Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Wenn Sie neu bei Azure Data Factory sind, lesen Sie Einführung in Azure Data Factory.
In diesem Lernprogramm lernen Sie bewährte Methoden kennen, die beim Schreiben von Dateien in ADLS Gen2 oder Azure Blob Storage mithilfe von Datenflüssen angewendet werden können. Sie benötigen Zugriff auf ein Azure Blob Storage Konto oder Azure Data Lake Store Gen2-Konto zum Lesen einer Parkettdatei und anschließendes Speichern der Ergebnisse in Ordnern.
Voraussetzungen
- Azure-Abonnement. Wenn Sie kein Azure-Abonnement haben, erstellen Sie ein free Azure Konto, bevor Sie beginnen.
- Azure Speicherkonto. Sie verwenden den ADLS-Speicher als Quelldatenspeicher und Senkendatenspeicher. Wenn Sie nicht über ein Speicherkonto verfügen, lesen Sie Erstellen eines Azure-Speicherkontos, um die Schritte zur Erstellung eines solchen Kontos zu erfahren.
Bei den Schritten in diesem Tutorial wird davon ausgegangen, dass Sie
Erstellen einer Data Factory
In diesem Schritt erstellen Sie eine Data Factory und öffnen die Data Factory-Benutzeroberfläche, um eine Pipeline in der Data Factory zu erstellen.
Öffnen Sie Microsoft Edge oder Google Chrome. Derzeit wird data Factory UI nur in den Webbrowsern Microsoft Edge und Google Chrome unterstützt.
Wählen Sie im Menü auf der linken Seite Ressource erstellen>Integration>Data Factory aus.
Geben Sie auf der Seite Neue Data Factory unter Name den Namen ADFTutorialDataFactory ein.
Wählen Sie das Azure Abonnement aus, in dem Sie die Data Factory erstellen möchten.
Führen Sie unter Ressourcengruppe einen der folgenden Schritte aus:
a) Wählen Sie Use existing und dann eine vorhandene Ressourcengruppe aus der Dropdownliste aus.
b. Wählen Sie Neu erstellen, und geben Sie den Namen einer Ressourcengruppe ein. Weitere Informationen zu Ressourcengruppen finden Sie unter Ressourcengruppen zum Verwalten Ihrer Azure Ressourcen.
Wählen Sie unter Version die Option V2.
Wählen Sie unter Standort einen Standort für die Data Factory aus. In der Dropdownliste werden nur unterstützte Standorte angezeigt. Datenspeicher (z. B. Azure Storage und SQL-Datenbank) und Berechnungen (z. B. Azure HDInsight), die von der Datenfactory verwendet werden, können sich in anderen Regionen befinden.
Klicken Sie auf Erstellen.
Nach Abschluss der Erstellung wird der Hinweis im Benachrichtigungscenter angezeigt. Wählen Sie Zu Ressource wechseln aus, um zur Data Factory-Seite zu navigieren.
Wählen Sie Author & Monitor, um die Data Factory UI in einer separaten Registerkarte zu starten.
Erstellen einer Pipeline mit einer Datenflussaktivität
In diesem Schritt erstellen Sie eine Pipeline mit einer Datenflussaktivität.
Wählen Sie auf der Startseite von Azure Data Factory Orchestrate aus.
Geben Sie auf der Registerkarte Allgemein der Pipeline DeltaLake für den Namen der Pipeline ein.
Setzen Sie auf der oberen Leiste der Factory den Schieberegler Datenfluss debuggen auf „Ein“. Der Debugmodus ermöglicht das interaktive Testen von Transformationslogik mit einem aktiven Spark-Cluster. Data Flow-Cluster benötigen 5 bis 7 Minuten zum Aufwärmen, und es wird empfohlen, dass die Benutzer zuerst das Debuggen aktivieren, wenn sie eine Data Flow-Entwicklung durchführen möchten. Weitere Informationen finden Sie unter Debugmodus.
Erweitern Sie im Bereich Aktivitäten das Accordion-Element Verschieben und transformieren. Ziehen Sie die Datenfluss-Aktivität per Drag & Drop aus dem Bereich auf die Pipelinecanvas.
Erstellen von Transformationslogik im Datenfluss-Arbeitsbereich
Sie verwenden alle Quelldaten (in diesem Tutorial wird eine Parquet-Dateiquelle verwendet) sowie eine Senkentransformation, um die Daten mithilfe der effektivsten Mechanismen für Data Lake ETL im Parquet-Format bereitzustellen.

Ziele des Tutorials
- Auswählen eines Quelldatasets in einem neuen Datenfluss 1; Verwenden von Datenflüssen zum effektiven Partitionieren Ihres Senkendatasets
- Speichern Sie Ihre partitionierten Daten in ADLS Gen2 Lake-Ordnern
Starten Sie mit einer leeren Datenfluss-Leinwand
Zunächst richten Sie die Datenflussumgebung für jeden der unten beschriebenen Mechanismen zum Bereitstellen der Daten in ADLS Gen2 ein:
- Klicken Sie auf die Quelltransformation.
- Klicken Sie im unteren Bereich neben dem Dataset auf die neue Schaltfläche.
- Wählen Sie ein Dataset aus, oder erstellen Sie ein neues. Für diese Demo werden wir ein Parquet-Datensatz namens "Benutzerdaten" verwenden.
- Fügen Sie eine "Derived Column"-Transformation hinzu. Damit werden die gewünschten Ordnernamen dynamisch festgelegt.
- Fügen Sie eine Senkentransformation hinzu.
Hierarchische Ordnerausgabe
Es ist üblich, eindeutige Werte in Ihren Daten zu verwenden, um Ordnerhierarchien zum Partitionieren Ihrer Daten im Lake zu erstellen. Dies ist eine optimale Methode zum Organisieren und Verarbeiten von Daten im Lake und in Spark (die Compute-Engine hinter Datenflüssen). Es fallen jedoch geringe Leistungskosten an, um Ihre Ausgabe auf diese Weise zu organisieren. Mit diesem Mechanismus in der Senke wird eine geringfügige Verringerung der Gesamtleistung der Pipeline erwartet.
- Wechseln Sie zurück zum Datenfluss-Designer, und bearbeiten Sie den oben erstellten Datenfluss. Klicken Sie auf die Senkentransformation.
- Klicken Sie auf „Optimieren“ > „Partitionierung festlegen“ > „Schlüssel“.
- Wählen Sie die Spalte(n) aus, die Sie zum Festlegen Ihrer hierarchischen Ordnerstruktur verwenden möchten.
- Beachten Sie, dass im folgenden Beispiel Jahr und Monat als Spalten für die Ordnerbenennung verwendet werden. Das Ergebnis sind Ordner in der Form
releaseyear=1990/month=8. - Wenn Sie auf die Datenpartitionen in einer Datenflussquelle zugreifen, zeigen Sie nur auf den Ordner der obersten Ebene oberhalb von
releaseyearund verwenden ein Platzhaltermuster für jeden nachfolgenden Ordner. Beispiel:**/**/*.parquet - Wenn Sie die Datenwerte bearbeiten möchten oder synthetische Werte für Ordnernamen generiert werden müssen, verwenden Sie die Transformation für abgeleitete Spalten, um die Werte zu erstellen, die Sie in Ihren Ordnernamen verwenden möchten.

Benennen Sie den Ordner als Datenwerte
Eine etwas leistungsstärkere Senkentechnik für Lake Data mithilfe von ADLS Gen2, die nicht den gleichen Vorteil wie die Schlüssel-Wert-Partitionierung bietet, ist Name folder as column data. Während der Schlüsselpartitionierungsstil der hierarchischen Struktur Ihnen die Verarbeitung von Datenslices erleichtert, handelt es sich bei dieser Technik um eine vereinfachte Ordnerstruktur, mit der Daten schneller geschrieben werden können.
- Wechseln Sie zurück zum Datenfluss-Designer, und bearbeiten Sie den oben erstellten Datenfluss. Klicken Sie auf die Senkentransformation.
- Klicken Sie auf „Optimieren“ > „Partitionierung festlegen“ > „Aktuelle Partitionierung verwenden“.
- Klicken Sie auf „Einstellungen“ > und benennen Sie den Ordner als Spaltendaten.
- Wählen Sie die Spalte aus, die Sie zum Generieren von Ordnernamen verwenden möchten.
- Wenn Sie die Datenwerte bearbeiten möchten oder synthetische Werte für Ordnernamen generiert werden müssen, verwenden Sie die Transformation für abgeleitete Spalten, um die Werte zu erstellen, die Sie in Ihren Ordnernamen verwenden möchten.
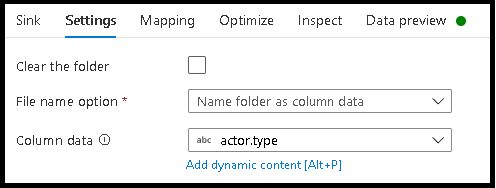
Datei als Datenwerte benennen
Die in den obigen Tutorials aufgeführten Techniken sind gute Anwendungsfälle zum Erstellen von Ordnerkategorien in Ihrem Data Lake. Das standardmäßige Dateibenennungsschema, das von diesen Techniken verwendet wird, ist die Spark-Executor-Job-ID. Manchmal möchten Sie möglicherweise den Namen der Ausgabedatei in einer Datenflusstextsenke festlegen. Diese Technik wird nur für die Verwendung mit kleinen Dateien empfohlen. Das Zusammenführen von Partitionsdateien in eine einzelne Ausgabedatei ist ein zeitintensiver Prozess.
- Wechseln Sie zurück zum Datenfluss-Designer, und bearbeiten Sie den oben erstellten Datenfluss. Klicken Sie auf die Senkentransformation.
- Klicken Sie auf „Optimieren“ > „Partitionierung festlegen“ > „Einzelne Partition“. Es ist diese Anforderung einer einzelnen Partition, die einen Engpass im Ausführungsprozess verursacht, wenn Dateien zusammengeführt werden. Diese Option wird nur für kleine Dateien empfohlen.
- Klicken Sie auf "Einstellungen" > und benennen Sie die Datei nach den Spaltendaten.
- Wählen Sie die Spalte aus, die Sie zum Generieren von Dateinamen verwenden möchten.
- Wenn Sie die Datenwerte bearbeiten möchten oder synthetische Werte für Dateinamen generiert werden müssen, verwenden Sie die Transformation für abgeleitete Spalten, um die Werte zu erstellen, die Sie in Ihren Dateinamen verwenden möchten.
Zugehöriger Inhalt
Weitere Informationen zu Datenflusssenken