verknüpfungen zu deaktivieren. Quellen mit langen Abfragezeiten können Spark-Timeouts verursachen, wenn der Cluster versucht, an die Computeknoten zu senden. Eine weitere gute Wahl zum Deaktivieren der Übertragung ist, wenn Sie einen Datenstrom in Ihrem Datenfluss haben, der Werte für die spätere Verwendung in einer Nachschlagetransformation aggregiert. Dieses Muster kann den Spark-Optimierer verwechseln und Timeouts verursachen.
Kreuzverknnungen
Wenn Sie Literalwerte in Ihren Verknüpfungsbedingungen verwenden oder mehrere Übereinstimmungen auf beiden Seiten einer Verknüpfung haben, führt Spark die Verknüpfung als Kreuzverknallung aus. Eine Kreuzverknüpfung ist ein vollständiges kartesisches Produkt, die anschließend die verknüpften Werte herausfiltert. Dies ist langsamer als andere Verknüpfungstypen. Stellen Sie sicher, dass auf beiden Seiten der Verknüpfungsbedingungen Spaltenverweise vorliegen, um die Leistungseinbußen zu vermeiden.
Sortieren vor Verknüpfungen
Im Gegensatz zur Zusammenführung in Tools wie SSIS ist die Verknüpfungstransformation kein obligatorischer Zusammenführungsvorgang. Die Verknüpfungsschlüssel erfordern keine Sortierung vor der Transformation. Die Verwendung von Sortiertransformationen in Zuordnungsdatenflüssen wird nicht empfohlen.
Leistung der Fenstertransformation
Die Fenstertransformation in der Zuordnung von Datenfluss partitioniert Ihre Daten nach Wert in Spalten, die Sie als Teil der over() Klausel in den Transformationseinstellungen auswählen. Es gibt viele beliebte Aggregat- und Analysefunktionen, die in der Windows-Transformation verfügbar gemacht werden. Wenn Ihr Anwendungsfall jedoch das Generieren eines Fensters über dem gesamten Dataset für die Rangfolge rank() oder Zeilennummer rowNumber()ist, empfiehlt es sich, stattdessen die Rangtransformation und die Surrogate-Schlüsseltransformation zu verwenden. Diese Transformationen erzielen erneut bessere Ergebnisse bei vollständigen Dataset-Operationen unter Verwendung dieser Funktionen.
Neupartitionieren schiefer Daten
Bestimmte Transformationen, wie z. B. Verknüpfungen und Aggregate, ordnen Ihre Datenpartitionen neu an und können gelegentlich zu ungleich verteilten Daten führen. Schiefe Daten bedeuten, dass Daten nicht gleichmäßig über die Partitionen verteilt werden. Stark schiefe Daten können zu langsameren nachgelagerten Transformationen und Sinkschreibvorgängen führen. Sie können die Schiefe Ihrer Daten zu einem beliebigen Zeitpunkt in einem Datenflusslauf überprüfen, indem Sie auf die Transformation in der Überwachungsanzeige klicken.

Die Überwachungsanzeige zeigt, wie die Daten über jede Partition verteilt sind, sowie die beiden Metriken Schiefe und Kurtosis. Die Schiefe ist ein Maß dafür, wie asymmetrisch die Daten sind und einen positiven, null-, negativen oder nicht definierten Wert aufweisen können. Negative Schiefe bedeutet, dass der linke Schwanz länger als der rechte ist. Kurtosis ist das Maß dafür, ob die Daten schwer oder hellschwanzig sind. Hohe Kurtosis-Werte sind nicht wünschenswert. Idealbereiche der Schiefe liegen zwischen -3 und 3, und der Bereich der Kurtosis ist kleiner als 10. Eine einfache Möglichkeit, diese Zahlen zu interpretieren, besteht darin, das Partitionsdiagramm zu betrachten und zu sehen, ob 1 Balken größer als der Rest ist.
Wenn Ihre Daten nach einer Transformation nicht gleichmäßig partitioniert werden, können Sie die Registerkarte "Optimieren" verwenden, um die Partition neu zu partitionieren. Das Umstrukturieren von Daten ist zeitaufwendig und verbessert möglicherweise die Leistung des Datenflusses nicht.
Tipp
Wenn Sie Ihre Daten neu partitionieren, aber über nachgeschaltete Transformationen verfügen, die Ihre Daten neu anfügen, verwenden Sie die Hashpartitionierung für eine Spalte, die als Verknüpfungsschlüssel verwendet wird.
Hinweis
Transformationen innerhalb des Datenflusses (mit Ausnahme der Sinktransformation) ändern die Datei- und Ordnerpartitionierung der ruhenden Daten nicht. Bei jeder Transformation werden die Daten innerhalb der Datenframes des temporären serverlosen Spark-Clusters, den ADF für jede Ihrer Datenflussausführungen verwaltet, neu partitioniert.
Verwandte Inhalte
- Übersicht über die Datenflussleistung
- Optimieren von Quellen
- Optimieren von Senken
- Verwenden von Datenflüssen in Pipelines
Weitere Artikel zum Datenfluss finden Sie in Bezug auf die Leistung: