Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Microsoft Purview Data Quality für lokale Datenquellen ermöglicht Organisationen die Bewertung, Überwachung und Verbesserung der Qualität von Daten, die in internen Systemen wie Datenbanken und Legacyplattformen gespeichert sind. Es unterstützt regelbasierte Validierungs-, Fehlererkennungs- und Korrekturworkflows und stellt gleichzeitig die Einhaltung von Organisationsrichtlinien sicher. Durch die Integration in die vorhandene Infrastruktur bietet es konsistente Einblicke in die Datenqualität und Governance in lokalen und Cloudumgebungen.
Mithilfe einer selbstgehosteten Datenintegrationslaufzeit können Sie Datenqualitätsprozesse skalieren, indem Sie lokale Datenquellen sicher mit Purview verbinden. In diesem Artikel wird die kubernetes-basierte, Linux selbstgehostete Datenintegrationslaufzeit behandelt, die die zugrunde liegende Infrastruktur verbessert und mehrere wichtige Vorteile bietet:
- Skalierbarkeit: Möglichkeit, auf Hunderte von Computern zu skalieren.
- Leistung: Verbesserte Leistung für Überprüfungsworkloads.
- Sicherheit (containerisiert): Ermöglicht die containerisierte Bereitstellung in einem Kubernetes-Cluster, sodass die Datenintegrationslaufzeit nicht direkt auf einem Windows-Computer gehostet werden muss.
Unterstützte Datenquellen
- Oracle
- SQL Server
Architektur
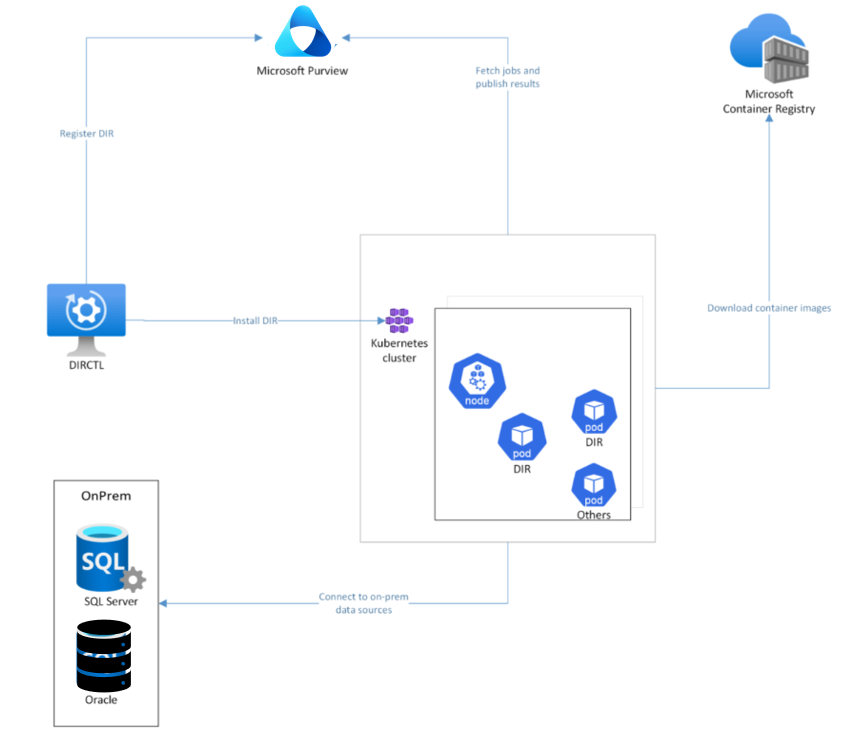
In einer allgemeinen Architekturansicht werden beim Installieren einer Kubernetes-basierten Datenintegration runtime mehrere Pods automatisch auf den Knoten Ihres Kubernetes-Clusters erstellt. Ein Befehlszeilentool namens DIRCTL löst diese Installation aus. DIRCTL stellt eine Verbindung mit dem Microsoft Purview-Dienst her, um die Datenintegrationslaufzeit zu registrieren und eine Verbindung mit dem Kubernetes-Cluster herzustellen, um die selbstgehostete Datenintegrationslaufzeit zu installieren.
Während der Installation lädt der Prozess Datenintegration Runtime-Images von MCR (Microsoft Container Registries) in die Datenintegration Runtime-Pods herunter. Nach abschluss der Installation stellen die Pods in Ihrem Cluster eine Verbindung mit dem Purview-Dienst her, um Scanaufträge zu pullen. Wenn ein Scanauftrag pulled wird, kann er Ihre lokale Datenquelle für die Data Quality-Überprüfung verbinden.
Voraussetzungen
Datenintegration Runtime-Befehlszeilentool (DIRCTL)
Sie benötigen das Datenintegration Runtime-Befehlszeilentool (DIRCTL), um die Datenintegrationslaufzeit einzurichten. Anweisungen zum Herunterladen und installieren finden Sie unter Einrichten des DIRCTL-Tools für die selbstgehostete Integration Runtime (Vorschauversion).
Rollen
Zum Einrichten einer selbstgehosteten integrierten Runtime in Purview benötigen Sie die Rolle Data Governance-Administrator.
Kubernetes-Cluster
Sie benötigen einen vorhandenen Linux-basierten Kubernetes-Cluster, oder Sie müssen einen vorbereiten. Identifizieren Sie die Knoten mithilfe einer Knotenauswahl, die der Definition der Kubernetes-Knotenauswahl folgt. Mindestkonfiguration:
- Containertyp: Linux
- Kubernetes-Version: 1.24.9 oder höher
- Knotenbetriebssystem: Linux basiertes Betriebssystem, das auf der x86-Architektur ausgeführt wird
- Knotenspezifikation: mindestens acht Kerne CPU, 32 GB Arbeitsspeicher und mindestens 80 GB verfügbarer Festplattenspeicher
- Knotenanzahl: 1 oder mehr (fest, automatische Clusterskalierung nicht aktiviert)
- Podnummer pro Knoten: 20 oder mehr (maximale Podnummer – Anzahl anderer Pods, die nicht zu Self-Hosted IR gehören)
Hinweis
Der Ordner /var/irstorage/ jedes Knotens ist für die selbstgehostete integrierte Runtime reserviert. Es ist lesbar und kann in der Datenintegrationslaufzeit geschrieben werden. Sie können Protokolle aus diesem Ordner abrufen oder externe Treiber in diesen Ordner hochladen. Die Datenintegrationslaufzeit erstellt den Ordner, wenn er nicht vorhanden ist, und löscht den Ordner nicht, nachdem die Datenintegrationslaufzeit gelöscht wurde. Die von der Datenintegrationslaufzeit verwendeten Containerimages werden von Der Kubernetes Garbage Collection verwaltet, die nicht von der Datenintegrationslaufzeit bereinigt wird. Konfigurieren Sie den richtigen Schwellenwert für Ihren Kubernetes-Cluster.
Ausgehende Konnektivität ist erforderlich, um Containerimages zu pullen sowie für den weiteren Betrieb, der Aktivitäten wie das Pullen von Datenqualitätsaufträgen und das Pushen generierter Statistiken umfasst.
Kubernetes-Kontext
Kubernetes-Kontext, der Kubernetes-Clusterinformationen sowie Benutzerberechtigungen und Anmeldeinformationen für diesen Cluster enthält, ist für die Kommunikation mit Ihrem Kubernetes-Cluster erforderlich. Um die Konfiguration der Benutzerberechtigungen für die DIR-Verwaltung zu vereinfachen, können Sie mit Kubernetes Admin Rolle beginnen. Dieser Kontext wird beim Einrichten Ihres Kubernetes-Clusters generiert und in einer Konfigurationsdatei gespeichert. Wo und wie Sie diese Datei abrufen können, hängt von Ihrer Einrichtung des Kubernetes-Clusters ab.
Wenn Sie kubeadm init zum Einrichten des Kubernetes-Clusters verwenden, finden Sie die Konfigurationsdatei unter
/etc/Kubernetes/admin.conf.Wenn Sie AKS verwenden, können Sie die Anleitung von AKS befolgen, um den Az PowerShell-Modulbefehl zu verwenden, um Anmeldeinformationen für diesen Cluster auf Ihrem lokalen Computer abzurufen. Sie können den Kontext direkt mit der Konfigurationsdatei unter
$HOME/.kube/configzusammenführen.Wenn Sie andere Tools zum Einrichten eines Kubernetes-Clusters verwenden, lesen Sie die Kubernetes-Dokumentation.
Nachdem Sie die Konfigurationsdatei für den Kubernetes-Kontext abgerufen haben, führen Sie sie mit der Konfigurationsdatei
$HOME/.kube/configauf dem Computer zusammen, auf dem Sie den IRCTL-Befehl ausführen möchten. Alternativ können Sie die Konfigurationsdatei des Kubernetes-Kontexts in einer Umgebungsvariablen mit dem NamenKUBECONFIGfestlegen. Weitere Informationen zum Kubernetes-Kontext finden Sie unter Konfigurieren des Zugriffs auf mehrere Cluster.
Einrichten einer selbstgehosteten Datenintegrationslaufzeit
Wechseln Sie zu Einstellungen>Microsoft Purview Unified Catalog>Datenintegration Runtime, und wählen Sie dann Neu aus, um eine Datenintegrationslaufzeit zu erstellen.
Geben Sie einen Namen und eine Beschreibung für die selbstgehostete integrierte Runtime ein, und wählen Sie dann Erstellen aus.
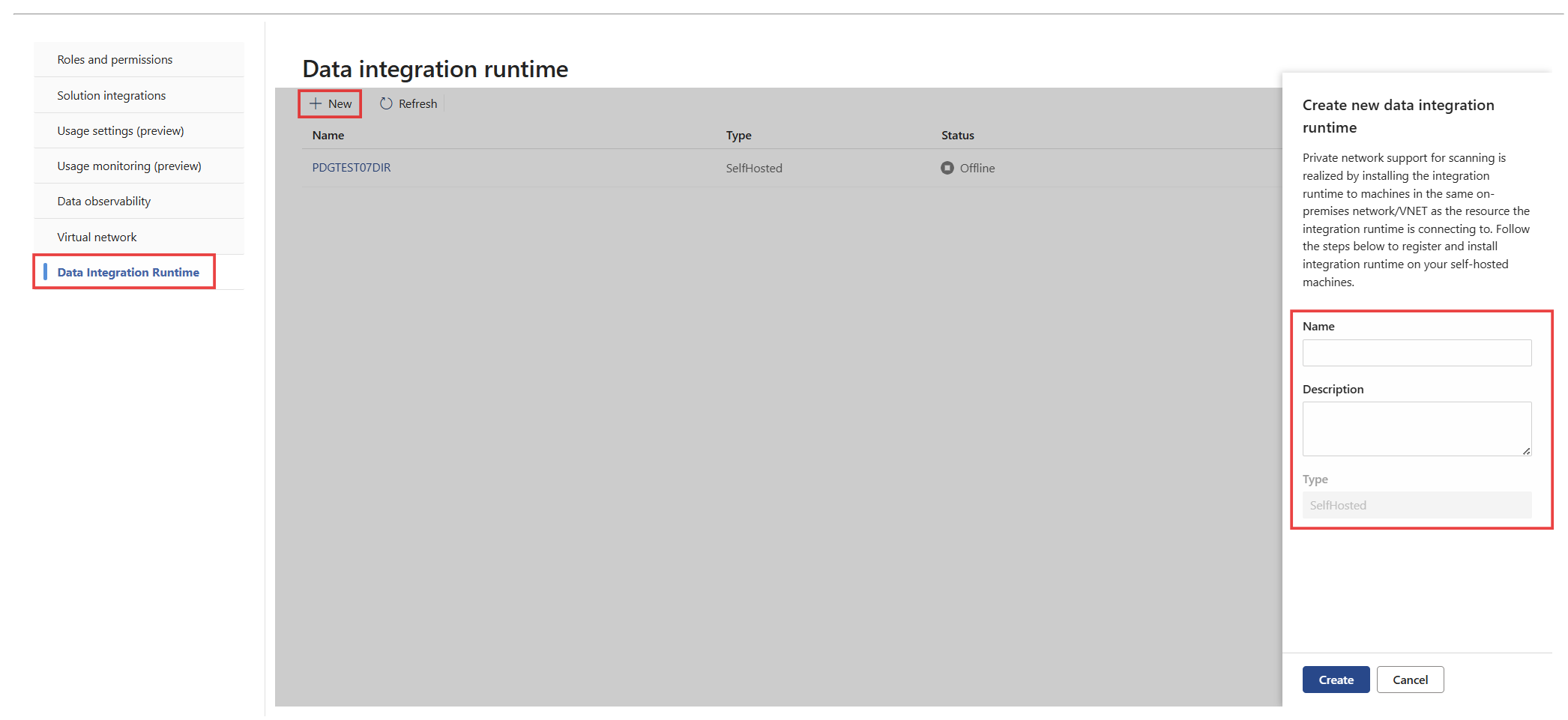
Wählen Sie Schlüssel generieren aus, um einen Registrierungsschlüssel zu generieren und Ihre Datenintegrationslaufzeit zu registrieren.
Kopieren Sie den Schlüsselwert, und wählen Sie Fertig aus.
Tipp
Bei Bedarf können Sie einen Schlüssel erneut generieren oder einen generierten Schlüssel widerrufen.
Wählen Sie For Linux aus, um das DIRCTL-Tool (Datenintegration Runtime Command Line) herunterzuladen. Hier finden Sie Details zum Installieren und Verwalten von DIRCTL.
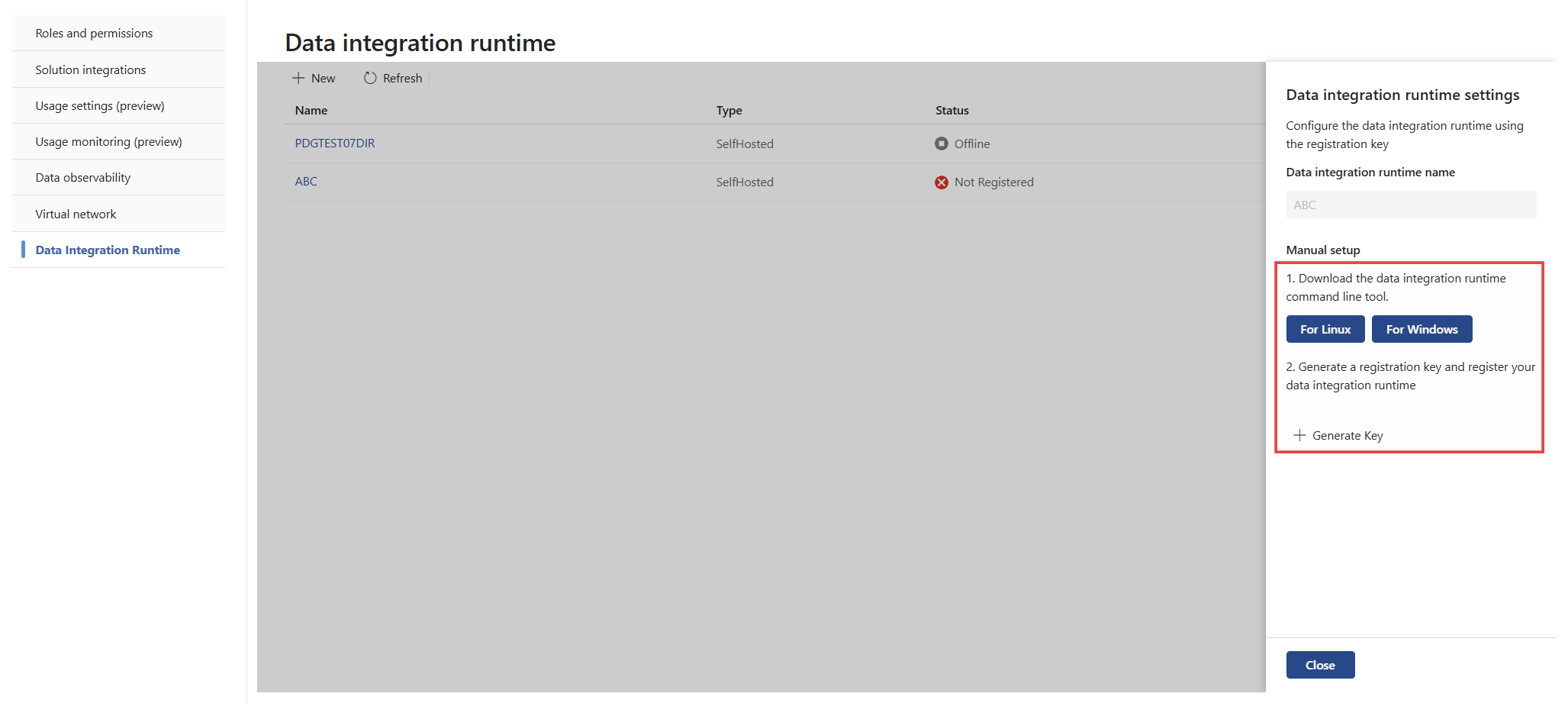
Installieren Sie DIRCTL auf dem Computer, auf dem Sie die DIRCTL-Befehlszeile ausführen möchten, über den Download. DIRCTL stellt eine Verbindung mit Ihrem Kubernetes-Cluster über den Kontext der Kube-Konfiguration her. Wenn Sie keinen Kontext angeben, verwendet DIRCTL den aktuellen Kontext. Sie können den Kontext auf eine von zwei Arten festlegen:
- Führen Sie
kubectldie Befehlszeile aus, und führen Sie diesen Befehl aus, um den aktuellen Kontext zu bestätigen:-
kubectl config get-contexts: Auflisten aller auf dem Computer konfigurierten Kontexte -
kubectl config current-context: Abrufen des aktuellen Kontextnamens kubectl config use-context <name of context>
-
- Führen Sie DIRCTL aus, und führen Sie aus
-context, um den Kontext in der Kube-Konfiguration anzugeben.
- Führen Sie
Führen Sie den Befehl DIRCTL Create aus:
./DIRCTL create - -registration-key <registration-key copied from the portal>. Der Befehl DIRCTL Create registriert eine neue Datenintegration Runtime bei Data Quality und initiiert die Erstellung einer Anwendung in Kubernetes als Pod, der für die registrierte Datenintegrationslaufzeit spezifisch ist. Es übernimmt die Bereitstellung von Ressourcen und die Konfiguration, die für die Funktionalität der Datenintegrationslaufzeit wichtig sind, und behält gleichzeitig die Kompatibilität mit den vorhandenen Systemanforderungen bei.
Nach Abschluss der Registrierung können Sie die status der Datenintegrationslaufzeit auf der Seite Datenintegration Runtime unter Einstellungen überprüfen. Die status wird als Online angezeigt. Sie können auch die status Ihrer Datenintegrationslaufzeit überprüfen, indem Sie den folgenden Befehl ausführen: ./DIRCTL describe.
Tipp
Dies sind die öffentlichen Endpunkte, mit denen die Datenintegrationslaufzeit eine Verbindung herstellt und die zugelassen werden müssen:
- < >purview_account_name.purview.azure.com
- Mcr.microsoft.com
- *.data.mcr.microsoft.com
Einrichten einer lokalen Datenquellenverbindung mit der Datenintegrationslaufzeit
Herstellen einer Verbindung mit Ihrer Oracle-Datenbank
Erstellen Sie Verbindungen, indem Sie sie einer Datenintegrationslaufzeit instance zuordnen.
- Wechseln Sie Unified Catalog zu Integritätsverwaltung>Datenqualität.
- Wählen Sie die Governancedomäne aus, in der Sie Ihr Datenprodukt mit Oracle-Datenressource erstellt haben.
- Wählen Sie Verwalten und dann Verbindung aus, um die Verbindung für Ihre Oracle-Datenbank einzurichten.
Fügen Sie die folgenden Informationen hinzu, um die Verbindung einzurichten:
- Geben Sie einen Anzeigenamen für die Verbindung ein.
- Geben Sie eine Beschreibung ein.
- Wählen Sie unter Quelltypdie Option Oracle aus.
- Wählen Sie die Datenintegrationslaufzeit aus, die Sie als Teil der Voraussetzung erstellt haben.
- Geben Sie den Hostnamen ein.
- Geben Sie die Portnummer ein.
- Geben Sie den Dienstnamen ein.
- Geben Sie den Schemanamen ein.
- Wählen Sie eine Authentifizierungsmethode aus.
- Geben Sie den Benutzernamen ein.
- Geben Sie unter Anmeldeinformationen die Azure Abonnement, Azure Key Vault Verbindung, Geheimnisname und Geheimnisversion ein.
- Wählen Sie Senden aus, um die Verbindungseinrichtung abzuschließen.
Tipp
Wenn Sie nicht über alle erforderlichen Informationen verfügen, wählen Sie Als Entwurf speichern aus, um später fortzufahren, wenn Sie über die restlichen Informationen zum Abschließen der Verbindungseinrichtung verfügen.
In dieser Abbildung wird veranschaulicht, wie Sie eine Verbindung erstellen:

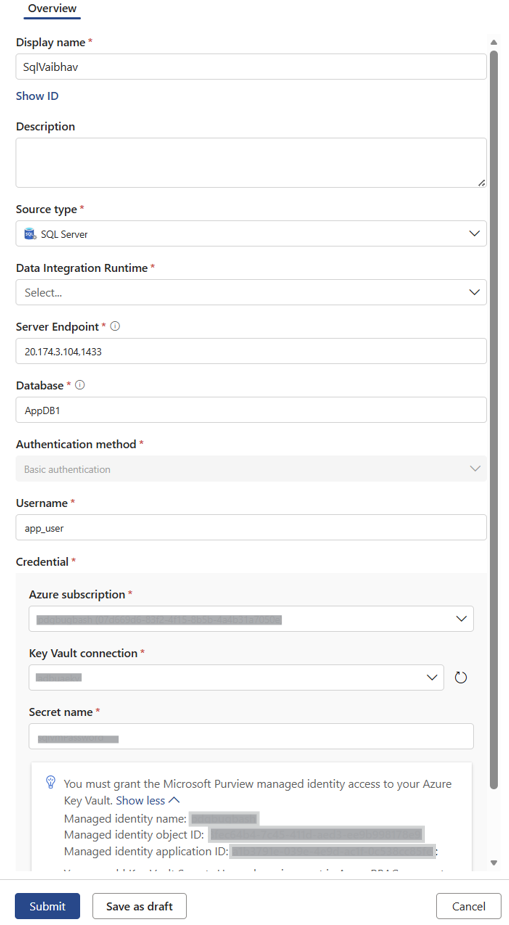
Herstellen einer Verbindung mit Ihrer SQL Server-Datenbank
Erstellen Sie Verbindungen, indem Sie sie wie bei Oracle einer Datenintegrationslaufzeit instance zuordnen. In SQL Server kann eine einzelne Datenbank Tabellen enthalten, die zu mehreren Schemas gehören, sodass Sie eine einzelne Verbindung verwenden können, um alle Schemas in einer einzelnen Datenbank zu überprüfen. Eine Verbindung akzeptiert nur Datenbankinformationen, aber kein Schema. Erstellen Sie verbindungen für SQL Server genau wie für andere Datenquellentypen.
- Wechseln Sie Unified Catalog zu Integritätsverwaltung>Datenqualität.
- Wählen Sie die Governancedomäne aus, in der Sie Ihr Datenprodukt mit Oracle-Datenressource erstellt haben.
- Wählen Sie Verwalten und dann Verbindung aus, um die Verbindung für Ihre Oracle-Datenbank einzurichten.
Fügen Sie die folgenden Informationen hinzu, um die Verbindung erfolgreich einzurichten:
- Geben Sie einen Anzeigenamen für die Verbindung ein.
- Geben Sie eine Beschreibung ein.
- Wählen Sie unter Quelltypdie Option SQL Server aus.
- Wählen Sie die Datenintegrationslaufzeit aus, die Sie als Teil der Voraussetzung erstellt haben.
- Geben Sie den Serverendpunkt ein.
- Geben Sie den Datenbanknamen ein.
- Wählen Sie eine Authentifizierungsmethode aus.
- Geben Sie den Benutzernamen ein.
- Geben Sie unter Anmeldeinformationen die Azure Abonnement, Azure Key Vault Verbindung und den Namen des Geheimnisses ein.
- Wählen Sie Senden aus, um die Verbindungseinrichtung abzuschließen.
Tipp
Wenn Sie nicht über alle erforderlichen Informationen verfügen, wählen Sie Als Entwurf speichern aus, um später fortzufahren, wenn Sie über die restlichen Informationen zum Abschließen der Verbindungseinrichtung verfügen.
In dieser Abbildung wird veranschaulicht, wie Sie eine Verbindung erstellen:
Datenqualitätsüberprüfung
Nachdem Sie die Verbindungseinrichtung abgeschlossen haben, folgen Sie der Datenqualitätsprofilerstellung und -überprüfung von Dokumenten, um die Datenqualität von Oracle und SQL Server lokalen Datenquellen zu messen und zu überwachen.
- Übersicht über die Datenqualität
- Unterstützte Datenquellen
- Einrichten einer Datenquellenverbindung
- Überprüfung der Qualität der Datenprodukte
- Überprüfung der Datenassetqualität
- Inkrementelle Datenqualitätsüberprüfung
Hochverfügbarkeit und Skalierbarkeit
Weisen Sie mehrere Knoten im Kubernetes-Cluster für Hochverfügbarkeit zu, indem Sie die Knotenauswahl während der Installation der von Kubernetes unterstützten selbstgehosteten Integration Runtime verwenden. Zu den Vorteilen mehrerer Knoten gehören:
Höhere Verfügbarkeit der selbstgehosteten Integration Runtime, sodass sie kein Single Point of Failure für Überprüfungen ist.
Mehr gleichzeitige Überprüfungen. Jeder Knoten kann viele Überprüfungsausführungen gleichzeitig verarbeiten. Sie können Knoten des Kubernetes-Clusters manuell aufskalieren, wenn Sie mehr gleichzeitige Überprüfungen benötigen.
Beim Überprüfen einiger Quellen wie Azure Blob, Azure Data Lake Storage Gen2 und Azure Files kann jede Überprüfungsausführung mehrere Knoten verwenden, um die Überprüfungsleistung zu steigern. Bei anderen Quellen werden Überprüfungen nur auf einem der Knoten ausgeführt.
Sie können die Funktionen der von Kubernetes unterstützten selbstgehosteten Integration Runtime aktualisieren, indem Sie Knoten des Kubernetes-Clusters manuell hoch- oder herunterskalieren.
Hinweis
Sie müssen alle erforderlichen Treiber für die Überprüfung auf jedem neuen Knoten hochladen.
Netzwerkanforderung
| Domänenname | Ausgehender Port | Beschreibung |
|---|---|---|
Öffentliche Cloud: <tenantID>-api.purview-service.microsoft.com Azure Government: <tenantID>-api.purview-service.microsoft.us China: <tenantID>-api.purview-service.microsoft.cn |
443 | Erforderlich, um eine Verbindung mit dem Microsoft Purview-Dienst herzustellen. Wenn Sie private Microsoft Purview-Endpunkte verwenden, deckt der private Kontoendpunkt diesen Endpunkt ab. |
Öffentliche Cloud: <purview_account>.purview.azure.com Azure Government: <purview_account>.purview.azure.us China: <purview_account>.purview.azure.cn |
443 | Erforderlich, um eine Verbindung mit dem Microsoft Purview-Dienst herzustellen. Wenn Sie private Microsoft Purview-Endpunkte verwenden, deckt der private Kontoendpunkt diesen Endpunkt ab. |
| mcr.microsoft.com | 443 | Erforderlich zum Herunterladen von Bildern. |
| *.data.mcr.microsoft.com | 443 | Erforderlich zum Herunterladen von Bildern. |