Note
Du kan nu authorPrep data for AI funktioner både i Power BI-tjeneste og Power BI Desktop. Brugere kan consume disse funktioner overalt, hvor Copilot findes.
Værktøjsfunktioner
Hvilke funktioner har Power BI i øjeblikket, der hjælper mig med at forberede mine data til Copilot?
I dag tilbyder Power BI fire hovedværktøjsfunktioner til at konfigurere din model, så den er klar til naturlig sprogbehandling:
- AI-dataskemaer: Giver dig mulighed for at vælge et delmængde af et skema til Copilot forbrug.
- Verificerede svar: Et konfigureret svar, som en modelforfatter sætter, og som valideres for nøjagtighed og pålidelighed. Forfattere kan sætte specifikke visuelle elementer til Copilot til brug i et verificeret svar, når en bruger stiller et spørgsmål, der falder ind under den tildelte kategori.
- AI-instruktioner: Instruktioner, du kan sætte på din model for at give mere kontekst til dataene i modellen. De hjælper Copilot med at forstå, hvornår de skal fokusere på hvilke data, og hjælper Copilot med at forstå bestemte kortlægninger, som sprogbrugere kan bruge, når de interagerer med Copilot.
- Beskrivelser: Beskrivelser, der er angivet for tabeller og kolonner, for at give flere oplysninger om konteksten for dataene. Beskrivelser bruges kun i Data Analysis Expressions (DAX)-forespørgsler og Copilot-søgefunktioner.
I hvilken rækkefølge skal jeg implementere Copilot i Power BI-værktøjsfunktioner?
For at få mest muligt ud af Copilot i Power BI foreslår vi at implementere dets værktøjsfunktioner i følgende rækkefølge:
Definér AI-dataskemaet.
Start med at vælge de specifikke tabeller, felter og målinger, som Copilot skal referere til, når den besvarer dataspørgsmål.
Under modeludvikling kan du inkludere elementer, der ikke er relevante for slutbrugerforespørgsler. Når du indsnævrer skemaet, hjælper du Copilot med at fokusere på de mest meningsfulde dele af din model, hvilket reducerer tvetydighed. Denne praksis er vigtig for store datasæt, der har overlappende eller lignende navngivne felter.
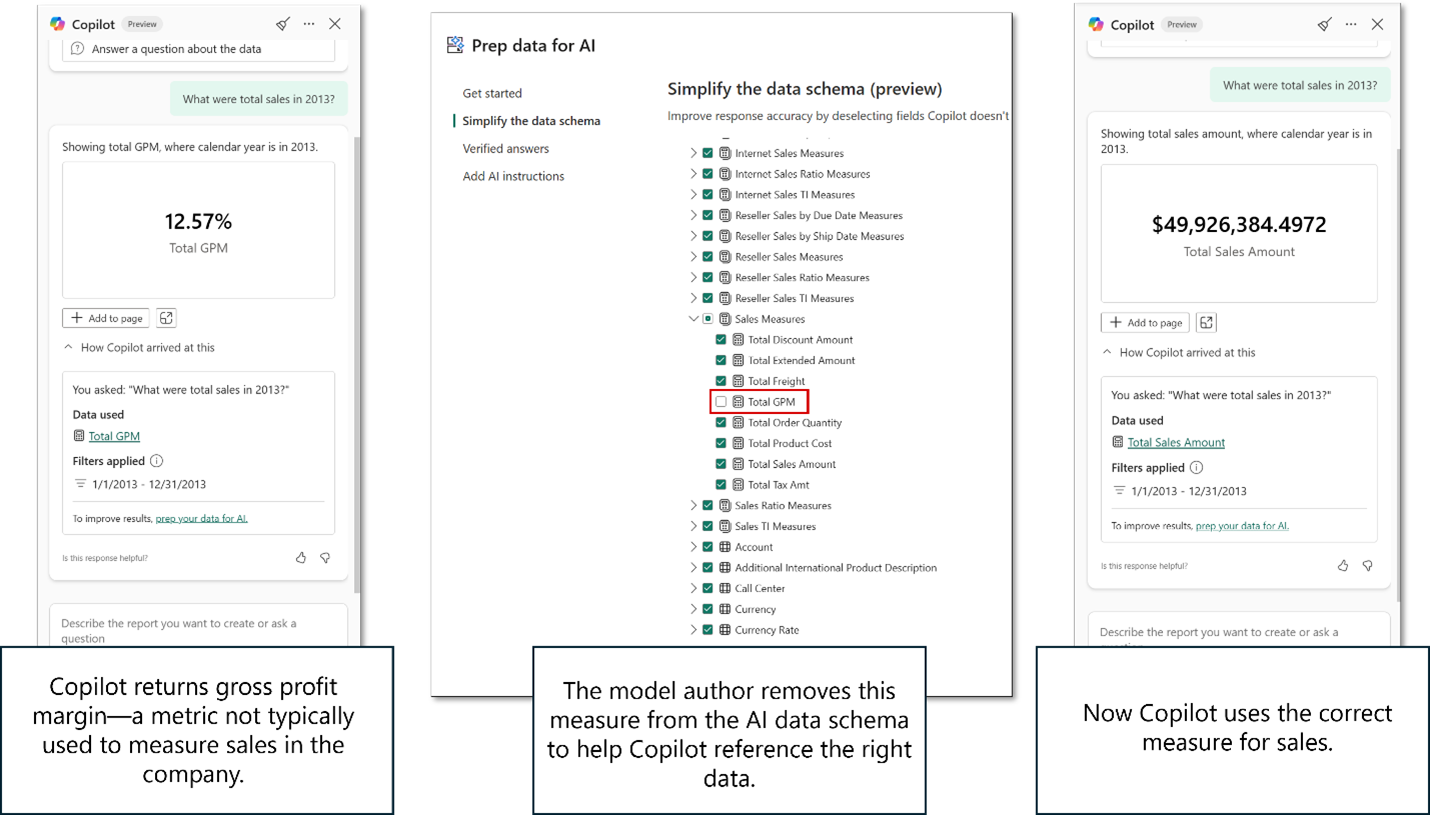
Her er et eksempel på, hvordan AI-dataskemaer kan hjælpe Copilot med at fokusere på de rigtige data:
Når du bruger hele skemaet, ved Copilot ikke altid, hvad brugeren mener, når de siger sales. I dette tilfælde returnerede Copilot bruttoprofitmargin (GPM), som er en legitim fortolkning af salg, men ikke den måleenhed, dette team typisk bruger til at analysere salg.
Modelforfatteren bruger funktionen Prep data for AI og fjerner Total GPM-målet fra skemaet, der sendes til Copilot.
Nu, når brugeren stiller det samme spørgsmål, har Copilot mere klarhed over, hvor svaret skal hentes, og fortolker salg korrekt ud fra teamets definition og måling.
Skab verificerede svar.
Sæt verificerede svar op på almindelige eller nuancerede spørgsmål, som brugere måtte stille.
Vælg et visuelt svar, og vælg derefter Opret verificeret svar. Tilføj derefter triggersætninger, der afspejler, hvordan brugerne sandsynligvis vil formulere deres spørgsmål. Når brugere indtaster en matchende eller lignende frase i Copilot, returnerer den den betroede visuelle version. Denne proces hjælper med at sikre ensartede og højkvalitets svar på tværs af rapporter.
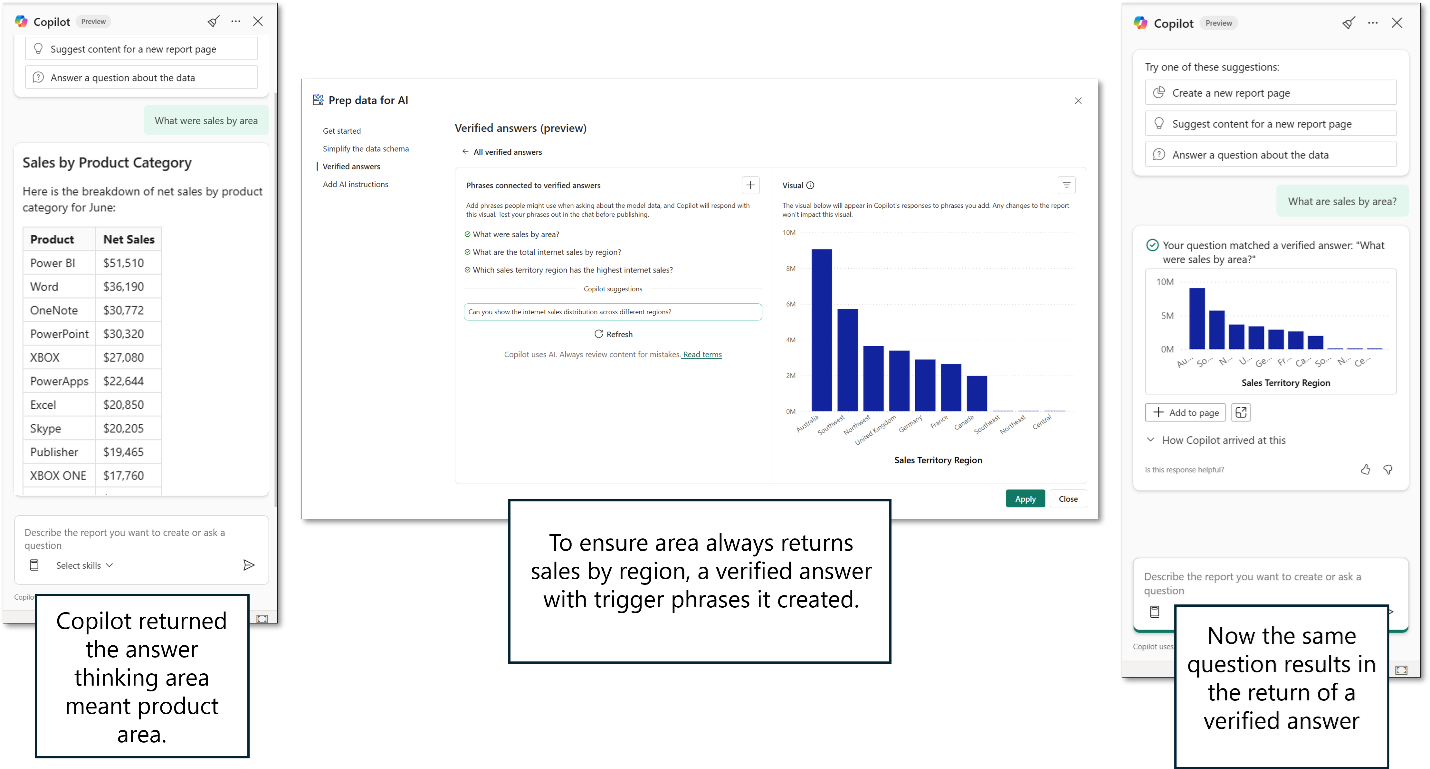
I følgende eksempel vises fordelen ved et bekræftet svar. Brugeren spørger efter salg efter område. Copilot fortolker area som product area og returnerer en liste over produkter og deres salg. Brugeren ledte dog efter salg efter region eller placering.
Modelforfatteren fastsætter et verificeret svar ved at bruge en visuel løsning, der inkluderer salg efter region. Derefter inkluderer forfatteren trigger-sætninger, som, når en bruger spørger dem, skal give dette specifikke visuelle svar.
Når brugeren nu spørger efter salg efter område, returnerer Copilot det verificerede svar, som modelforfatteren godkender.
Tilføj AI-instruktioner.
Efter du har defineret skemaet og bekræftet svarene, kan du bruge AI-instruktioner til at styre Copilot' adfærd på modelniveau.
Instruktioner hjælper med at klarlægge forretningslogik, kortlægge brugerterminologi til modelfelter og fortælle Copilot, hvordan de skal fortolke eller analysere specifikke typer data. De er nyttige, fordi de giver kontekst, som Copilot ikke selv ville udlede.
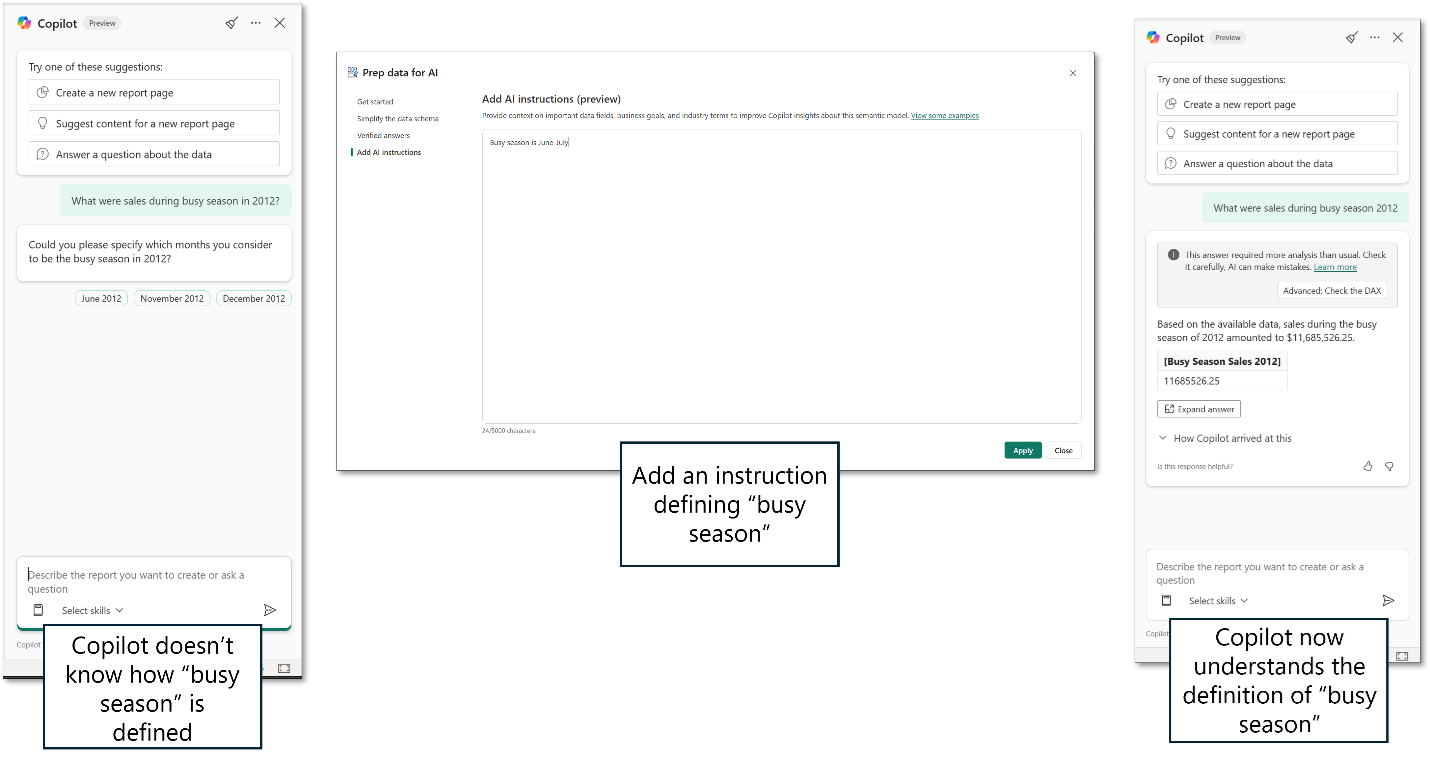
Følgende eksempel viser, hvordan du kan bruge AI-instruktioner til at give mere kontekst til Copilot. Brugeren spørger om salg i den travle sæson i 2012. Optaget sæson er et veldefineret, almindeligt brugt udtryk i denne organisation. Den semantiske model har dog ingen indikation af dette begreb nogen steder. Modelforfatteren sætter en instruktion, der definerer travl sæson som juni til august.
Når brugeren stiller spørgsmålet om salg i travl sæson, forstår Copilot dette definerede begreb og kan give svaret.
Føj beskrivelser til tabeller og kolonner.
Beskrivelser giver ekstra metadata, som Copilot kan bruge til at forstå din model.
Selvom beskrivelser i øjeblikket kun påvirker nogle Copilot-adfærd, vil de spille en større rolle i fremtidige kapaciteter. At tilføje dem nu hjælper med at opbygge et stærkt fundament for langsigtet succes med naturlige sproginteraktioner i Power BI.



Kan jeg oprette værktøjer på en rapport i stedet for på modellen?
I dag er værktøjs- og konfigurationsfunktioner kun tilgængelige på modellen. Konfiguration af forskellige rapporter, der er bygget ud fra den samme model, understøttes endnu ikke. Skemaet, verificerede svar, instruktioner og beskrivelser er sat på den semantiske model, men ikke på rapporten.
Når jeg forbereder mine data til Copilot, hvilke funktioner påvirkes?
Se følgende tabel:
| Capability | AI-dataskemaer | Bekræftede svar | INSTRUKTIONER TIL KUNSTIG INTELLIGENS | Descriptions |
|---|---|---|---|---|
| Få en oversigt over min rapport | No | No | Yes | No |
| Stil et spørgsmål om visualiseringerne i min rapport | No | Yes | Yes | No |
| Stil et spørgsmål om min semantiske model | Yes | Yes | Yes | No |
| Opret en rapportside | No | No | Yes | No |
| Search | No | Yes | No | Yes |
| DAX-forespørgsel | No | No | Yes | Yes |
Vide, hvilken funktion der skal bruges
Jeg prøver at få Copilot til at vælge det rigtige felt. Hvilken funktion skal jeg bruge?
Definér dit AI-dataskema.
Fjern alle tabeller, kolonner eller felter, der er irrelevante for brugernes behov. Denne handling hjælper Copilot med at fokusere på de mest relevante dele af din model og sikrer, at den vælger de rigtige felter, når den besvarer forespørgsler.
Brug verificerede svar som visuelle elementer i rapporter.
Hvis Copilot kan bruge et visuelt svar i din rapport til at udlede et svar på et spørgsmål, så lav et verificeret svar. Denne praksis hjælper med at sikre, at Copilot konsekvent returnerer det korrekte billede, når brugere stiller spørgsmål med specifikke triggersætninger.
Tilpas instruktionerne til specifikke felter.
Efter du har sat skemaet og verificeret svarene, kan du bruge AI-instruktioner til at guide Copilot, når du vælger bestemte felter. Vi anbefaler, at du bruger instruktioner til finjustering og avancerede scenarier, efter at andre forberedelsesdata for AI-funktioner er sat. Ved at bruge denne sekvens af trin kan du hjælpe med at sikre, at Copilot returnerer de mest nøjagtige og kontekstuelt relevante resultater til brugerne, guidet af din models struktur og dine definerede instruktioner.
Jeg prøver at få Copilot til at forstå det begreb, jeg bruger. Hvilken funktion skal jeg bruge?
Hvis Copilot har svært ved at forstå et begreb, der altid har det samme korrekte element at referere til i din model, kan du give et alternativt navn via AI-instruktioner.
For eksempel, hvis dit team kalder dem, der sælger dine produkter, for closers, bør du angive en reference i dine AI-instruktioner. Sæt sælgere til også at blive kendt som closers.
Jeg prøver at få Copilot til at forstå vilkår med betingelser eller grupperinger. Hvilken funktion skal jeg bruge?
Hvis dit hold bruger bestemte termer, som ikke er et præcist 1:1 match med tabeller eller felter i din model, kan du bruge AI-instruktioner til at hjælpe med at tydeliggøre forskellige elementer med bestemte betingelser eller grupperinger.
For eksempel kan et salgsteam klassificere enhver, der sælger mere end 100% af deres mål i en given måned, som højtydende. De bør give følgende instruktioner til Copilot:
Højtydende sælger betyder en sælger, der opfylder 100% eller mere af deres månedlige mål.
Nu, når en bruger spørger: "Hvem var de højeste præsterende sidste måned?" ved Copilot præcis, hvad højtydende betyder i dit team og din organisation.
I et andet eksempel kan en organisation klassificere sæsoner. Dit hold kan kalde januar til maj for lav sæson. Juni til september kan være travl sæson. Oktober til december kan være standardsæsonen.
Inden for AI-instruktioner kan du sætte følgende definitioner:
- Langsom sæson betyder januar til maj.
- Travl sæson betyder juni til september.
- Standardsæson betyder oktober til december.
Nu, når en bruger spørger: "Hvad var det samlede salg i travl sæson sidste år?" forstår Copilot, hvilken tidsramme brugeren mener med travl sæson.
Jeg prøver at få Copilot til at svare korrekt på de mest almindelige spørgsmål. Hvilken funktion skal jeg bruge?
Forbrugere af din rapport og data stiller sandsynligvis nogle spørgsmål oftere. Du kan håndtere denne hændelse ved at anvende verificerede svar på din model. Påbegynd et verificeret svar ved at vælge en visuel løsning og sætte triggersætninger. Når en bruger spørger om emnet, returnerer Copilot information ved at bruge det tildelte billede.
For eksempel kan forbrugere af rapporten og modellen ofte spørge: "Hvilket produkt havde det højeste salg i sidste uge?" Du kan sætte et verificeret svar for at hjælpe Copilot med at forstå, hvor de kan finde de rette oplysninger. Denne metode hjælper forfattere og forbrugere med at stole på, at svaret er korrekt.
Jeg prøver at få Copilot til at returnere forskellige svar baseret på domæner eller brugergrupper. Hvilken funktion skal jeg bruge?
De funktioner, som de findes i dag, er begrænset til et bredt forbrug. Du kan i øjeblikket ikke oprette en ordliste baseret på forskellige grupper eller definere et begreb på to forskellige måder. For eksempel kan ingeniører definere forbrug som antal gange der klikkes, men produktchefer kan definere forbrug som betalende kunder i en given måned. Du kan ikke lige nu give brugen forskellige definitioner i samme model.
Hvorfor siger Copilot, at den ikke kan se et felt i min semantiske model, selvom det er en del af AI-skemaet?
I scenarier, hvor dit semantiske modelskema er for stort til, at Copilot kan gengive et svar, vil modellens skema blive reduceret, så Copilot kan forstå skemaet og generere et svar. Du kan se, hvornår dette sker, ved at downloade Copilot Diagnostics og tjekke for "AgentSchemaReduced" i advarslerne.
Klargør data til kunstig intelligens
Jeg får en fejl, der siger: "Copilot synkroniserer i øjeblikket med datamodellen." Hvad betyder dette?
For at Copilot kan præstere bedst, er det afgørende, at den forstår de underliggende data i den semantiske model. En måde, Copilot i Power BI forsøger at forstå de underliggende data på, er ved at indeksere den semantiske model for nøjagtigt at søge efter relevante værdier, der kan matches på. Denne proces gør det muligt for Copilot effektivt at besvare spørgsmål baseret på brugerens prompt.
Overvej et datasæt relateret til turisme på Hawaii. For at besvare spørgsmål som: "Hvordan påvirkede vejret turistbesøg på Maui?" skal Copilot forstå, at Maui er en instansværdi i den semantiske model i kolonnen Island name i tabellen Island.
For at Copilot effektivt kan søge i disse instansværdier, indekseres den semantiske model, når Power BI Q& A er aktiveret. Den reindekseres, når Power BI registrerer ændringer i modellen.
Frekvens for modelindeksering
Indeksering udføres for alle modeller, hvor Q&A-indstillingen er aktiveret.
Note
Q&A-indstillingen er slået til som standard for import- og Direct Lake-modeller . Du kan finde flere detaljer om denne indstilling i Q&A-indstillingsdokumentationen.
Gendexing sker, når en af følgende handlinger udføres:
- Til importmodeller :
- Modellen blev udgivet eller genudgivet til tjenesten.
- Modellen blev opdateret via manuel eller planlagt opdatering samt Copilot og Q& A blev brugt inden for de sidste 14 dage.
- For DirectQuery- og Direct Lake-modeller :
- Modellen blev udgivet eller genudgivet til tjenesten.
- Indekset er ældre end 24 timer, og Copilot og Q& A blev brugt inden for de sidste 14 dage.
Følgende besked i Copilot indikerer, at modellen i øjeblikket er i gang med indeksering. Beskeden bør automatisk løses, når indekseringen er færdig.

Note
Denne fejl betyder ikke, at Copilot ikke er tilgængelig for brugerne. Denne besked indikerer, at nye instansværdier, der tilføjes eller ændres i modellen, måske ikke afspejles i Copilot-svar, før indekseringsaktiviteten er afsluttet.
Indekseringsmetode
Tekstkolonner i den semantiske model er de eneste kolonner, der indekseres. Kolonner, der er skjult i AI-skemaet via funktionen Forbered dine data til AI , indekseres ikke.
Op til fem millioner instansværdier er indekseret med kolonner. Den mindste kardinalitet indekseres først. bestemmer kolonnens kardinalitet for importmodeller og bestemmer kolonnens kardinalitet for DirectQuery-modeller. For DirectQuery-kilder bruger funktionen funktionen til underliggende datakilder, der understøtter den, for effektivt at bestemme omtrentlige kolonnekardinaliteter.
For yderligere at forhindre overbelastning af det underliggende system for DirectQuery-modeller med en tilstrømning af forespørgsler på grund af indeksering, caches resultaterne af i cache. Statistikkerne genberegnes hver syvende dag. Hvis den øvre grænse på fem millioner forekomster under indekseringsprocessen vil blive krydset med indekseringen af den næste kolonne, springes indekseringen af kolonnen helt over.
Hvis indekseringsgrænsen nås, svarer Copilot stadig baseret på det indeks, de har bygget, som ikke inkluderer alle instansværdier. Brugerne får vist følgende advarsel, når den pågældende semantiske model når indekseringsgrænsen.

Kendte begrænsninger
- Indeksering har en øvre grænse på fem millioner forekomstværdier eller 1.000 modelobjekter (tabeller/kolonner) for store semantiske modeller.
- Tekstværdier på mere end 100 tegn indekseres ikke.
- DirectQuery-modeller indekserer kun kolonner for datakilder, der understøtter .
- Indeksering for DirectQuery- og Direct Lake-modeller sker én gang i løbet af en 24-timers periode, medmindre modellen genudgives.
- Hvis den underliggende semantiske modelopdatering fejler, kan dataindekset være forældet indtil den næste vellykkede semantiske modelopdatering.
- Den første generering af dataindeks for den semantiske model kan forsinkes med 15 minutter for at give backend-aktiviteter mulighed for at generere indekset.