Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Hinweis
Die Open-Source-Version von Hyperopt wird nicht mehr gepflegt.
Hyperopt ist nicht in Databricks Runtime für Maschinelles Lernen nach 16.4 LTS ML enthalten. Azure Databricks empfiehlt, entweder Optuna- für die Optimierung mit einem einzelnen Knoten oder RayTune- für eine ähnliche Erfahrung wie die veraltete verteilte Hyperparameteroptimierungsfunktion von Hyperopt zu verwenden. Erfahren Sie mehr über die Verwendung von RayTune- in Azure Databricks.
Dieses Beispielnotizbuch zeigt, wie Sie mithilfe von Hyperopt mit SparkTrials das Hyperparameter-Tuning von einer einzelnen Maschine auf einen Azure Databricks-Cluster skalieren können. Wenn Sie einen scikit-learn SVM-Klassifizierer für das Iris-Dataset optimieren, erstellen Sie zuerst einen Einzelcomputerworkflow fmin() , und parallelisieren Sie ihn dann über Spark-Worker hinweg, wobei MLflow automatisch jede Testversion nachverfolgt.
Importieren erforderlicher Pakete und Laden des Datasets
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
from hyperopt import fmin, tpe, hp, SparkTrials, STATUS_OK, Trials
# If you are running Databricks Runtime for Machine Learning, `mlflow` is already installed and you can skip the following line.
import mlflow
# Load the iris dataset from scikit-learn
iris = iris = load_iris()
X = iris.data
y = iris.target
Teil 1: Hyperopt-Workflow mit Einzel-Computer
Hier sind die Schritte in einem Hyperopt-Workflow:
- Definieren Sie eine Funktion, die minimiert werden soll.
- Definieren Sie einen Suchbereich über Hyperparameter.
- Wählen Sie einen Suchalgorithmus aus.
- Führen Sie den Optimierungsalgorithmus mit Hyperopt
fmin()aus.
Weitere Informationen finden Sie in der Hyperopt-Dokumentation.
Definieren einer Funktion, die minimiert werden soll
In diesem Beispiel wird ein Unterstützungsvektorcomputerklassifizierer verwendet. Ziel ist es, den besten Wert für den Regularisierungsparameter Czu finden.
Der großteil des Codes für einen Hyperopt-Workflow befindet sich in der objektiven Funktion. In diesem Beispiel wird der Unterstützungsvektorklassifizierer von scikit-learn verwendet.
Wenn Ihr Cluster Databricks Runtime 11.3 ML verwendet, bearbeiten Sie den Unterstützungsvektorklassifizierer, um ein Positionsargument zu verwenden. clf = SVC(C)
def objective(C):
# Create a support vector classifier model
clf = SVC(C=C)
# Use the cross-validation accuracy to compare the models' performance
accuracy = cross_val_score(clf, X, y).mean()
# Hyperopt tries to minimize the objective function. A higher accuracy value means a better model, so you must return the negative accuracy.
return {'loss': -accuracy, 'status': STATUS_OK}
Definieren des Suchbereichs über Hyperparameter
Ausführliche Informationen zum Definieren eines Suchbereichs und Parameterausdrücke finden Sie in den Hyperopt-Dokumenten .
search_space = hp.lognormal('C', 0, 1.0)
Auswählen eines Suchalgorithmus
Die beiden wichtigsten Optionen sind:
-
hyperopt.tpe.suggest: Tree of Parzen Estimators, ein bayesischer Ansatz, der iterativ und adaptiv neue Hyperparametereinstellungen basierend auf früheren Ergebnissen auswählt. -
hyperopt.rand.suggest: Zufällige Suche, ein nicht adaptiver Ansatz, der beispielhaft über den Suchraum operiert.
algo=tpe.suggest
Ausführen des Optimierungsalgorithmus mit Hyperopt fmin()
Legen Sie max_evals die maximale Anzahl von Punkten im Hyperparameterbereich fest, um zu testen, d. h. die maximale Anzahl von Modellen, die angepasst und ausgewertet werden sollen.
argmin = fmin(
fn=objective,
space=search_space,
algo=algo,
max_evals=16)
# Print the best value found for C
print("Best value found: ", argmin)
Teil 2: Verteilte Optimierung mit Apache Spark und MLflow
Um die Optimierung zu verteilen, fügen Sie ein weiteres Argument hinzu: fmin()eine Trials Klasse mit dem Namen SparkTrials.
SparkTrials akzeptiert zwei optionale Argumente:
-
parallelism: Anzahl der Modelle, die gleichzeitig angepasst und ausgewertet werden sollen. Der Standardwert ist die Anzahl der verfügbaren Spark-Aufgabenplätze. -
timeout: Maximale Zeit (in Sekunden), diefmin()ausgeführt werden kann. Der Standardwert ist kein maximales Zeitlimit.
In diesem Beispiel wird die sehr einfache Zielfunktion verwendet, die in Cmd 7 definiert ist. In diesem Fall wird die Funktion schnell ausgeführt, und der Aufwand beim Starten der Spark-Aufträge dominiert die Berechnungszeit, sodass die Berechnungen für den verteilten Fall mehr Zeit in Anspruch nehmen. Bei typischen realen Problemen ist die Zielfunktion komplexer, und die Berechnungsverteilung mittels SparkTrails ist schneller als die Abstimmung auf einer einzelnen Maschine.
Die automatische MLflow-Nachverfolgung ist standardmäßig aktiviert. Um sie zu verwenden, rufen Sie mlflow.start_run() vor dem Aufrufen fmin() auf, wie im Beispiel gezeigt.
from hyperopt import SparkTrials
# To display the API documentation for the SparkTrials class, uncomment the following line.
# help(SparkTrials)
spark_trials = SparkTrials()
with mlflow.start_run():
argmin = fmin(
fn=objective,
space=search_space,
algo=algo,
max_evals=16,
trials=spark_trials)
# Print the best value found for C
print("Best value found: ", argmin)
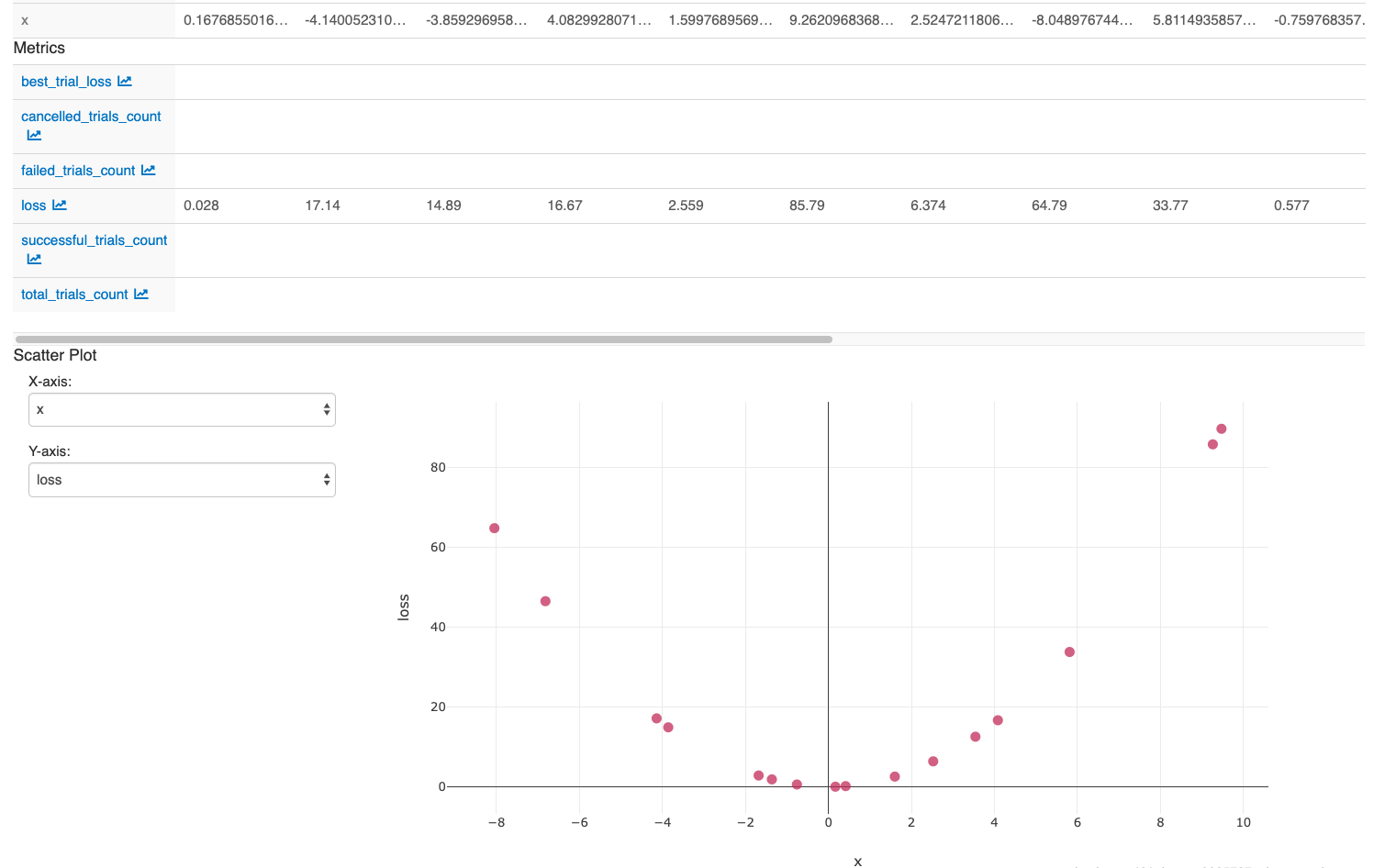
Um das dem Notizbuch zugeordnete MLflow-Experiment anzuzeigen, klicken Sie in der Notizbuchkontextleiste oben rechts auf das Symbol "Experiment ". Dort können Sie alle Läufe einsehen. Um die Ausführungen in der MLflow-UI anzuzeigen, klicken Sie ganz rechts neben Experimentläufe auf das Symbol.
So untersuchen Sie den Effekt der Optimierung C:
- Wählen Sie die resultierenden Ausführungen aus, und klicken Sie auf "Vergleichen".
- Wählen Sie im Punktdiagramm C für die X-Achse und Verlust für die Y-Achse aus.
Nachdem Sie die Aktionen in der letzten Zelle des Notebooks ausgeführt haben, sollte die MLflow-Benutzeroberfläche Folgendes anzeigen: