Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel hilft Ihnen bei der Problembehandlung allgemeiner Szenarien in Durable Functions-Apps. Suchen Sie Ihr Symptom in der folgenden Liste, und führen Sie die verknüpften Schritte aus, um das Problem zu diagnostizieren und zu beheben.
Häufige Symptome
- Die Orchestrierung bleibt im Status "Ausstehend" hängen
- Orchestrierungen beginnen nach langer Verzögerung
- Die Orchestrierung bleibt im Zustand "Ausführen" hängen
- Die Orchestrierung dauert länger als erwartet
- Verbindungsfehler im Verbrauchsplan
Informationen zu KQL-Diagnoseabfragen, die Sie in Application Insights ausführen können, finden Sie unter Sample KQL-Abfragen für Durable Functions Diagnose.
Die Orchestrierung bleibt im Status Pending hängen.
Wenn Sie eine Orchestrierung starten, wird eine "Start"-Nachricht in eine interne Warteschlange geschrieben, die von der Durable Extension verwaltet wird, und der Status der Orchestrierung wird auf "Ausstehend" gesetzt. Nachdem eine verfügbare App-Instanz die Orchestrierungsmeldung aufgenommen und erfolgreich verarbeitet hat, wechselt der Status in den Status "Ausgeführt" (oder in einen anderen Status ohne "Ausstehend").
Führen Sie zur Problembehandlung für Orchestrierungsinstanzen, die auf unbestimmte Zeit im Status „Ausstehend“ hängen bleiben, diese Schritte aus.
Überprüfen Sie, ob in den Durable Task Framework-Ablaufverfolgungen Warnungen oder Fehler für die betroffene Orchestrierungsinstanz-ID angezeigt werden. Verwenden Sie die Abfrage "Ablaufverfolgungsfehler" und "Warnungen " in Application Insights, um nach Fehlern im Zusammenhang mit Ihrer Instanz zu suchen.
Überprüfen Sie die Azure Storage Steuerelementwarteschlangen, um festzustellen, ob sich die "Startnachricht" der Orchestrierung noch in der Warteschlange befindet. Navigieren Sie im Azure-Portal zu Ihrem Speicherkonto, wählen Sie Queues aus, und suchen Sie nach Warteschlangen mit dem Präfix
control. Hintergrundinformationen zur Funktionsweise von Steuerelementwarteschlangen finden Sie in der Dokumentation zur Azure Storage Anbietersteuerungswarteschlange.Ändern Sie die Plattformkonfiguration Ihrer App auf 64 Bit. Orchestrierungen können manchmal nicht gestartet werden, da die App nicht genügend Arbeitsspeicher hat. Durch den Wechsel zu einem 64-Bit-Prozess kann die App mehr Gesamtspeicher zuweisen. Diese Änderung gilt nur für App Service Basic-, Standard-, Premium- und Elastic Premium-Pläne. Kostenlose oder Verbrauchspläne unterstützen keine 64-Bit-Prozesse.
Orchestrierungen beginnen nach langer Verzögerung
Normalerweise beginnen Orchestrierungen innerhalb weniger Sekunden, nachdem sie geplant wurden. Orchestrierungen können jedoch in bestimmten Fällen länger brauchen, um zu beginnen. Führen Sie zur Problembehandlung für Orchestrierungen, deren Start mehr als nur einige Sekunden dauert, diese Schritte aus.
Überprüfen Sie, ob die Verzögerung mit einer known limitation of the Azure Storage provider übereinstimmt, z. B. Partition rebalancing or timer-based polling intervals.
Überprüfen Sie, ob in den Durable Task Framework-Ablaufverfolgungen Warnungen oder Fehler für die betroffene Orchestrierungsinstanz-ID angezeigt werden. Verwenden Sie die Abfrage "Ablaufverfolgungsfehler" und "Warnungen " in Application Insights, um nach Fehlern im Zusammenhang mit Ihrer Instanz zu suchen.
Die Orchestrierung bleibt im Status Running hängen.
Wenn der Orchestrierungsstatus "Läuft" länger als erwartet anzeigt oder es scheinbar nicht mehr erfolgreich ist, wartet die Orchestrierung wahrscheinlich auf eine Aufgabe, die noch nicht abgeschlossen wurde. Beispielsweise könnte es auf einen dauerhaften Zeitgeber, eine Aktivitätsaufgabe oder ein externes Ereignis warten. Wenn geplante Vorgänge erfolgreich abgeschlossen wurden, aber die Orchestrierung noch nicht voranschreitet, besteht möglicherweise ein Problem, das verhindert, dass sie mit dem nächsten Schritt fortgefahren wird. Orchestrierungen in diesem Zustand werden oft als "hängen gebliebene Orchestrierungen" bezeichnet.
Führen Sie zur Problembehandlung für hängengebliebene Orchestrierungen diese Schritte aus:
Starten Sie die Funktions-App neu. Dieser Schritt kann hilfreich sein, wenn die Orchestrierung aufgrund eines vorübergehenden Fehlers oder eines Deadlocks in der App oder im Erweiterungscode hängen bleibt.
Überprüfen Sie die Azure Storage Kontosteuerungswarteschlangen, um festzustellen, ob Warteschlangen kontinuierlich wachsen. Verwenden Sie die Azure Storage Messagingabfrage in Application Insights, um Probleme bei der Entqueuierung von Orchestrierungsnachrichten zu identifizieren. Wenn sich das Problem nur auf eine einzelne Steuerelementwarteschlange auswirkt, kann es auf ein Problem in einer bestimmten App-Instanz hinweisen. In diesem Fall kann die Skalierung nach oben oder unten, um die fehlerhafte VM-Instanz zu deaktivieren, hilfreich sein.
Filtern Sie die Azure Storage Messagingabfrage Ergebnisse nach dem Warteschlangennamen als Partitions-ID, um nach Problemen im Zusammenhang mit dieser bestimmten Steuerelementwarteschlangenpartition zu suchen.
Überprüfen Sie die Dokumentation zur Versionsverwaltung für Durable Functions. Das Unterbrechen von Änderungen an In-Flight-Orchestrierungsinstanzen kann zu hängenden Orchestrierungen führen.
Die Orchestrierung dauert länger als erwartet
Schwere Datenverarbeitung, interne Fehler und unzureichende Rechenressourcen können dazu führen, dass Orchestrierungen langsamer als normal ausgeführt werden. Führen Sie die folgenden Schritte aus, um Probleme mit Orchestrierungen zu beheben, die länger dauern als erwartet:
Überprüfen Sie, ob in den Durable Task Framework-Ablaufverfolgungen Warnungen oder Fehler für die betroffene Orchestrierungsinstanz-ID angezeigt werden. Verwenden Sie die Abfrage "Ablaufverfolgungsfehler" und "Warnungen " in Application Insights, um nach Fehlern im Zusammenhang mit Ihrer Instanz zu suchen.
Wenn Ihre App das .NET In-Process-Modell verwendet, sollten Sie extended Sessions aktivieren. Erweiterte Sitzungen minimieren Ladevorgänge für den Verlauf, wodurch die Verarbeitung möglicherweise verlangsamt wird.
Überprüfen Sie Leistungs- und Skalierbarkeitsengpässe. Hohe CPU-Auslastung oder große Arbeitsspeicherauslastung kann zu Verzögerungen führen. Ausführliche Anleitungen finden Sie unter Performance und Skalierung in Durable Functions.
Beispiel-KQL-Abfragen für Durable Functions-Diagnose
Behandeln von Problemen durch Schreiben von benutzerdefinierten KQL-Abfragen in der für Ihre Azure Functions App konfigurierten Azure-Anwendung Insights-Instanz. Spaltendefinitionen, die in diesen Abfragen verwendet werden, finden Sie in der Spaltenreferenz.
Azure Storage-Nachrichtenübertragung
Wenn Sie den Standardanbieter Azure Storage verwenden, wird das gesamte Verhalten der Durable Functions von Azure-Storage-Warteschlangennachrichten gesteuert, und der gesamte Status im Zusammenhang mit einer Orchestrierung wird im Tabellenspeicher und Blob-Speicher gespeichert. Wenn Sie die Ablaufverfolgung des Durable Task Frameworks aktivieren, werden alle Azure Storage Interaktionen in Application Insights protokolliert. Diese Daten sind für das Debuggen von Ausführungs- und Leistungsproblemen von entscheidender Bedeutung.
Ab Version 2.3.0 der Durable Functions-Erweiterung können Sie diese Protokolle des Dauerhaften Aufgabenframeworks in Ihrer Application Insights-Instanz veröffentlichen, indem Sie Ihre Protokollierungskonfiguration in der Datei host.json aktualisieren. Weitere Informationen finden Sie im Artikel zur Protokollierung des Durable Task Framework.
Die folgende Abfrage prüft End-to-End-Azure Storage Interaktionen für eine bestimmte Orchestrierungsinstanz. Bearbeiten Sie start und orchestrationInstanceID, um nach Zeitbereich und Instanz-ID zu filtern.
let start = datetime(XXXX-XX-XXTXX:XX:XX); // edit this
let orchestrationInstanceID = "XXXXXXX"; //edit this
traces
| where timestamp > start and timestamp < start + 1h
| where customDimensions.Category == "DurableTask.AzureStorage"
| extend taskName = customDimensions["EventName"]
| extend eventType = customDimensions["prop__EventType"]
| extend extendedSession = customDimensions["prop__IsExtendedSession"]
| extend account = customDimensions["prop__Account"]
| extend details = customDimensions["prop__Details"]
| extend instanceId = customDimensions["prop__InstanceId"]
| extend messageId = customDimensions["prop__MessageId"]
| extend executionId = customDimensions["prop__ExecutionId"]
| extend age = customDimensions["prop__Age"]
| extend latencyMs = customDimensions["prop__LatencyMs"]
| extend dequeueCount = customDimensions["prop__DequeueCount"]
| extend partitionId = customDimensions["prop__PartitionId"]
| extend eventCount = customDimensions["prop__TotalEventCount"]
| extend taskHub = customDimensions["prop__TaskHub"]
| extend pid = customDimensions["ProcessId"]
| extend appName = cloud_RoleName
| extend newEvents = customDimensions["prop__NewEvents"]
| where instanceId == orchestrationInstanceID
| sort by timestamp asc
| project timestamp, appName, severityLevel, pid, taskName, eventType, message, details, messageId, partitionId, instanceId, executionId, age, latencyMs, dequeueCount, eventCount, newEvents, taskHub, account, extendedSession, sdkVersion
Ablaufverfolgungsfehler und Warnungen
Die folgende Abfrage sucht nach Fehlern und Warnungen für eine bestimmte Orchestrierungsinstanz. Geben Sie einen Wert für orchestrationInstanceID an.
let orchestrationInstanceID = "XXXXXX"; // edit this
let start = datetime(XXXX-XX-XXTXX:XX:XX);
traces
| where timestamp > start and timestamp < start + 1h
| extend instanceId = iif(isnull(customDimensions["prop__InstanceId"] ) , customDimensions["prop__instanceId"], customDimensions["prop__InstanceId"] )
| extend logLevel = customDimensions["LogLevel"]
| extend functionName = customDimensions["prop__functionName"]
| extend status = customDimensions["prop__status"]
| extend details = customDimensions["prop__Details"]
| extend reason = customDimensions["prop__reason"]
| where severityLevel >= 1 // to see all logs of severity level "Information" or greater.
| where instanceId == orchestrationInstanceID
| sort by timestamp asc
Steuerungswarteschlangen- und Partitions-ID-Protokolle
Die folgende Abfrage sucht nach allen Aktivitäten, die der Steuerungswarteschlange einer Instanz-ID (instanceID) zugeordnet sind. Geben Sie den Wert für die InstanceID in orchestrationInstanceID und die Startzeit der Abfrage in start.
let orchestrationInstanceID = "XXXXXX"; // edit this
let start = datetime(XXXX-XX-XXTXX:XX:XX); // edit this
traces // determine control queue for this orchestrator
| where timestamp > start and timestamp < start + 1h
| extend instanceId = customDimensions["prop__TargetInstanceId"]
| extend partitionId = tostring(customDimensions["prop__PartitionId"])
| where partitionId contains "control"
| where instanceId == orchestrationInstanceID
| join kind = rightsemi(
traces
| where timestamp > start and timestamp < start + 1h
| where customDimensions.Category == "DurableTask.AzureStorage"
| extend taskName = customDimensions["EventName"]
| extend eventType = customDimensions["prop__EventType"]
| extend extendedSession = customDimensions["prop__IsExtendedSession"]
| extend account = customDimensions["prop__Account"]
| extend details = customDimensions["prop__Details"]
| extend instanceId = customDimensions["prop__InstanceId"]
| extend messageId = customDimensions["prop__MessageId"]
| extend executionId = customDimensions["prop__ExecutionId"]
| extend age = customDimensions["prop__Age"]
| extend latencyMs = customDimensions["prop__LatencyMs"]
| extend dequeueCount = customDimensions["prop__DequeueCount"]
| extend partitionId = tostring(customDimensions["prop__PartitionId"])
| extend eventCount = customDimensions["prop__TotalEventCount"]
| extend taskHub = customDimensions["prop__TaskHub"]
| extend pid = customDimensions["ProcessId"]
| extend appName = cloud_RoleName
| extend newEvents = customDimensions["prop__NewEvents"]
) on partitionId
| sort by timestamp asc
| project timestamp, appName, severityLevel, pid, taskName, eventType, message, details, messageId, partitionId, instanceId, executionId, age, latencyMs, dequeueCount, eventCount, newEvents, taskHub, account, extendedSession, sdkVersion
Application Insights-Spaltenreferenz für Durable Functions Abfragen
In der folgenden Tabelle sind die Spalten aufgeführt, die von den vorherigen Abfragen und deren Beschreibungen projiziert wurden.
| Kolumne | Beschreibung |
|---|---|
| pid | Prozess-ID der Funktions-App-Instanz. Mit diesem Wert können Sie ermitteln, ob der Prozess während der Ausführung einer Orchestrierung neu gestartet wurde. |
| Aufgabenname | Der Name des protokollierten Ereignisses. |
| eventType | Der Nachrichtentyp, der in der Regel eine von einem Orchestrator ausgeführte Arbeit darstellt. Eine vollständige Liste der möglichen Werte und deren Beschreibungen finden Sie unter EventType.cs. |
| erweiterte Sitzung | Boolescher Wert, der angibt, ob erweiterte Sitzungen aktiviert sind. |
| Konto | Das von der App verwendete Speicherkonto. |
| details | Weitere Informationen zu einem bestimmten Ereignis, falls verfügbar. |
| instanceId | Die ID für eine bestimmte Orchestrierungs- oder Entitätsinstanz. |
| Nachrichten-ID | Die eindeutige Azure Storage-ID für eine bestimmte Queue-Nachricht. Dieser Wert wird am häufigsten in ReceivedMessage-, ProcessingMessage- und DeletingMessage-Ablaufverfolgungsereignissen angezeigt. Dieser Wert ist in SendingMessage-Ereignissen nicht vorhanden, da die Nachrichten-ID von Azure Storage nachdem die Nachricht gesendet wird, generiert wird. |
| Ausführungs-ID | Die ID der Orchestratorausführung, die sich bei jedem continue-as-new Aufruf ändert. |
| Alter | Die Anzahl der Millisekunden seit dem Einreihen der Nachricht. Große Zahlen deuten häufig auf Leistungsprobleme hin. Eine Ausnahme ist der Nachrichtentyp TimerFired, der abhängig von der Timerdauer einen hohen Age-Wert aufweisen kann. |
| latencyMs | Die Anzahl der Millisekunden, die für einen Speichervorgang benötigt wurden. |
| dequeueCount | Die Häufigkeit, mit der eine Nachricht abgefragt wird. Unter normalen Umständen ist dieser Wert immer 1. Wenn es mehr als eins ist, liegt möglicherweise ein Problem vor. |
| partitionId | Der Name der Warteschlange, die diesem Protokoll zugeordnet ist. |
| GesamtanzahlEreignisse | Die Anzahl der Verlaufsereignisse, die an der aktuellen Aktion beteiligt sind. |
| taskHub | Der Name des Task-Hubs. |
| newEvents | Eine durch Trennzeichen getrennte Liste von Verlaufsereignissen, die in die Tabelle "Verlauf" im Speicher geschrieben werden. |
Probleme bei der Verbindungsverwaltung im Verbrauchsplan
Apps, die im Azure Functions Verbrauchsplan ausgeführt werden, unterliegen Connection Limits. Häufige Symptome sind:
- Intermittierende Konnektivitätsfehler beim Aufrufen von Aktivitätsfunktionen oder externen Diensten.
- Orchestrierungen, die sporadisch beim Laden fehlschlagen.
- Socketausschöpfungsfehler in den Protokollen.
Um die Verbindungsnutzung zu reduzieren, verwenden HttpClientFactory oder freigegebene statische Clients, anstatt neue HttpClient Instanzen in jedem Funktionsaufruf zu erstellen. Ausführliche Anleitungen zu Verbindungspooling und bewährten Methoden finden Sie unter Manage connections in Azure Functions.
Allgemeine Tipps
Tipp
Stellen Sie vor dem Einstieg in bestimmte Problembehandlungsschritte sicher, dass Ihre App die neueste Durable Functions Erweiterungsversion verwendet. Meistens werden mit der neuesten Version bekannte Probleme abgemildert, die bereits von anderen Benutzern gemeldet wurden. Anweisungen zum Upgrade finden Sie unter Upgrade Durable Functions Erweiterungsversion.
Auf der Registerkarte Diagnose und Lösung von Problemen im Azure-Portal können Sie Probleme im Zusammenhang mit Ihrer Anwendung überwachen und diagnostizieren und mögliche Lösungen vorschlagen. Weitere Informationen finden Sie unter Azure Funktions-App-Diagnose.
Support für Durable Functions Probleme erhalten
Wenn Sie Ihr Problem mithilfe dieses Handbuchs nicht beheben können, können Sie ein Supportticket einreichen, indem Sie den Abschnitt Neue Supportanfrage im Blatt Support + Troubleshooting Abschnitt Ihrer Funktions-App-Seite im Azure Portal öffnen.
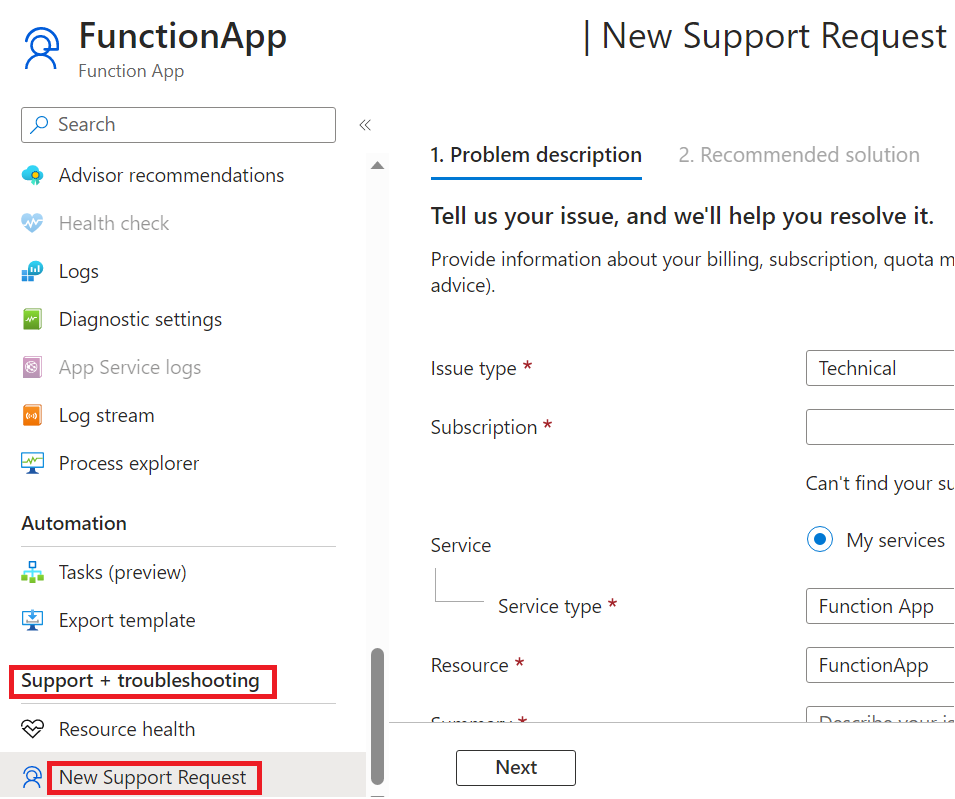
Öffnen Sie bei Fragen und Community-Support ein Problem in einem der folgenden GitHub Repos. Wenn Sie einen Fehler melden, schließen Sie Informationen wie betroffene Instanz-IDs, Zeitbereiche in UTC mit dem Problem, den Anwendungsnamen (sofern möglich) und die Bereitstellungsregion ein, um Untersuchungen zu beschleunigen.