Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Brugerdefinerede grafer i Microsoft Sentinel gøre det muligt for sikkerhedsforskere og -analytikere at oprette skræddersyede grafpræsentationer af deres sikkerhedsdata. Ved at oprette brugerdefinerede grafer kan du modellere specifikke angrebsmønstre, undersøge trusler og køre avancerede grafalgoritmer for at afdække skjulte relationer i dit digitale miljø. I denne vejledning gennemgår vi, hvordan du opretter og administrerer brugerdefinerede grafer ved hjælp af Jupyter-notesbøger i udvidelsen Microsoft Sentinel Visual Studio Code.
I denne artikel fokuseres der på manuel oprettelse af brugerdefinerede grafer ved hjælp af kode. Hvis du vil have en AI-drevet oplevelse, skal du se Ai-assisteret brugerdefineret grafredigering i Microsoft Sentinel.
Forudsætninger
Følgende er påkrævet for at oprette brugerdefinerede grafer i Microsoft Sentinel:
- Microsoft Sentinel udvidelse til Visual Studio Code. Du kan få flere oplysninger under Kør notesbøger på datasøen Microsoft Sentinel.
- Jupyter udvidelse til Visual Studio Code.
- Microsoft Sentinel datasø, der er konfigureret med de relevante tilladelser. Du kan få flere oplysninger under Onboard to Microsoft Sentinel data lake.
Aktivér den Microsoft Entra ID connector til at indtage de Microsoft Entra aktivtabeller, der bruges i denne artikels eksempelkode. Du kan få flere oplysninger under Dataindtagelse af aktivdata i datasøen Microsoft Sentinel.
Tilladelser
Hvis du vil interagere med brugerdefinerede grafer, skal du bruge følgende XDR-tilladelser i Sentinel datasø. I følgende tabel vises tilladelseskravene til almindelige grafhandlinger:
| Grafhandling | Påkrævede tilladelser |
|---|---|
| Udform og byg en notesboggraf | Brug en brugerdefineret Microsoft Defender XDR unified RBAC-rolle med datatilladelser (administrer) til Microsoft Sentinel dataindsamling. |
| Fastgør en graf i lejer | Brug en af følgende Microsoft Entra ID roller: Sikkerhedsoperator Sikkerhedsadministrator Global administrator |
| Forespørg på en permanent graf | Brug en brugerdefineret Microsoft Defender XDR unified RBAC-rolle med grundlæggende sikkerhedsdatatilladelser (læs) for Microsoft Sentinel dataindsamling. |
Vigtigt!
Du skal have tilladelse til at læse de data, der bruges i grafen. Hvis du ikke har adgang til et bestemt datasæt, medtages disse data ikke i grafen. Hvis du vil oprette en graf, må du ikke være begrænset af et Sentinel område. En beregnet bruger kan ikke oprette en brugerdefineret graf.
Microsoft Entra ID roller giver bred adgang på tværs af alle arbejdsområder i datasøen. Du kan få flere oplysninger under Roller og tilladelser i Microsoft Sentinel.
Installér Visual Studio Code og udvidelsen Microsoft Sentinel
Opret brugerdefinerede grafer ved hjælp af Jupyter-notesbøger i udvidelsen Microsoft Sentinel Visual Studio Code. Du kan få flere oplysninger under Installér Visual Studio Code og udvidelsen Microsoft Sentinel
Opret en brugerdefineret graf
Hvis du vil oprette og arbejde med brugerdefinerede grafer, skal du udføre følgende trin:
- Modelér en brugerdefineret graf
- Gør den brugerdefinerede graf permanent ved at planlægge et grafjob
- Få vist og administrer brugerdefinerede grafer
Modelér en brugerdefineret graf
Opret en brugerdefineret graf ved hjælp af en Jupyter-notesbog i udvidelsen Microsoft Sentinel Visual Studio Code.
Følgende trin fører dig gennem oprettelsen af din første brugerdefinerede graf ved hjælp af en eksempelnotesbog.
Konfigurer din notesbog, og opret forbindelse til datasøen
I Visual Studio Code hvor udvidelsen Microsoft Sentinel er installeret, skal du vælge ikonet Microsoft Sentinel i menuen til venstre.
Vælg Log på for at få vist grafer
Der vises en dialogboks med teksten Filtypenavnet 'Microsoft Sentinel' vil logge på med Microsoft. Vælg Tillad at logge på.
Log på med dine legitimationsoplysninger.
Når du har logget på, skal du vælge + opret ny notesbog.
Navngiv notesbogfilen, og gem den på en passende placering i arbejdsområdet.

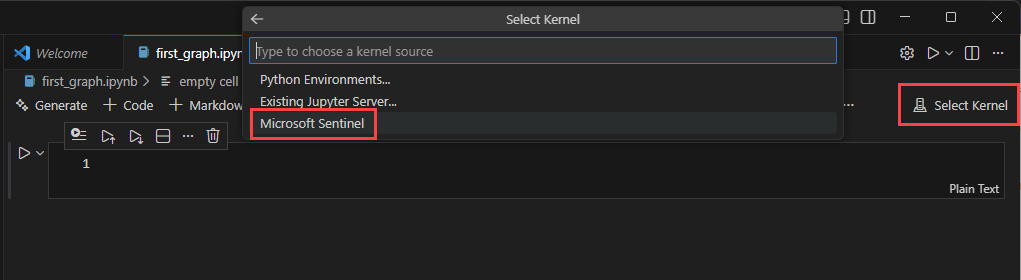
Vælg Vælg kerne øverst til højre i notesbogvinduet for at vælge en spark-beregningspulje.
Vælg Microsoft Sentinel, og vælg derefter en af de tilgængelige spark-puljer.
Tip
Du kan bruge AI-prompts til at hjælpe dig med at oprette en brugerdefineret grafnotesbog. Du kan få flere oplysninger under Ai-assisteret oprettelse af brugerdefinerede grafer i Microsoft Sentinel.
Kør en celle til ved at vælge trekantikonet for kørselscelle til venstre for cellen. Første gang du kører en celle, bliver du muligvis bedt om at vælge en kerne, hvis du ikke allerede har valgt en.
Første gang du kører en celle, tager det ca. fem minutter at starte Spark-sessionen.




Opret en graf
I følgende eksempel oprettes en graf, hvor du kan gennemgå Microsoft Entra gruppemedlemskaber og forstå indlejrede grupperelationer. Eksempelkoden hjælper dig med at komme i gang med en enkel use case for at få mere at vide om den brugerdefinerede graffunktionalitet og udnytte fordelen ved at gennemgå grafer i dine undersøgelser. Du kan oprette en graf ud fra en hvilken som helst tabel, der er tilgængelig i Sentinel datasø.
Opret forbindelse til dit arbejdsområde, og læs Entra tabeller over aktiver for at begynde at oprette grafen.
from pyspark.sql import functions as F from sentinel_lake.providers import MicrosoftSentinelProvider lake_provider = MicrosoftSentinelProvider(spark=spark) # Use the "System tables" workspace which contains the Entra* Assets tables # If you are data is in a different workspace, update this variable accordingly and ensure the tables are present LOG_ANALYTICS_WORKSPACE = "System tables" # Dynamically get the latest snapshot time from EntraUsers snapshot_time = ( lake_provider.read_table("EntraUsers", LOG_ANALYTICS_WORKSPACE) .df.agg(F.max("_SnapshotTime").alias("max_snapshot")) .collect()[0]["max_snapshot"] .strftime("%Y-%m-%dT%H:%M:%SZ") ) print(f"Using snapshot_time: {snapshot_time}") snapshot_filter = (F.col("_SnapshotTime") == F.lit(snapshot_time).cast("timestamp")) # Load EntraMembers - edges: group contains user/group/servicePrincipal df_members = ( lake_provider.read_table("EntraMembers", LOG_ANALYTICS_WORKSPACE) .filter( snapshot_filter & (F.col("sourceType") == "group") & (F.col("targetType").isin("user", "group", "servicePrincipal")) ) ) # Load EntraGroups - nodes df_groups = ( lake_provider.read_table("EntraGroups", LOG_ANALYTICS_WORKSPACE) .filter(snapshot_filter) .select("id", "displayName", "mailEnabled") ) # Load EntraUsers - nodes df_users = ( lake_provider.read_table("EntraUsers", LOG_ANALYTICS_WORKSPACE) .filter(snapshot_filter) .select("id", "accountEnabled", "displayName", "department", "lastPasswordChangeDateTime", "userPrincipalName", "usageLocation") ) # Load EntraServicePrincipals - nodes df_service_principals = ( lake_provider.read_table("EntraServicePrincipals", LOG_ANALYTICS_WORKSPACE) .filter(snapshot_filter) .select("accountEnabled", "id", "displayName", "servicePrincipalType", "tenantId", "organizationId") ) # Fix for Spark 3.x Parquet datetime rebase issue. Required when reading Parquet files # written by Spark 2.x which used the Julian calendar, whereas Spark 3.x uses Proleptic # Gregorian. Without these settings, timestamp columns (e.g. lastPasswordChangeDateTime) # may throw errors or return incorrect values. Safe to remove if all data was written by # Spark 3.x (typical for current Fabric/Sentinel environments). spark.conf.set("spark.sql.parquet.datetimeRebaseModeInRead", "CORRECTED") spark.conf.set("spark.sql.parquet.datetimeRebaseModeInWrite", "CORRECTED") spark.conf.set("spark.sql.parquet.int96RebaseModeInRead", "CORRECTED") spark.conf.set("spark.sql.parquet.int96RebaseModeInWrite", "CORRECTED")Forbered noden og Edge DataFrames, der kræves til oprettelse af grafen
# ============================================================ # NODE PREPARATION # ============================================================ # EntraUser nodes - keyed by user id user_nodes = ( df_users.df .select( F.col("id"), F.col("displayName"), F.col("accountEnabled"), F.col("department"), F.col("lastPasswordChangeDateTime"), F.col("userPrincipalName"), F.col("usageLocation") ) ) # EntraGroup nodes - keyed by group id group_nodes = ( df_groups.df .select( F.col("id"), F.col("displayName"), F.col("mailEnabled") ) ) # EntraServicePrincipal nodes - keyed by SP id sp_nodes = ( df_service_principals.df .select( F.col("id"), F.col("displayName"), F.col("accountEnabled"), F.col("servicePrincipalType"), F.col("tenantId"), F.col("organizationId") ) ) # ============================================================ # EDGE PREPARATION # ============================================================ # Edge: EntraGroup --Contains--> EntraUser edge_group_contains_user = ( df_members.df .filter(F.col("targetType") == "user") .select( F.col("sourceId").alias("SourceGroupId"), F.col("targetId").alias("TargetUserId") ) .distinct() .withColumn("EdgeKey", F.concat_ws("_", F.col("SourceGroupId"), F.col("TargetUserId"))) ) # Edge: EntraGroup --Contains--> EntraGroup (nested groups) edge_group_contains_group = ( df_members.df .filter(F.col("targetType") == "group") .select( F.col("sourceId").alias("SourceGroupId"), F.col("targetId").alias("TargetGroupId") ) .distinct() .withColumn("EdgeKey", F.concat_ws("_", F.col("SourceGroupId"), F.col("TargetGroupId"))) ) # Edge: EntraGroup --Contains--> EntraServicePrincipal edge_group_contains_sp = ( df_members.df .filter(F.col("targetType") == "servicePrincipal") .select( F.col("sourceId").alias("SourceGroupId"), F.col("targetId").alias("TargetSPId") ) .distinct() .withColumn("EdgeKey", F.concat_ws("_", F.col("SourceGroupId"), F.col("TargetSPId"))) )Definer dit grafskema, og bind til de DataFrames, der blev oprettet i det forrige trin
from sentinel_graph import GraphSpecBuilder, Graph # Define the graph schema entra_group_graph_spec = ( GraphSpecBuilder.start() # === NODES === .add_node("EntraUser") .from_dataframe(user_nodes) # Native Spark DataFrame (from .df + .select + .distinct) .with_columns( "id", "displayName", "accountEnabled", "department", "lastPasswordChangeDateTime", "userPrincipalName", "usageLocation", key="id", display="displayName" ) .add_node("EntraGroup") .from_dataframe(group_nodes) # Native Spark DataFrame .with_columns( "id", "displayName", "mailEnabled", key="id", display="displayName" ) .add_node("EntraServicePrincipal") .from_dataframe(sp_nodes) # Native Spark DataFrame .with_columns( "id", "displayName", "accountEnabled", "servicePrincipalType", "tenantId", "organizationId", key="id", display="displayName" ) # === EDGES === # EntraGroup --ContainsUser--> EntraUser .add_edge("ContainsUser") .from_dataframe(edge_group_contains_user) # Native Spark DataFrame .source(id_column="SourceGroupId", node_type="EntraGroup") .target(id_column="TargetUserId", node_type="EntraUser") .with_columns("SourceGroupId", "TargetUserId", "EdgeKey", key="EdgeKey", display="EdgeKey") # EntraGroup --ContainsGroup--> EntraGroup (nested groups) .add_edge("ContainsGroup") .from_dataframe(edge_group_contains_group) # Native Spark DataFrame .source(id_column="SourceGroupId", node_type="EntraGroup") .target(id_column="TargetGroupId", node_type="EntraGroup") .with_columns("SourceGroupId", "TargetGroupId", "EdgeKey", key="EdgeKey", display="EdgeKey") # EntraGroup --ContainsServicePrincipal--> EntraServicePrincipal .add_edge("ContainsServicePrincipal") .from_dataframe(edge_group_contains_sp) # Native Spark DataFrame .source(id_column="SourceGroupId", node_type="EntraGroup") .target(id_column="TargetSPId", node_type="EntraServicePrincipal") .with_columns("SourceGroupId", "TargetSPId", "EdgeKey", key="EdgeKey", display="EdgeKey") ).done()Valider grafskemaet
# Check the schema of the graph spec to ensure it's correct entra_group_graph_spec.show_schema()Byg grafen, herunder forberedelse af dataene og publicering af grafen
# Build the graph from the spec - this will validate the spec and prepare it for querying # Alter options is to use Graph.prepare() to prepare the graph nodes and edges in the lake # and then use Graph.publish() to create the graph. You would typically call prepare() and publish() # seperately to understand the cost of Graph API calls that are triggeterd by Graph.publish() # see https://learn.microsoft.com/azure/sentinel/billing?tabs=simplified%2Ccommitment-tiers intra_group_graph = Graph.build(entra_group_graph_spec)Bemærk!
Grafer, der oprettes under interaktive notesbogsessioner, fjernes, når notesbogsessionen lukkes. Hvis du vil bevare grafen med henblik på genbrug og deling, skal du se Vedhold din brugerdefinerede graf
Du har nu oprettet en graf i notesbogen.
Hvis du vil have vist en visuel gengivelse af grafen, skal du indsætte en ny celle og køre følgende kode:
# Query 1: Find nested group relationships nexting up to 8 levels deep
# Update the Entra Group name that you want to traverse from
query_nested_groups = """
MATCH p=(g1:EntraGroup)-[cg]->{1,8}(g2)
WHERE g1.displayName = 'tmplevel3'
RETURN *
"""
intra_group_graph.query(query_nested_groups).show()
Denne kode kører en GQL-forespørgsel (Graph Query Language) for at hente alle indlejrede gruppemedlemskaber på op til 8 niveauer dybt. Den resulterende graf visualiseres i outputtet

Vedhold din brugerdefinerede graf
Når du har oprettet grafkoden i notesbogen, kan du køre notesbogen i en interaktiv session eller planlægge et grafjob. Grafer, der oprettes under den interaktive notesbogsession, er midlertidige og er kun tilgængelige i forbindelse med notesbogsessionen. Hvis du vil gemme grafen og dele den med dit team, skal du planlægge et grafjob for at genopbygge grafen ofte. Når grafen er gemt, er den tilgængelig fra: grafoplevelsen i Microsoft Defender-portalen under Sentinel, Visual Studio Code Notesbøger og API'er til Graph-forespørgsler.
Vælg Opret planlagt job i din grafnotesbog, og vælg derefter Opret et grafjob.

I formularen Opret grafjob skal du angive navnet på grafen og beskrivelsen og kontrollere, at den korrekte grafnotesbog er inkluderet i Path.
Hvis du vil oprette grafen uden at konfigurere en tidsplan for opdatering, skal du vælge On demand i afsnittet Tidsplan og derefter vælge Send for at oprette grafen.
Bemærk!
Grafer, der er oprettet ved hjælp af en tidsplan efter behov, har standardopbevaring på 30 dage og slettes ved udløb.
Hvis du vil oprette grafen, hvor grafdataene opdateres regelmæssigt, skal du vælge Planlagt i afsnittet Tidsplan .
Vælg en gentagelsesfrekvens for jobbet. Du kan vælge mellem Efter minut, Time, Ugentligt, Dagligt eller Månedligt.
Der vises flere indstillinger for at konfigurere tidsplanen, afhængigt af den hyppighed du vælger. Det kan f.eks. være ugedag, klokkeslæt eller dag i måneden.
Vælg en Start til tiden, for at tidsplanen kan begynde at køre.
Vælg En Slutdato til tiden, for at tidsplanen ikke længere skal køre. Hvis du ikke vil angive et sluttidspunkt for tidsplanen, skal du vælge Angiv job til kørsel på ubestemt tid. Datoer og klokkeslæt er i din tidszone.
Vælg Send for at gemme jobkonfigurationen og publicere jobbet. Grafopbygningsprocessen starter i din lejer. Få vist grafen, der netop er oprettet, og dens seneste status i udvidelsen Sentinel.



Få vist og administrer brugerdefinerede grafer
Når du har oprettet et grafjob, kan du få vist og administrere grafen i din lejer fra udvidelsen Microsoft Sentinel i Visual Studio Code.
På listen over grafer skal du vælge din materialiserede graf for at få vist detaljerne.
Vælg fanen Jobdetaljer for at få vist status for grafjobbet, herunder sidste kørselstidspunkt, næste kørselstid og eventuelle fejl under oprettelsesprocessen.
Vælg Kør nu for manuelt at udløse et grafbuild uden for de planlagte tidspunkter. Status ændres til Sat i kø og derefter "I gang", mens grafen oprettes.

Når grafbuildet er fuldført, opdateres Status til Klar. Vælg fanen Grafdetaljer for at få vist oplysninger om grafen.

Du kan nu forespørge på og visualisere grafen fra grafvisualiseringen i Microsoft Sentinel på Defender-portalen. Du kan få mere at vide under Visualiser grafer i Microsoft Sentinel graph (prøveversion).

