Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Microsoft Fabric er en alt i en-analyseløsning til virksomheder, der dækker alt fra dataflytning til datavidenskab, analyse i realtid og business intelligence. Det tilbyder en omfattende pakke af tjenester, herunder data lake, data engineering og dataintegration, alt sammen på ét sted. Du kan få flere oplysninger under Hvad er Microsoft Fabric?
I dette selvstudium gennemgås et scenarie fra ende til anden fra dataanskaffelse til dataforbrug. Det hjælper dig med at opbygge en grundlæggende forståelse af Fabric, herunder de forskellige oplevelser, og hvordan de integreres, samt de professionelle og borgerudviklende oplevelser, der følger med arbejdet på denne platform. Dette selvstudium er ikke beregnet til at være en referencearkitektur, en udtømmende liste over funktioner og funktionalitet eller en anbefaling af specifikke bedste fremgangsmåder.
Lakehouse-scenarie fra ende til anden
Organisationer har traditionelt bygget moderne data warehouses til deres transaktions- og strukturerede dataanalysebehov. Og data lakehouses til big data (halv/ustruktureret) dataanalysebehov. Disse to systemer kørte parallelt, hvilket skabte siloer, duplikering af data og øgede samlede ejeromkostninger.
Fabric med sin samling af datalager og standardisering på Delta Lake-formatet giver dig mulighed for at eliminere siloer, fjerne duplikering af data og drastisk reducere de samlede ejeromkostninger.
Med den fleksibilitet, der tilbydes af Fabric, kan du implementere enten lakehouse- eller data warehouse-arkitekturer eller kombinere dem sammen for at få det bedste ud af begge dele med enkel implementering. I dette selvstudium skal du tage et eksempel på en detailhandelsorganisation og bygge dens lakehouse fra start til slut. Den bruger medaljonsarkitekturen , hvor bronzelaget har rådata, sølvlaget har de validerede og deduplikerede data, og guldlaget har meget raffinerede data. Du kan bruge den samme fremgangsmåde til at implementere et lakehouse for enhver organisation fra en hvilken som helst branche.
I dette selvstudium forklares det, hvordan en udvikler hos den fiktive virksomhed Wide World Importers fra detaildomænet fuldfører følgende trin:
Log på din Power BI-konto, og tilmeld dig den gratis prøveversion af Microsoft Fabric. Hvis du ikke har en Power BI-licens, tilmelde dig en gratis Fabric-licens og derefter kan du starte Fabric-prøveversionen.
Byg og implementer et end-to-end-lakehouse for din organisation:
- Opret et Fabric-arbejdsområde.
- Opret et lakehouse.
- Indfødning af data, transformér data, og indlæs dem i lakehouse. Du kan også udforske OneLake, én kopi af dine data på tværs af lakehouse-tilstand og SQL Analytics-slutpunktstilstand.
- Forbind til dit lakehouse ved hjælp af SQL-analyse-endpointet og opret en semantisk model og opbyg en rapport til at analysere salgsdata på tværs af forskellige dimensioner.
- Du kan eventuelt organisere og planlægge dataindtagelses- og transformationsflow med en pipeline. Pipelines inkluderer Lakehouse-fokuserede aktiviteter såsom Lakehouse Maintenance-aktiviteten (for at automatisere vedligeholdelse af Delta-tabellen med OPTIMIZE og VACUUM) og aktiviteten Refresh SQL Endpoint (for at holde SQL-analyse-endpointet synkroniseret efter dataindlæsning). Pipeline-udtryksbyggeren inkluderer også Copilot-assistance for hurtigere og mere præcis formuleringsskrivning. For detaljer, se Lakehouse Maintenance-aktiviteten.
Ryd op i ressourcer ved at slette arbejdsområdet og andre elementer.
Arkitektur
På følgende billede vises lakehouse-arkitekturen fra ende til anden. De involverede komponenter er beskrevet på følgende liste.

Datakilder: Fabric gør det hurtigt og nemt at oprette forbindelse til Azure Data Services samt andre cloudbaserede platforme og datakilder i det lokale miljø til strømlinet dataindtagelse.
Indtagelse: Du kan hurtigt oprette indsigt til din organisation ved hjælp af mere end 200 oprindelige connectors. Disse connectors er integreret i Fabric-pipelinen og bruger den brugervenlige træk og slip-datatransformation med dataflow. Med genvejsfunktionen i Fabric kan du desuden oprette forbindelse til eksisterende data uden at skulle kopiere eller flytte dem. OneLake-genveje kan også referere til dataprodukter på tværs af lejere via OneLake ekstern datadeling, hvilket giver dig adgang til live, styret driftsdata uden at kopiere eller bygge ETL-pipelines. Fabric inkluderer også højtydende, vektoriserede fillæsere til almindelige formater som CSV (med JSON-understøttelse på vej) for at reducere indtastningslatens.
Transformér og gem: Fabric standardiserer delta lake-formatet. Det betyder, at alle Fabric-programmerne kan få adgang til og manipulere det samme datasæt, der er gemt i OneLake, uden at duplikere data. OneLakes samlede styringsmodel sikrer, at data, der tilgås via genveje, deltager i de samme sikkerheds- og compliance-politikker som lokalt gemte data, hvilket giver en enkelt version af sandheden på tværs af organisationen. Dette lagersystem giver fleksibiliteten til at bygge lakehouses ved hjælp af en medaljonsarkitektur eller et datanet, afhængigt af dit organisatoriske krav. Du kan vælge mellem en oplevelse med lav kode eller ingen kode i forbindelse med datatransformation ved hjælp af enten pipelines/dataflow eller notesbog/Spark for at få en kode første oplevelse. Lakehouse-tabeller understøtter også performanceoptimeringer såsom Z-ordering og Liquid Clustering for at forbedre forespørgselsydelsen og styre datalayoutet i stor skala. Derudover er Materialized Lake Views tilgængelige til at forudberegne og cache resultater over lakehouse-data, hvilket fremskynder gentagne analyser. Operationalisering kan inkludere automatiseret vedligeholdelse af Lakehouse Delta-tabeller via Lakehouse Maintenance-aktiviteten i pipelines og udløsning af en SQL-analyseopdatering af endpointet som en del af efterload-trin – se det valgfrie pipeline-orkestreringstrin i scenarieoversigten ovenfor for detaljer.
Forbrug: Power BI kan bruge data fra Lakehouse til rapportering og visualisering. Hver Lakehouse har et indbygget TDS-endpoint, SQL-analyseendpointet, for nem forbindelse og forespørgsler af data i Lakehouse-tabellerne fra andre rapporteringsværktøjer. Pipeline-orkestrering kan inkludere et trin til at opdatere Lakehouse SQL-analyseendpointet for at sikre, at skema og metadata er aktuelle for rapporteringsværktøjer efter dataindlæsning—se det valgfrie pipeline-orkestreringstrin i scenarieoversigten ovenfor for detaljer.
Gennem deling af data på tværs af lejere kan rapporter, semantiske modeller og AI/data science-arbejdsbelastninger også forbruge delte OneLake-data på tværs af organisatoriske grænser, hvilket muliggør samarbejde uden dataduplikering.
Eksempeldatasæt
Denne tutorial bruger Wide World Importers (WWI) eksempeldatabasen , som du importerer til lakehouse i den næste tutorial. For lakehouse end-to-end-scenariet indeholder datasættet tilstrækkelige data til at udforske Fabric-platformens skala og ydeevne.
Wide World Importers (WWI) er en engros nyhedsvareimportør og -distributør, der opererer fra San Francisco Bay-området. Som grossist inkluderer WWI's kunder hovedsageligt virksomheder, der videresælger til enkeltpersoner. WWI sælger til detailkunder på tværs af USA herunder specialbutikker, supermarkeder, databehandlingsbutikker, turistattraktionsbutikker og nogle enkeltpersoner. WWI sælger også til andre grossister via et netværk af agenter, der markedsfører produkterne på WWI's vegne. Hvis du vil vide mere om deres virksomhedsprofil og -drift, skal du se Eksempeldatabaser til Wide World Importers for Microsoft SQL.
Generelt hentes data fra transaktionssystemer eller line of business-programmer til et lakehouse. Men for enkelhedens skyld bruger du i denne tutorial den dimensionelle model, som Første Verdenskrig leverede, som den oprindelige datakilde. Du indlæser dataene i et søhus og forvandler det gennem forskellige stadier (Bronze, Sølv og Guld) i en medaljonarkitektur.
Datamodel
Mens den dimensionelle model for Første Verdenskrig indeholder adskillige faktatabeller, bruger denne vejledning Salgs-faktatabellen og dens korrelerede dimensioner. I følgende eksempel illustreres WWI-datamodellen:

Data- og transformationsflow
Som beskrevet tidligere bruger denne vejledning eksempeldata fra Wide World Importers (WWI) eksempeldata til at bygge et end-to-end søhus. I denne implementering gemmes eksempeldataene på en Azure Data Storage-konto i Parquet-filformatet for alle tabellerne. Men i scenarier i den virkelige verden stammer data typisk fra forskellige kilder og i forskellige formater.
Følgende billede viser kilde-, destinations- og datatransformationen:

Datakilde: Kildedataene er i parquetfilformat og i en ikke-partitioneret struktur. Den gemmes i en mappe for hver tabel. I denne vejledning opsætter du en pipeline til at indlæse de komplette historiske eller engangsdata til søhuset.
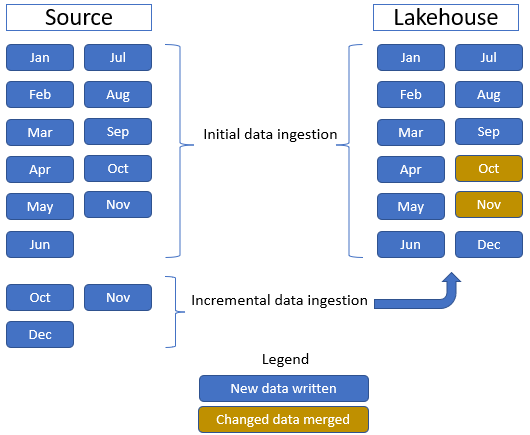
I denne vejledning bruger du Salgsfaktatabellen , som har én overordnet mappe med historiske data for 11 måneder (med én undermappe for hver måned) og en anden mappe med inkrementelle data for tre måneder (én undermappe for hver måned). Under den indledende dataindtagelse indtages 11 måneders data i lakehouse-tabellen. Når de inkrementelle data ankommer, slås de opdaterede oktober- og novemberdata sammen med de eksisterende data, og de nye decemberdata skrives til lakehouse-tabellen som vist på følgende billede:
Lakehouse: I dette selvstudium opretter du et lakehouse, henter data i filafsnittet i lakehouse og opretter derefter delta lake-tabeller i afsnittet Tabeller i lakehouse.
Transform: For dataforberedelse og -transformation dækker denne vejledning to forskellige tilgange: notebooks og Spark for en kode-først-oplevelse, og pipelines og dataflows for en low-code eller no-code oplevelse. Den nyeste Fabric-runtime inkluderer en native eksekveringsmotor, der leverer betydelige ydelsesforbedringer i forhold til open source Spark til notebook- og Spark-jobarbejdsbelastninger. Pipeline-udtryksbyggeren inkluderer Copilot-hjælp til at hjælpe med at udarbejde udtryk og opbygge pipeline-logik for hurtigere og mere præcis generering af udtryk.
Forbrug: Power BI kan forbruge data fra lakehouse til rapportering og visualisering. Hver lakehouse har et indbygget TDS-endpoint kaldet SQL analytics endpoint for nem forbindelse og forespørgsler af data i lakehouse-tabellerne fra andre rapporteringsværktøjer. Du kan også bruge Direct Lake over OneLake til at lade Power BI forespørge lakehouse-tabeller direkte uden import eller en dedikeret semantisk modelopdateringscyklus. Derudover kan du gøre dine data tilgængelige for ikke-Microsoft rapporteringsværktøjer ved at bruge TDS/SQL-analyse-endpointet til at forbinde og køre SQL-forespørgsler til analyse.
For Spark SQL-arbejdsbelastninger specifikt kan ODBC-kompatible klienter forbinde via Microsoft ODBC-driver til Microsoft Fabric Data Engineering (Preview) med Microsoft Entra ID autentificering (interaktiv, Azure CLI, service principal, certifikat- eller adgangstok).
